生成AIを業務で活用する動きが進んでいる。2025年3月7日に開催された「データマネジメント2025」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)のセッションに、セゾンテクノロジーの山本進之介氏が登壇。「生成AIとデータカタログで実現する、柔軟かつ変化に強いデータ分析基盤」と題して、データから価値を引き出す3つのポイントと、生成AIとデータカタログを活用したデータ活用のあり方を解説した。
提供:株式会社セゾンテクノロジー
データ活用で重要になる「クイックな疎結合」「社内データ活用」「インサイト創出」
データは重要な経営資源でありDX推進や生成AI活用でも欠かせない要素だ。しかし、データからどう価値を引き出せばよいのか、データをAI活用に生かしたいがうまくいかないといった課題は常にある。そんななか、セゾンテクノロジーの山本進之介氏は次のように訴える。
「データ活用のポイントは3つあると考えています。『クイックな疎結合』『インサイト創出』『社内データ活用』です。この3つの取り組みを進めるうえで重要な役割を果たすのが生成AIです。生成AIでクイックにインサイトを得たり、データカタログでメタデータを整備したりすることが重要です」(山本氏)。
 写真1:セゾンテクノロジー 営業本部 データインテグレーション営業統括部 DIセールスエンジニアリング部(肩書は登壇当時)セールスエンジニア 山本進之介氏
写真1:セゾンテクノロジー 営業本部 データインテグレーション営業統括部 DIセールスエンジニアリング部(肩書は登壇当時)セールスエンジニア 山本進之介氏クイックな疎結合とは、企業が利用する複数のSaaSサービスとデータをサービスごとに使い分けるのではなく、iPaaS(Integration Platform as a Service)を経由してゆるやかに統合し複数のサービスでデータを連携するものだ。
「システム同士が疎結合なので、連携しているSaaSが必要なくなったら別のSaaSに切り替えたり、部署や部門ごとに用途は同じでも異なるSaaSを使い分けたりできます。生成AIもiPaaSとつながることでさまざまなシステムが持つデータを簡単に活用できます(図1)」(山本氏)。
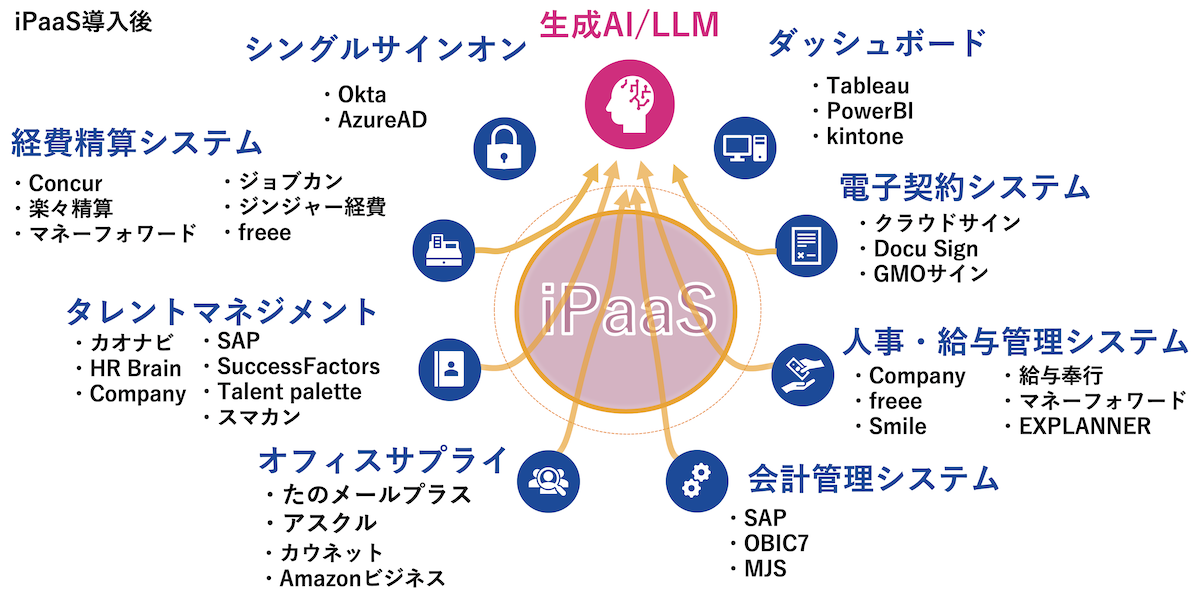 図1:iPaaS、生成AI/LLMを導入したクイックな疎結合
