現在、あらゆる企業がAIと生成AIの活用に取り組んでいるが、そのために不可欠となるのがAI活用に最適化されたデータの整備だ。具体的には、データエンジニアリングのAI最適化、マスタデータ管理とAIアプリケーションの融合、そしてデータガバナンスからAIガバナンスへの拡張といった取り組みが必須となる。2025年3月7日に開催された「データマネジメント2025」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)のセッションでは、インフォマティカ・ジャパンの森本卓也氏が登壇し、AIのためのデータマネジメントのポイントと、その実現を支える最先端のデータマネジメントのためのAI技術について解説を行った。
提供:インフォマティカ・ジャパン株式会社
生成AI活用のためのデータに求められる3つの“R”
「生成AIはすでに、仕組みとして簡単に利用できる状況となっている。だが、PoCから本番業務への適用に踏み出せていない企業は少なくない。その大きな理由は、生成AIを活用するためのデータはまだまだ準備不足であり、本番業務では利用するには信頼できるものに至っていないからだ」と、登壇したインフォマティカ・ジャパンの森本卓也氏は訴える。
 インフォマティカ・ジャパン グローバル・パートナー テクニカルセールス ソリューションアーキテクト&エバンジェリストの森本卓也氏
インフォマティカ・ジャパン グローバル・パートナー テクニカルセールス ソリューションアーキテクト&エバンジェリストの森本卓也氏事実、調査会社の報告によれば、生成AIの活用を妨げる要因に“データ”がトップとして浮上しており、品質をはじめ、プライバシーやガバナンス等に関する課題解決が必須であることが明らかとなっている。そうしたことから、生成AIを本番運用へと移行させていくためには、AIのためのデータマネジメントにも取り組んでいく必要がある。
「AIのためのデータマネジメントによって、既存のデータを“AIレディ”(AIを人間が安全に活用できる状態のこと)なデータにすることが可能になる。では、AIレディなデータとはどのようなものを指すのか。それは、Relevant(関連性のある)、Robust(堅牢性を持つ)、Responsible(責任のある)の3つのR(3Rs)の要件を満たしたデータだ(図1)。
Relevantなデータとは、AIが目的とする作業に直接貢献できるデータ、つまり、AIの学習や推論に必要なデータが、過不足なく集められた状態のデータのことをいう。
