DXを推進していくにあたって、多くの企業が、システムごとに分散したデータを統合し、意思決定に資するデータを素早く収集したいと考えているが、実現のハードルは高い。課題解決のためにデータレイクやデータウェアハウス、ETL、EAIなど、様々な手段が用いられているが、どれも決定打にはなり得ていないのが現状だ。2025年3月7日に開催された「データマネジメント2025」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)のセッションに、Ridgelinezの岡本裕史氏が登壇し、データ基盤づくりを“小さく素早く”始めることができる「データ仮想化」について紹介した。
提供:Ridgelinez株式会社
データの分散がビジネスの加速を阻害する
ビジネス上の意思決定においてデータ活用は不可欠であり、「業務プロセス」「データ」「データ基盤」が互いにかみ合うことが必要である。
ただし、この3つの要素が単にそろえばよいわけではない。
まず「業務プロセス」について、ビジネス環境は常に変化しているため、意思決定の方法も柔軟に適用する必要がある。次の「データ」については、業務に必要なデータの品質が信頼できるかどうかが問われる。最後に、特に重要な鍵を握るのが「データ基盤」で、意思決定に資するデータを、できる限り早く、確実に提供する役割を担う。
 Ridgelinez株式会社 Director 岡本裕史氏
Ridgelinez株式会社 Director 岡本裕史氏RidgelinezのDirectorの岡本裕史氏は、「企業の成長に伴いシステムの追加や置き換えが断続的に発生するため、データ基盤にはこれらの変化への柔軟かつ素早い対応が求められます」と説く。しかし、分散するシステム構成では、その実現のために高いハードルが立ちはだかる(図1)。
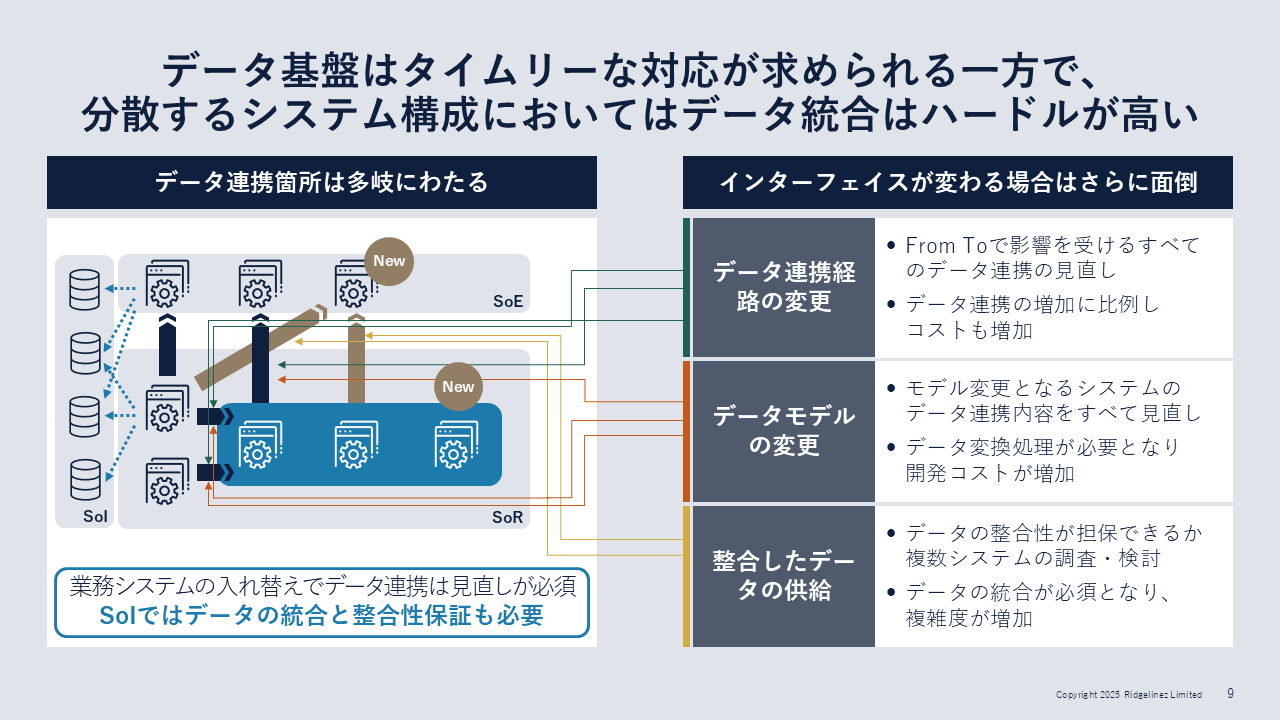
多くの企業が運用する代表的なデータ基盤の課題
データ基盤には、多様な形態がある。多くの企業で構築・運用されている代表的なデータ基盤として、岡本氏が挙げるのが次の3つの方式だ。
