データマネジメントは手間と時間のかかる取り組みだ。2025年3月7日に開催された「データマネジメント2025」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)のセッションに、ROBONの武田航氏が登壇し、メタデータ管理の自動化やWeb APIの自動生成などによって、既存システムをそのまま活用しながら、データ活用やDXを進めていくアプローチを紹介した。
提供:株式会社ROBON
データ活用基盤の導入・運用で課題になりやすい「体制」と「手法」
2019年に日本で創業し、税務向け生成AIサービス「税務ロボット」やデータマネジメントサービス「Data Fabric」シリーズを展開するROBON。社名は「すべての業務にロボットをオン(実装する)」に由来し、経営理念として「IT技術で全てのお客様の生産性を飛躍的に向上させる」を掲げる。
Data Fabricシリーズとして展開するのは、メタデータ管理サービス「Mashu」とWeb API自動生成サービス「Veleta」だ。ROBONのData Fabric事業部 営業部 部長 の武田航氏はまず、データ活用における「体制」のあり方について、こう述べた。
「データ活用基盤の導入が決まって、その運用保守を担うチームができても、推進する体制が十分とは言えないことが多いです。例えば、データマネジメントを統括する部門や担当者がいない、データ活用を支援するチームは文書の提供だけでとどまってしまう、データを提供するチームも何をしてよいかわからず、データサイエンティストも困ってしまうなどの問題があります」(武田氏)。
その結果、目標もはっきり定まらず、取り組みもうまく進まず、データ活用のプロジェクト自体が停滞することも多いという。
 ROBON Data Fabric事業部 営業部 部長の武田航氏
ROBON Data Fabric事業部 営業部 部長の武田航氏また、データマネジメントについては、手法自体の課題もある。
「データマネジメントでは、テーブル仕様書をExcelで作ることに終始しがちです。何千行のレコードがあるファイルが30個もあるような状況で、それらをマネジメントすることは簡単ではありません」(武田氏)。
そうしたなか、注目できるのがデータカタログだ。データカタログは一般に、データの収集から、整形、蓄積、活用までをカバーする。しかし、本当にカバーしなければならない範囲はさらに幅広いため、データとして収集されなかったデータまで守備範囲を広げる必要がある(図1)。
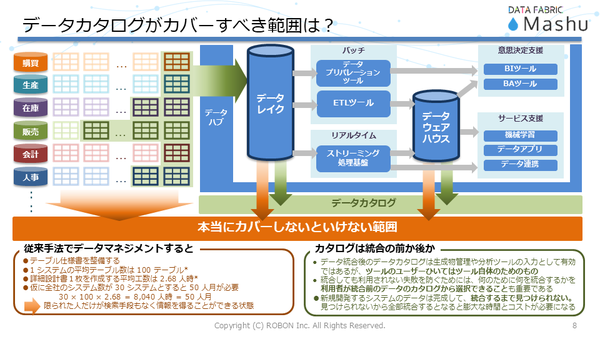 図1:データカタログがカバーすべき範囲は幅広い
図1:データカタログがカバーすべき範囲は幅広い透明度の高いデータマネジメントを実現するメタデータ管理サービス
武田氏は、データカタログの守備範囲を広げることで、正しい順番でデータマネジメントが実践できるようになると述べる。
「『うちの会社にこんなデータがある』と把握したうえで、『このデータを使ってこうした取り組みがしたい』という判断ができるようになる、これが正しいデータ活用の順番です。従来の体制や手法のなかで新規システムを構築すると、そのシステムのデータは、従来のデータカタログには載ってきません。いざ本番稼働してから『やっぱりあのデータが必要だった』ということが起こりえます。また、ECサイトの分析がしたいと思って、2年かけて共通基盤を作っても、2年後にはスマホのデータを使った分析が必要だったということもあります。その間には、テーブル仕様書を大きな手間と時間をかけて作成することになります。こうしたさまざまなズレをなくしていくことが重要です」(武田氏)。
こうしたデータマネジメントにおける課題を解消するのがメタデータ管理サービス「Mashu」だ。
Mashuは、さまざまなデータ管理システムと連携し、メタデータを抽出、同期する。抽出されたメタデータは一元管理され、全文検索によってワンストップで必要なデータを発見可能だ。さらに、メタデータにデータ情報をタグ付けすることで、関係者間での円滑な共有を実現する。こうしたデータの抽出や同期作業、タグの付与といったメタデータ管理作業を手作業で行おうとすると大変な手間と時間がかかるため、IT人材が不足する状況下では実施できないこともある。メタデータ管理を自動化することで、さまざまなデータマネジメントの課題を解消するのがMashuだ(図2)。
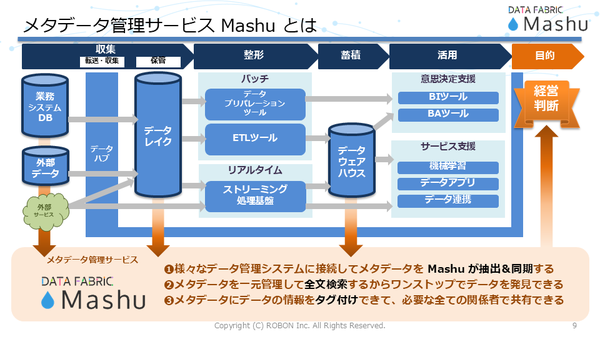 図2:メタデータ管理サービス「Mashu」
図2:メタデータ管理サービス「Mashu」Mashuは、データ管理システムに変更があっても、変更後のメタデータを吸い上げ、既存のデータとマージすることができる。また、メタデータに対するアクセス権限を管理でき、社内外とのセキュアなデータ共有を実施できる。例えば、利用者は「オーナー」「セキュリティ」「データ品質」といった独自のタグを定義し、それぞれに異なるアクセス権限を付与して、安全にデータの共有状態を管理できるようになる。