次のRobustとは、信頼性の高いデータで、欠損や誤り、異常などのない、高品質な状態のデータとなる。
3つ目のResponsibleなデータとは、AIの倫理や規制に従い、正しく扱われているデータを指す。すなわち、プライバシーや透明性などが担保されている状態のデータを指す。
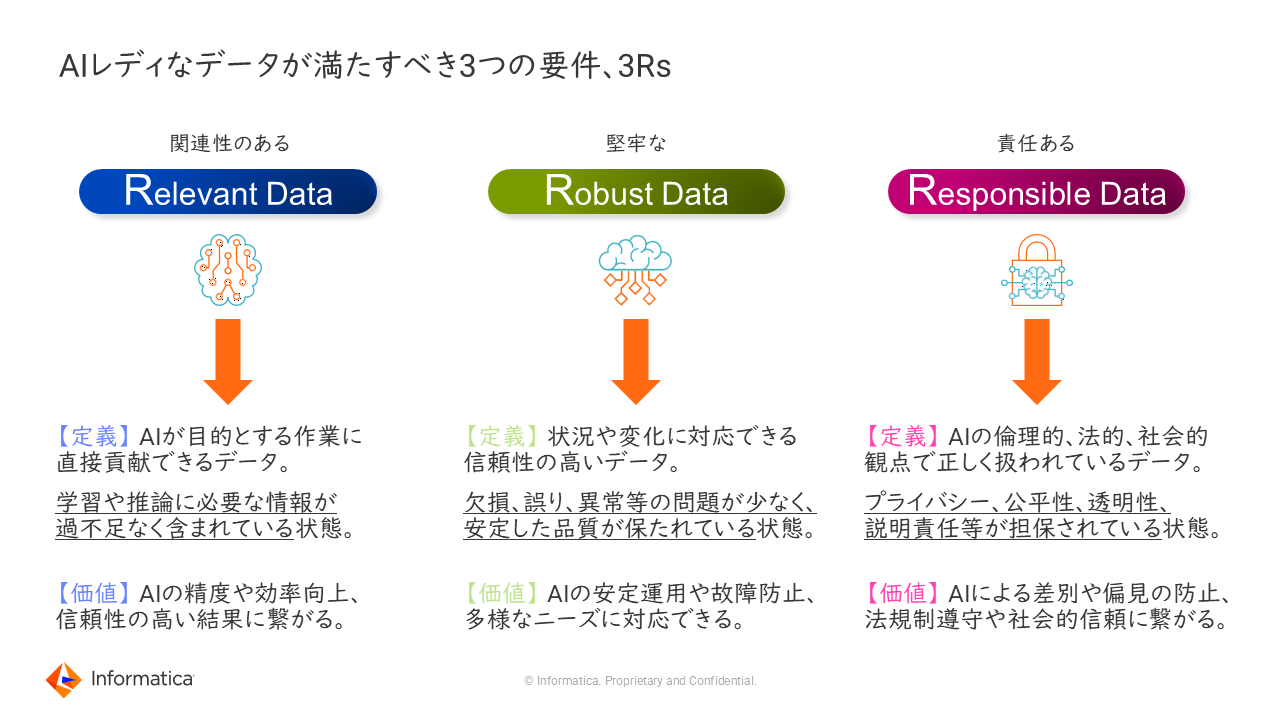 図1:AIレディなデータが満たすべき3つの条件(3Rs)
図1:AIレディなデータが満たすべき3つの条件(3Rs)拡大画像表示
AIのためのデータマネジメントに不可欠な10のポイント
森本氏は、データを3Rsの状態へと成熟させるための10のポイントを紹介。さらに、これらを実現するためにどのようなアプローチが必要なのか、順を追って解説した。
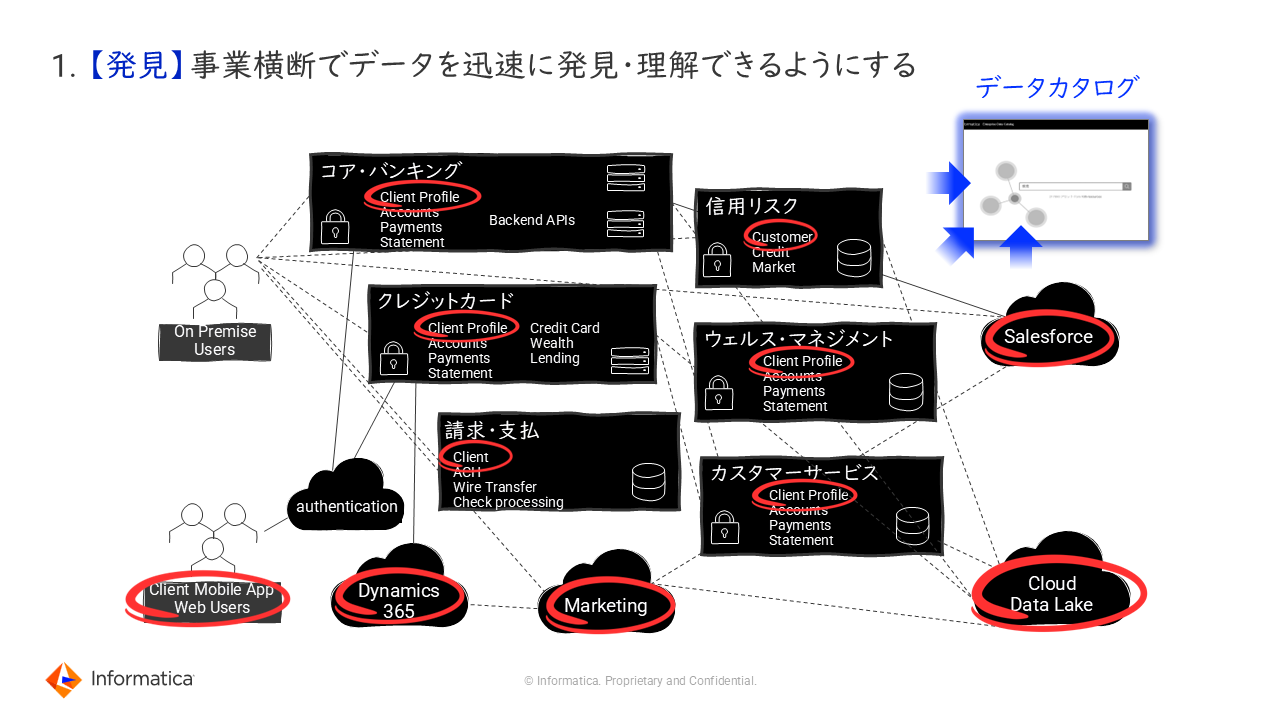
1. 【発見】事業横断でデータを迅速に発見・理解できるようにする
これを実現するために必要なアプローチが、データ探しに苦労しないように事業横断でデータを簡単に発見可能とするデータカタログの整備である。