1つ目は、「目的に応じたシステム化」だ。データソースの追加を契機に、そのデータの活用を目的としたデータ基盤を追加する。ニーズを確実に満たすことができるが、保有データの枠を超えた活用はできない。
2つ目は、「あるものすべてをシステム化」だ。すべてのデータを一元管理するデータレイクなどの“器”を設け、データソースの追加に合わせてデータを展開する。多様なデータ活用目的をカバーすることができるが、保有データの枠を超えた活用はできない。加えてツールに精通していないとデータ活用が難しい。
3つ目は、「レポートによる自由度の最大化」だ。レポートツールを最大限に活用し、必要なデータをレポートで統合して運用する。不足するデータを自前で集めることで目的を達成できるが、ツールに精通する必要がある。また、ガバナンスが機能しなくなるリスクがある。
「このように3つの方式には、それぞれ一長一短があります(図2)。また、どの方式を選んだとしても、特に新システムの追加時にはデータを使えるようになるまで、一定のリードタイムが発生するといった問題もあります」(岡本氏)。
 図2:3種類のデータ基盤方式はどれも一長一短
図2:3種類のデータ基盤方式はどれも一長一短拡大画像表示
データ仮想化の優位性と使いどころ
企業にとっての課題は、ビジネス状況とともに変化するデータ活用のニーズに対して、データ基盤をいかに柔軟にかつ素早く刷新するかにある。具体的には、「システムの追加やニーズに短期間で対応すること」、加えて「データは意思決定に資する品質を有すること」の大きく2つの要件を満たす必要がある。
この課題解決に向けてRidgelinezが提唱するのが、データ仮想化の活用である。
データ仮想化とは、分散しているデータを論理的に統合する技術であり、データソースからの物理的なデータの物理的な集約や統合は行わないのが特徴だ。このためデータ仮想化における論理的なデータ構造の定義は大掛かりな開発が不要で、“小さく素早く”始めることに向いている。
岡本氏は、従来のテクノロジーと比較したデータ仮想化の優位性として、「データを移動する必要がないため既存のデータ基盤の再設計が不要」「意思決定における提供データの有効性をクイックに評価できる」「データを参照するビューであるため容易に変更できる」といったメリットを挙げ、「既存のデータ基盤への影響が小さいため、様々なトライアルが可能となります」と強調する。