図1:iPaaS、生成AI/LLMを導入したクイックな疎結合拡大画像表示
社内データ活用は、オンプレミスに存在している既存システムのデータを中心にしたデータ活用だ。近年はデータレイクなどのようにクラウド側にデータ基盤を設置することが多いが、資産として価値を生む源泉となるデータの多くはオンプレミス側にある。
「モダンデータスタックと呼ばれるクラウドのデータと、資産であるオンプレミスのデータには距離感があります。この境界線をいかにして越えていくかを考えていく必要があります」(山本氏)。
インサイト創出とは、データサイエンティストを中心に行なっていたこれまでのデータ分析と、データやAIの民主化によってエンドユーザーが行うようになった新しいデータ分析のあり方が二極化しつつあるなかで、どうインサイトを得ていくかということだ。
「分析ニーズが高まり、データサイエンティストの負担が増えています。一方で、現場のユーザー層によるデータ活用の取り組みも増え続けています」(山本氏)。
商品マスターに関連がなくても、生成AIが自動で分析軸を生成し売り上げを分析できる
では、生成AIを活用すると、こうした3つの取り組みはどう変わるのか。山本氏は、売り上げ分析のユースケースで解説した。具体的には、食品製造業や小売業などにおける商品データを動的に分析する際に生成AIを活用するシナリオとなる。
「例えば、バター味のビスケットの売り上げがある月に落ちていたとします。理由を探るために同じ味の別パッケージの売り上げを調べたところ、その商品の売り上げは伸びていました。そこで、その2つを含めてグループ全体をまとめて見てみたところ、売り上げはいつも通りでした。このように1つの味でも分析するまとめ方や角度はさまざまです。パッケージが違っても商品が同じなら1つのグループにしたい場合もあれば、同じ商品でも違う製造工場の場合は別のグループにしたい場合もあります。どのような軸でまとめたいかはそのときどきで変わりますが、その都度商品マスターに分析軸を設定することは現実的ではありません。そこで活用できるのが生成AIです」(山本氏)。
生成AIを使うと、商品名や商品説明などの分析マスターのデータからグループ割当を自動で行うことができる。このグループ割当と商品マスターと突き合わせることで、見たいときに見たい軸での分析が可能になる。さらに細かい分析も可能になる(図2)。