「Mashuができることを一言で表すと“全社データの索引を作る”ということです。データ活用についてはさまざまなツールがあります。われわれが訴えているのは、そうしたデータ活用の取り組みの前段階にあたるステップとして、今持っているデータを整理し、棚卸しするための索引を作りましょうということです」(武田氏)。
Mashuという名称は、北海道にある日本一透明度の高い湖である摩周湖に由来する。「透明度の高い状態で、自社データをマネジメントしていく」という思いを込めている。
データ活用とDX推進を支えるWeb API自動生成サービス「Veleta」
Mashuと並ぶもう1つのサービスである「Veleta」は、Mashuを活用してデータ活用体制を整えた後、そのデータを業務や経営に生かすためのWeb API自動生成サービスだ。武田氏は、DXを進めるうえで多くの企業は課題に直面していると指摘する。
「部門ごとに個別最適化されたシステムは、過度なカスタマイズによりブラックボックス化しがちです。真にDXを推進するためのITシステムには、リアルタイムなデータ活用、変化への迅速な対応、そして部門横断的な全社最適でのデータ活用などの要件が求められます。そうした課題を解消するのがVeletaです」(武田氏)。
例えば、Veletaでは、Web APIと併せてAPI仕様書も公開することで、そもそもどんなデータが存在するのか、リアルタイムで活用したいデータは何かを明確にし、実際にデータを利用可能にする。さらに、ITシステムを小さな単位でサービス化して、Web API連携することで、新しいビジネスや新しい顧客が現れた際に、既存のサービスを柔軟に組み替えて、適切なシステムを素早く構築できる。さらに、Web API連携によって、部門や企業の垣根を超えて、外部サービスを含めたバリューチェーンの組み換えにも対応できるようになる(図3)。
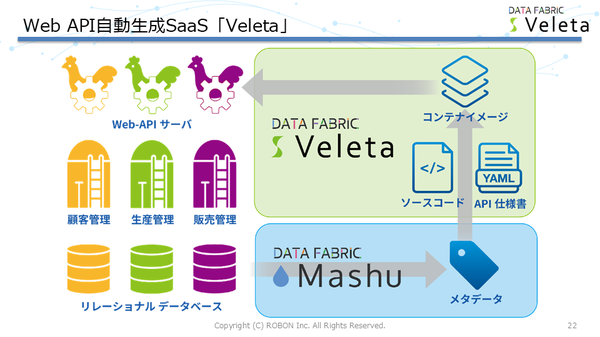 図3:Web API自動生成サービス「Veleta」
図3:Web API自動生成サービス「Veleta」MashuとVeletaを組み合わせることで「Data as a Product」を実現
MashuとVeletaを組み合わせることで、Mashuが収集したデータベースのスキーマなどのメタデータから、Web APIを自動生成することが可能となる。
「Web APIの仕様書とOpenAPIのソースコードを自動生成し、Dockerコンテナイメージとして作成します。ポイントは、稼働中のデータベースを触らずにそのまま維持できることです。生成されたコンテナをダウンロードし起動することで、Web APIサーバをすぐに動作させることができます。既存のシステムにWeb APIサーバを外付けするイメージです。既存のシステムがWeb API連携が可能なシステムに生まれ変わるという言い方もできます」(武田氏)。
なお、Veletaは、スペイン語の風見鶏という意味だ。干し草や貯蔵庫のいわゆるサイロの上に設置されることの多い風見鶏をイメージして名付けたという。
最後に武田氏は、MashuとVeletaを使った取り組みを推進することで、既存システムを生かした「Data as a Product」を実現していくことができると訴えた。
「Data as a Productは、データセットを独立した製品のように扱いやすいものとして捉えるアプローチです。具体的には、データカタログによって簡単に発見可能であり(Discoverable)、Web APIによってアクセスが可能であり(Addressable)、自動生成で実装されるため信頼性が高く(Trustworthy)、プログラムと完全に一致した仕様書を備え(Self-Describing)、標準のOpenAPI仕様に準拠することで他のデータ製品との連携も容易であり(Inter Operable)、各企業に合ったセキュリティレベルを担保(Secure)できます」(武田氏)。
●お問い合わせ先

株式会社ROBON
- 食品・消費財業界の共通課題が「店舗周りの断絶の壁」─“MDM×データサービス”が打開の鍵に(2025/08/13)
- 生成AI時代のデータ急増への“処方箋”。容量、電力効率、運用問題を抜本解消可能なストレージとは?(2025/06/09)
- 既存データから新たな示唆を得る─エンタープライズ企業の先進事例に見るAI SaaSのインパクト(2025/06/02)
- タクシーアプリ「GO」のデータ活用と、Google Cloudが目指す生成AIデータエージェントを解説(2025/05/22)
- AIに真の力を発揮させるデータ活用に不可欠な「ビジネスメタデータ」の意義と整備法(2025/05/09)

- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