もっとも、すべての点でデータ仮想化が優れているわけではない。履歴管理を必要とするトランザクションデータの管理や、高速クエリが必要なデータ活用要件を満たすデータの管理については、従来型のテクノロジーによるデータ基盤の方が有利だ。
「したがって、データ仮想化で新たなニーズやシステム追加に素早く対応するとともに、従来型のデータ基盤と連携しながらデータ活用のレベルアップを図っていくことが、目指すべきデータ基盤の方向性となります(図3)」(岡本氏)。
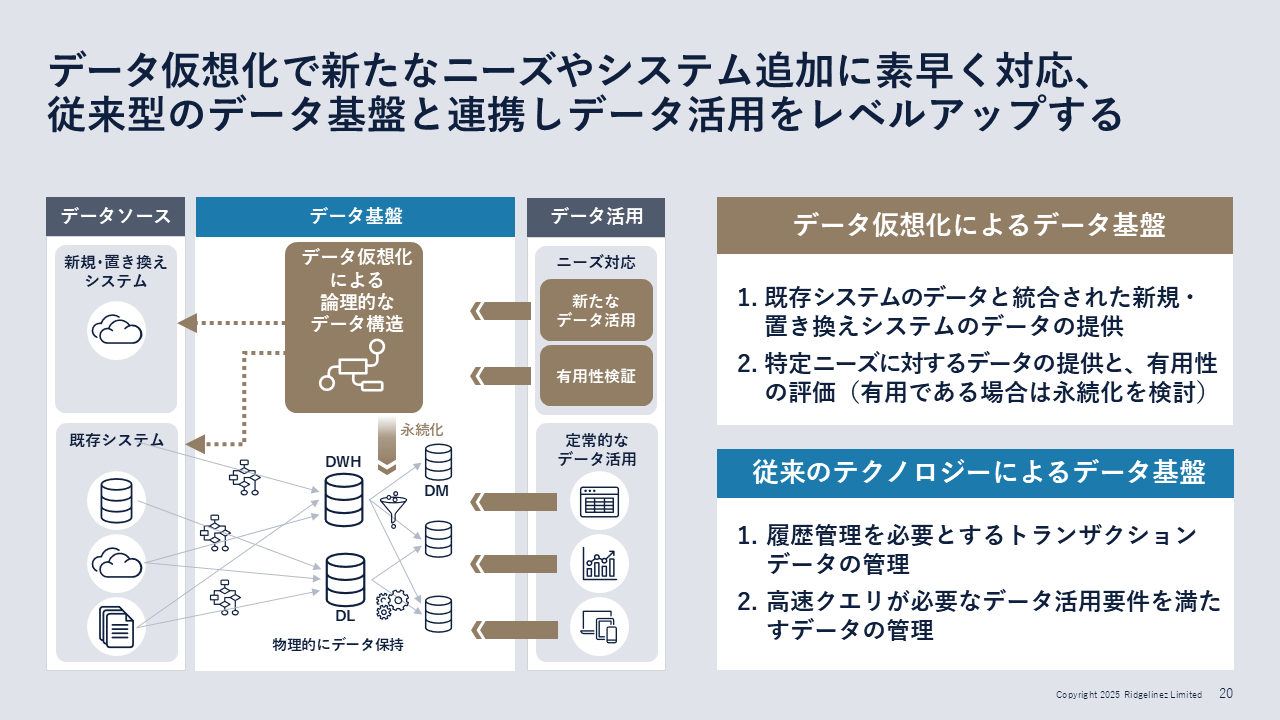 図3:目指すべきデータ基盤の方向性
図3:目指すべきデータ基盤の方向性拡大画像表示
ビジネスを加速する分散データへの取り組み
ビジネスを加速するデータ活用のためには、発想の転換も重要だ。「これまでのようにデータ蓄積を先行して後から活用方法を考えるのではなく、どのようにデータを有効活用するかを考えることから始めるべきです」と岡本氏は述べる。
具体的には、次のような手順を踏む(図4)。
ステップ1:試行錯誤によるデータ構造の組み立て
ユーザーのニーズに合わせたデータ構造を作成し、パフォーマンスとともにデータ品質を確認する。この段階ではデータは物理的に動かさず、ビューのみで進める。
ステップ2:データ活用の効果測定と調整
現場での有効性を確認し、アジャイルにフィードバックを取り入れながら改善を繰り返す。さらに、業務への適用度合いに応じた最適化を行う。
ステップ3:業務への適用度合いに応じた最適化
上記の取り組みの結果として、多くのユーザーが利用する定型レポートが“枯れた”状態となった段階で、「仮想から物理への変換」、「検証済み加工ロジックの適用」、「データ量に合わせたサイジング」といったデータ基盤の永続化を検討する。
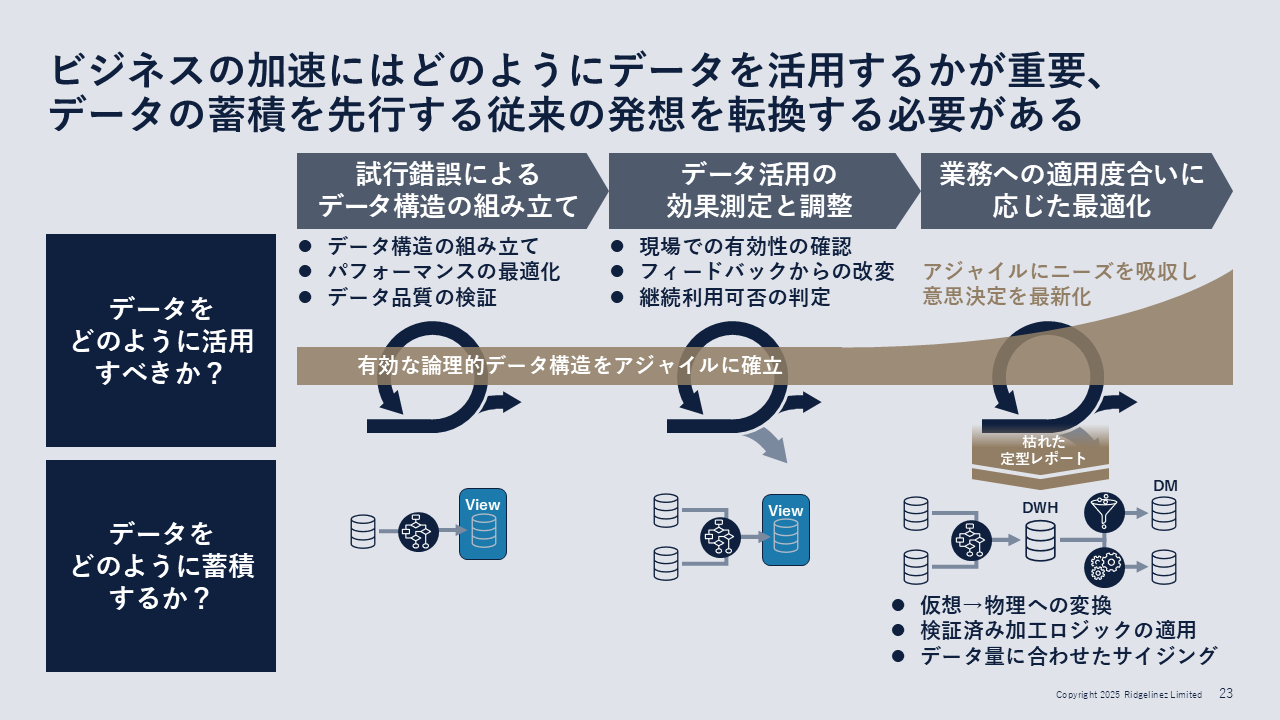 図4:データの蓄積を先行する従来の発想を転換すべき
図4:データの蓄積を先行する従来の発想を転換すべき拡大画像表示