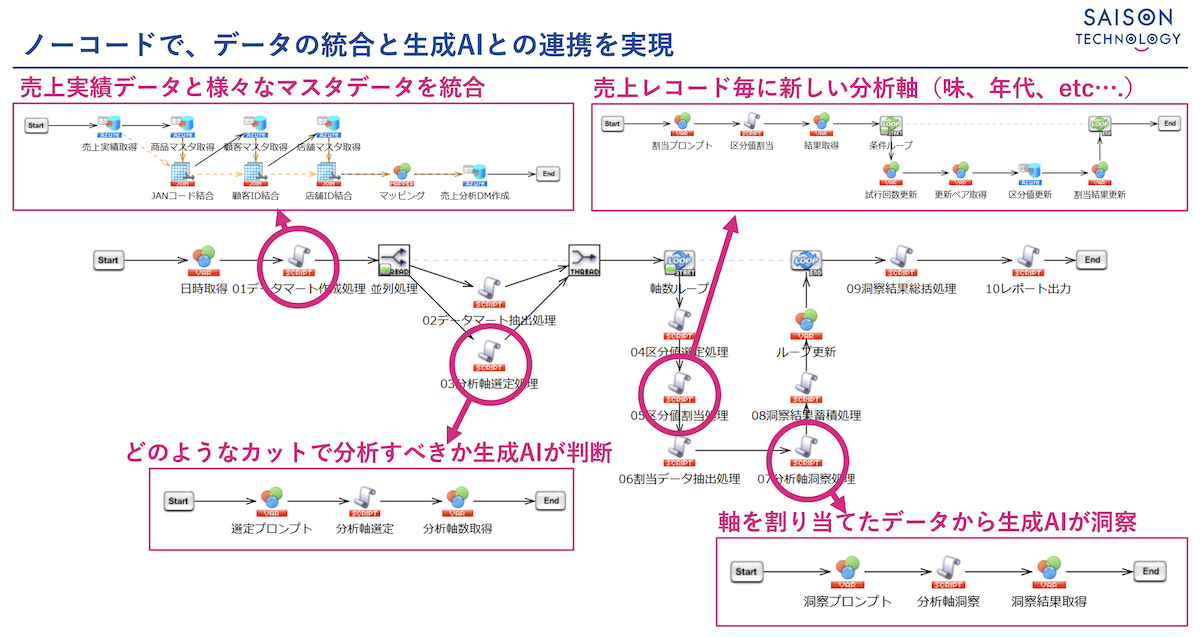 図2:ノーコードでデータの統合と生成AIの連携を実現
図2:ノーコードでデータの統合と生成AIの連携を実現拡大画像表示
「甘い、すっぱい、苦い、しょっぱいといった味の傾向と年齢層や性別をかけあわせて分析し、『中年男性層に甘党ブームが起こっていそうだ』『若年層で酸味ブームが起こっていそうだ』ということを知ることもできます。商品マスターに甘い、すっぱいといったデータを登録している企業は少ないと思います。しかし、生成AIに『このデータをどういう観点でみるべきか』と質問するだけで、商品を味別で見ればいいのではないか、パッケージ別で見ればいいのではないかを提案してくれます。商品マスターに関連するデータがなくても、例えば、原材料を見て味を見つけるといったように、生成AIが作り出してくれます」(山本氏)。
こうした作業には、データの統合や生成AIと連携する仕組みが必要だが、セゾンテクノロジーのデータ連携プラットフォーム(iPaaS)「HULFT Square」を使うことで、ノーコードで実現できるという。
「分析軸を考える生成AI、分析軸を割り当てる生成AI、分析軸から洞察する生成AIなど、AIエージェントのように、各生成AIを連携させることができます」(山本氏)。
データ連携 × 生成AI × データカタログで実現する「柔軟かつ変化に強いデータ分析基盤」
社内データを生成AIで活用すると、データが古く鮮度が悪い、コードが不明瞭でデータの意味が分からない、データソースが間違っていて売り上げの定義が違う、といった問題に直面することがある。するとユーザーは「生成AIは業務のことをよくわかっていない」として使わなくなることがある。これを解決するのがメタデータの整備だ。
誰のデータか(主管部門・更新者)、何のデータか(用語・コード体系)、いつのデータか(作成日・更新日)、どこのデータか(配置場所・URL)、何のためのデータか(業務・収集目的)、どのようなデータか(算出方式・算定式)を整備していく。
こうして収集・整備したデータをもとに生成AIでアカウントプランを自動で作成し、それを営業支援ツールに登録することで、営業活動での活用も可能となる。
メタデータは、目的のデータにたどりついたり、正しいデータで意思決定を行ったりするために必要だ。メタデータを収集・整理・管理することで、正しいデータに基づく意思決定が可能になる。しかし、メタデータ管理にも課題はある。
