あらゆる企業にとって重要なテーマとなりつつある「ビッグデータ解析」だが、実際にどのように取り組めばいいのか、どうすれば満足する成果が出るのかに戸惑う企業は少なくない。大きな鍵となるのが、「データ・パイプライン」だ。
成功への鍵はデータ・パイプラインの構築
 マーケティング シニアディレクター 湯本敏久氏
マーケティング シニアディレクター 湯本敏久氏ビッグデータ解析は、一部の先進企業に限らず、さまざまな業種、さまざまな規模の企業にとって、重要なテーマとなりつつある。昨今の企業は、多種多様なITを活用してビジネスを推進しており、それらから得られる膨大なデータは、ビジネスを成功に導く知の源泉であるためだ。
ところが、いざビッグデータに取り組んでみたものの、大きな成果を得られないケースが少なくない。それ以前に、どのように始めるべきか、悩んでしまう企業も多いようだ。Pentaho ‐ A Hitachi Group Company マーケティング シニアディレクター 湯本敏久氏は、その理由は「ビッグデータ解析において重視すべきはデータ自体への取り組みにある」という。
ビッグデータ解析は、従来のデータ解析と比べて、データの量もフォーマットも、求められる情報の新鮮度も大きく異なる。さらに、狭義のビッグデータとして分類される「非構造化データ」だけでなく、既存の基幹システムやデータベースから得られる「構造化データ」と組み合わせて分析することが重要だ。
各種のセンサーや基幹システムなどからデータを抽出し、取り扱いやすいように加工して統合。用途に合わせて編集したり、非構造化データと構造化データをブレンドしたりして、リアルタイム性が損なわれないように分析・活用する。そして何よりも重要な事は、前述の抽出、加工、編集等のデータ準備工程をデータ発生源から分析・活用現場までシームレスに支援する「データ・パイプライン」の構築である(図)。
データ・パイプラインは恒常的に繰り返されるデータの可視化(ダッシュボードやレポート)や統計分析(機械学習アルゴリズム)など、複数のデータソースを統合・ブレンドし、プロセスの自動化も可能なので、エンドユーザー、アナリストの要望に応じて都度、手作業でデータを収集、加工しているIT部門にとっては有効なソリューションになる。
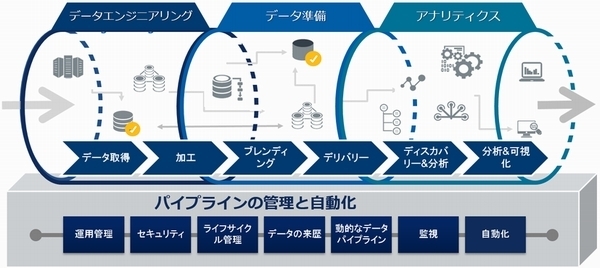 図:データ・パイプライン
図:データ・パイプラインデータ・パイプラインを構築するPentahoソフトウェア
 セールスエンジニア 門脇豪氏
セールスエンジニア 門脇豪氏Pentahoソフトウェアは、古くからすぐれたBIツールとして人気を博し、のちにデータ・インテグレーションの技術を取り入れ、データパイプライン・ソリューションへと進化を遂げた。「非構造化データをデータレイクに渡すETL処理のほか、従来のETL処理にも活用でき、両者のブレンディングでも力を発揮する」と、セールスエンジニア プリセールスの門脇豪氏は語る。
Pentahoは、高度な技術力を持たずとも、スムーズなデータ・パイプラインをデザインするための機能が盛り込まれている。例えば、ETL/ブレンド処理の開発においては、ほとんどをマウス操作で作り上げることができる。
まず、アイコン化されたデータ処理を画面上に並べてつなぎ、細かな情報を設定するだけで、データ変換処理が定義される。複数の処理をまとめれば、ジョブが完成だ。もちろんHadoopとの連携も容易で、複雑なコーディングはほとんど必要ない。
BIツールとしての能力は、すでに知られたとおりだ。従来のトラディショナルなデータ可視化・分析・レポーティングはもちろん、ビジネス・アナリティクスにも有用で、多くの機能をマウス操作だけで使いこなすことができる。ダッシュボードやアナライザーも、非常に容易に開発することができ、さまざまな要望へ迅速に対応できるのが特徴だ。
下記資料では、上述したような「分析価値を最大化するデータマッシュアップ」「ビッグデータでビジネスを成功に導くには」「Pentahoデータ統合」について、より詳細にまとめている。ビッグデータ解析に取り組む際に押さえておくべき情報が詰まっているため、ぜひ保存版としてダウンロードしていただきたい。
ホワイトペーパーをダウンロード頂けます