「未来を正確に見通せる人はいないため、急速に変化していくビジネス環境の要件を事前に決めることは困難です。先ほど『データの蓄積から始めるべきではない』と述べた理由がここにあります。ならば、必要なことを必要に応じてその都度実施することで、より柔軟かつ迅速に変化に対応していくことが得策です。データ仮想化基盤は、これを実現する有効な手段となります」と、岡本氏は改めて強調する。
加えて述べるならば、仮想データ基盤を活用した新たなニーズやシステム追加の対応は内製で取り組み、最終的なシステム化(永続化)はベンダーに任せるといった適切な役割分担を行うことで、分散データを扱う理想的なデータ基盤の運用が可能となる。
分散データの壁を超えるデータ基盤は、できるだけ“小さく素早く”始めることで、最適解を求め続けなければならない。データ仮想化の導入によりデータ提供のハードルを下げ、内製化によりアジャイルに実践し、意思決定に資するデータを素早く提供することで、ビジネス環境の変化に打ち勝つことができるだろう。

●お問い合わせ先
Ridgelinez株式会社
https://www.ridgelinez.com/
https://www.ridgelinez.com/contact/form/service/
https://www.ridgelinez.com/technology-excellence/
- 食品・消費財業界の共通課題が「店舗周りの断絶の壁」─“MDM×データサービス”が打開の鍵に(2025/08/13)
- 生成AI時代のデータ急増への“処方箋”。容量、電力効率、運用問題を抜本解消可能なストレージとは?(2025/06/09)
- 既存データから新たな示唆を得る─エンタープライズ企業の先進事例に見るAI SaaSのインパクト(2025/06/02)
- タクシーアプリ「GO」のデータ活用と、Google Cloudが目指す生成AIデータエージェントを解説(2025/05/22)
- AIに真の力を発揮させるデータ活用に不可欠な「ビジネスメタデータ」の意義と整備法(2025/05/09)
Ridgelinez / データ仮想化 / データ活用基盤


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