「データはクラウド、オンプレミス、サービスなどにさまざまなシステムに分散しています。また、システム連携の際にデータの姿・形はさまざまな変化しています。データに対するニーズは高まるばかりで、止めずに供給していくことも求められています。これらの課題に対処するためには、合理的な手段を選択する必要があります」(山本氏)。
そこでセゾンテクノロジーが提供するのが、メタデータマネジメントプラットフォーム「HULFT DataCatalog」だ。メタデータの自動収集管理、ビジネス用語での探索・発見・理解、データの信頼性の管理、セキュリティとデータ利活用の両立を実現する。
「柔軟かつ変化に強いデータ分析基盤は、データ連携と生成AIとデータカタログによって実現できます。オンプレミスやクラウドなどさまざまなところからデータを集め、メタデータを定義したうえで、生成AIやベクトルデータの検索などの仕組みに渡していきます。そこからインサイトを得て、チャットボットやレポート、業務システムに表示させていきます(図3)」(山本氏)。
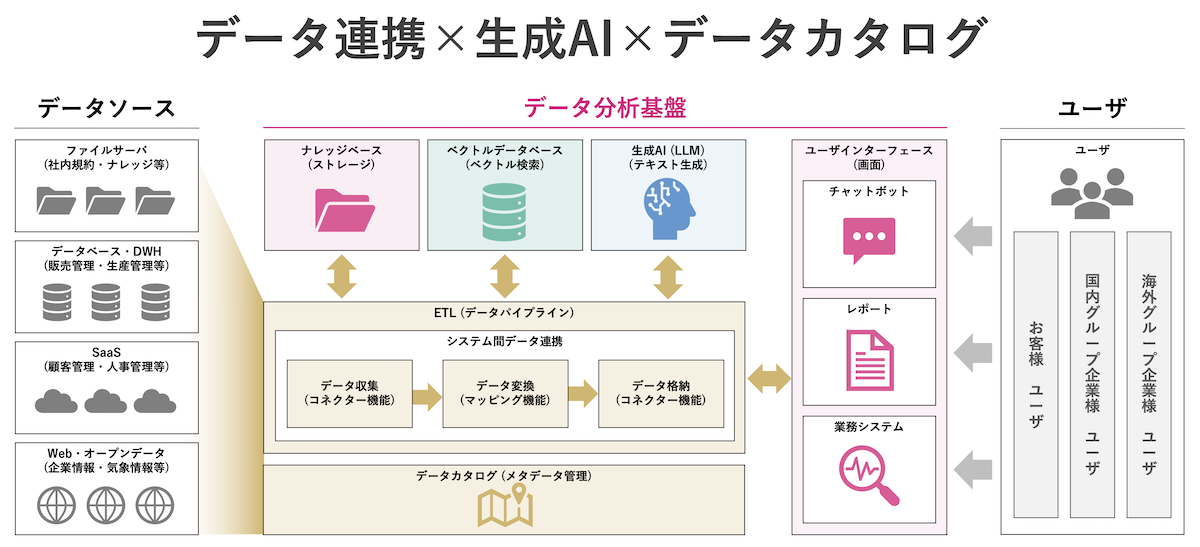 図3:「柔軟かつ変化に強いデータ分析基盤」の構成図
図3:「柔軟かつ変化に強いデータ分析基盤」の構成図拡大画像表示
最後に山本氏は「社内データ活用、クイックな疎結合、インサイト創出の取り組みに生成AIを活用できます。それを支えているのがデータ連携です」と話し、セゾンテクノロジーのソリューションが生成AI活用に貢献することを強調した。

●お問い合わせ先
株式会社セゾンテクノロジー
- 食品・消費財業界の共通課題が「店舗周りの断絶の壁」─“MDM×データサービス”が打開の鍵に(2025/08/13)
- 生成AI時代のデータ急増への“処方箋”。容量、電力効率、運用問題を抜本解消可能なストレージとは?(2025/06/09)
- 既存データから新たな示唆を得る─エンタープライズ企業の先進事例に見るAI SaaSのインパクト(2025/06/02)
- タクシーアプリ「GO」のデータ活用と、Google Cloudが目指す生成AIデータエージェントを解説(2025/05/22)
- AIに真の力を発揮させるデータ活用に不可欠な「ビジネスメタデータ」の意義と整備法(2025/05/09)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
