データに基づいて最適なアクションを起こすことは、どの企業にも共通の課題だ。しかし、いざ実践しようにも、対象とするデータは社内外に様々な形で散在し、その種類や数が激増の一途をたどっていることもあって、一筋縄にはいかない。その解決策として、シスコが提唱するのが「データ仮想化」のアプローチ。具体的ソリューションとして「データ仮想化プラットフォーム」を提供する。
テーブル間の隠れた関係性を自動分析し
データモデルを統一していく
シスコのデータ仮想化プラットフォームは、Cisco Unified Computing System(UCS)をはじめとするIAサーバ上で動作する仮想データベース環境「Cisco Information Server」を中核としたソフトウェアで、下記のオプションとともに提供される。
●開発環境
Adapters:RDBやExcelファイル、データウェアハウス、OLAPシステム、ビッグデータストア(Hadoop)、XMLドキュメント、フラットファイル、Webサービス(salesforce.com、AWS)など、多様なデータソースとの接続を行う。
Discovery、Studio:多様なデータソースから抽出されるテーブルを仮想化してビジュアライズすることで、あたかもシングルソースのように統合することができる。
●運用管理環境
Manager:統合された仮想テーブルに対するアクセスを実際のソースシステムへのクエリーに変換し、高パフォーマンスでのアクセスを可能とする。
なお、実際にデータソースにアクセスする際には、そのユーザーのIDとパスワード、IPアドレス、ポート番号などにより認証が行われる。すなわち、そのユーザーがアクセスできるデータは、あくまでもデータソースのセキュリティポリシーに基づいて設定された権限の範囲内であり、個人情報や財務情報などの機密情報が関係者外に漏えいしてしまう心配はない。
Active Cluster:スケールアウト構成でサービス展開し、高い可用性を実現する。
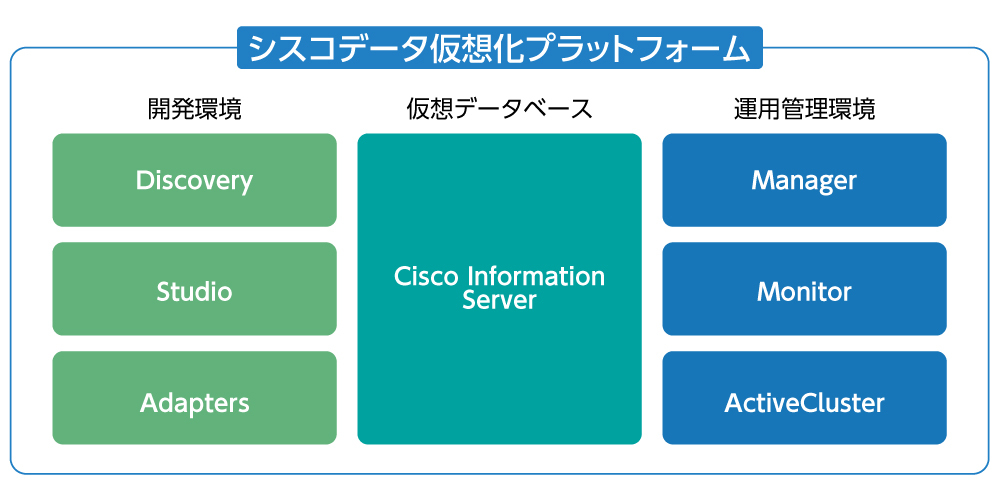 図2 「データ仮想化プラットフォーム」の主な構成要素
図2 「データ仮想化プラットフォーム」の主な構成要素拡大画像表示
もっとも、異なるデータソースからテーブルを持ってくるだけでは横断的な活用・分析はできない。それぞれのデータテーブルの関係性を明らかにして連携させる必要がある。このために横断的なデータモデルを作成しなければならない。この役割を担っているのが、先に挙げたDiscovery機能なのだ。読み込んだ複数のデータソースのテーブルを自動的に分析し、テーブル間の隠れた関連性の発見、個々のビューのモデル化、ビューの検証といったステップを通じて、データ統合を進めていく。
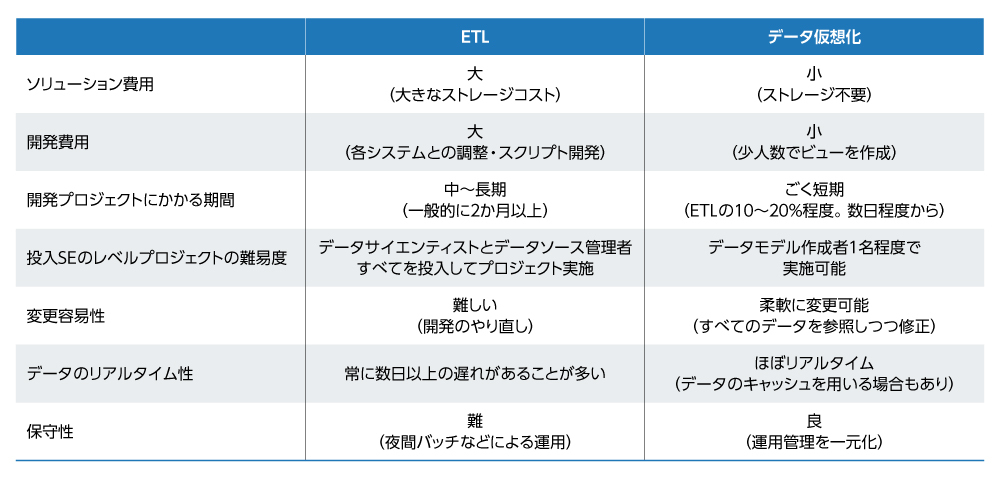 図3 従来のETLとデータ仮想化の比較
図3 従来のETLとデータ仮想化の比較拡大画像表示
「Discovery機能を使って分析を重ねるほど、その履歴が共通のリポジトリに蓄積されていきます。結果として、多様なデータソースに対するデータモデルが精査され、バラバラだったものが統一されていきます」と久松氏は強調する。
既存のデータウェアハウスからのストレージオフロード、ビジネスインテリジェンス(BI)環境における最新データでの高頻度の分析、複雑だった分析プロセスの簡略化など数々のメリットが、このデータ仮想化ソリューションからもたらされるのである。
●シスコ データ仮想化担当
E-Mail: japan-dv-solution@external.cisco.com
「データ仮想化ソリューション」の詳細ページはこちら



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