「特に、マルチシステム、マルチクラウドのIT環境のようにデータが複数のソースに分散している環境において、アジャイルなAI開発、必要なデータ探しをするにはクラウド横断のデータカタログが必須となる」(森本氏)
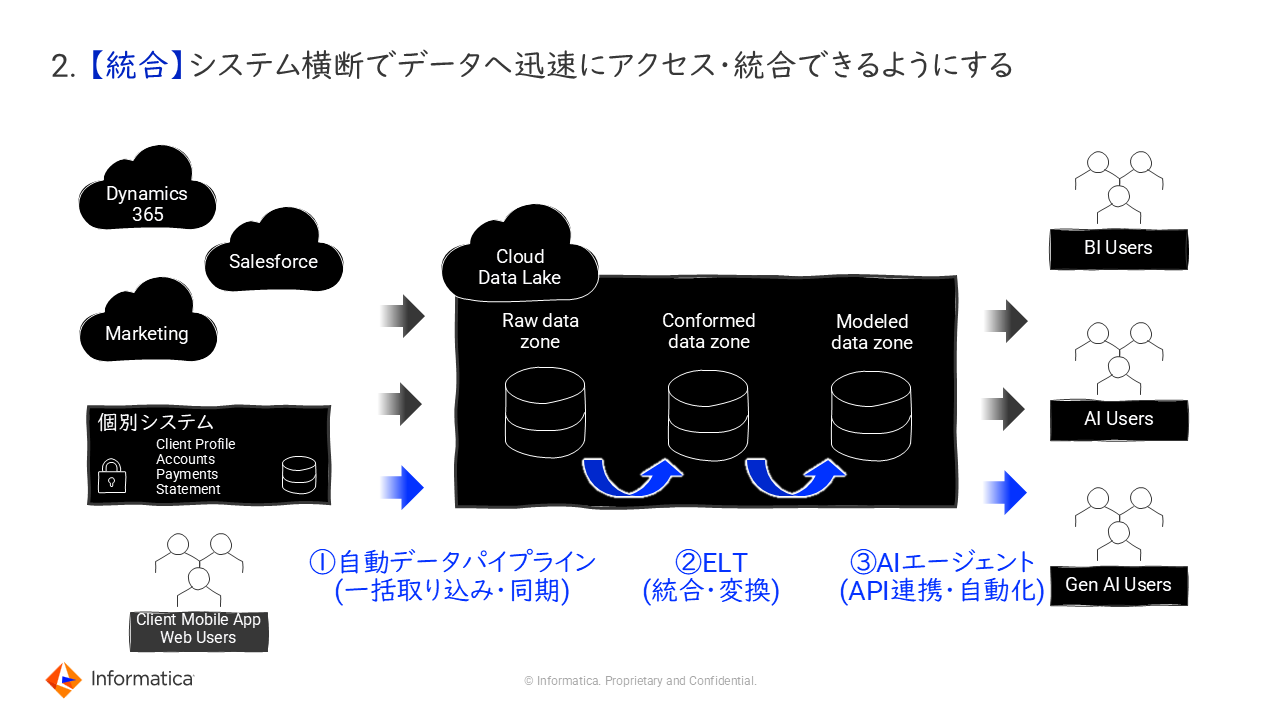
2. 【統合】システム横断でデータへ迅速にアクセス・統合できるようにする
発見したデータは、AIで簡単に分析ができるクラウドデータレイク、ウェアハウスに取り込んで、分析しやすい形に整備していくことが重要だ。そのためにはデータソースから必要なデータを自動でレプリケーションするための自動データパイププラン、データの統合・変換を行うETL、さらにはAPI連携や自動化を行うAIエージェントの活用が不可欠となる。
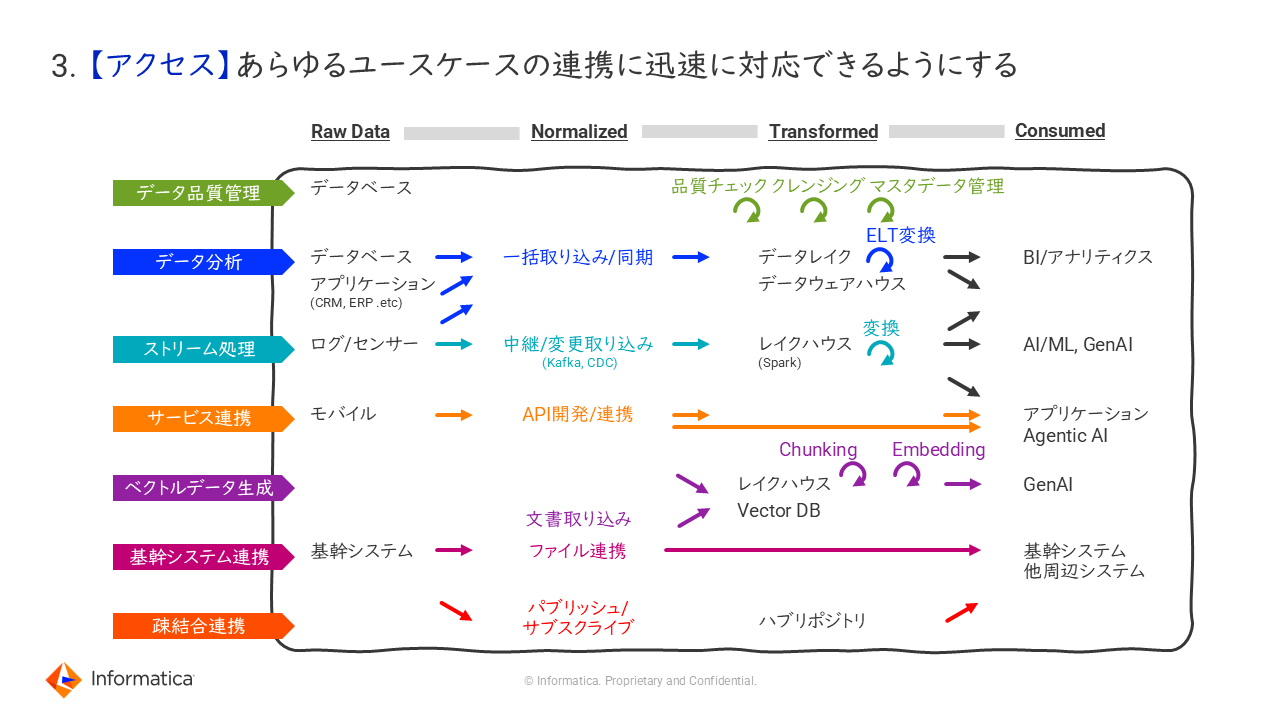
3. 【アクセス】あらゆるユースケースの連携に迅速に対応できるようにする
あらゆるAIユースケースのデータ連携に対応可能にすることも重要だ。複数のシステムを連携させるためには、多くの労苦と運用の煩雑化を伴うため、単独のプラットフォームで統合的なデータ連携や監視・運用を可能とする基盤を再構築することが肝要となる。これにより、ROIの大幅な削減も可能となる。
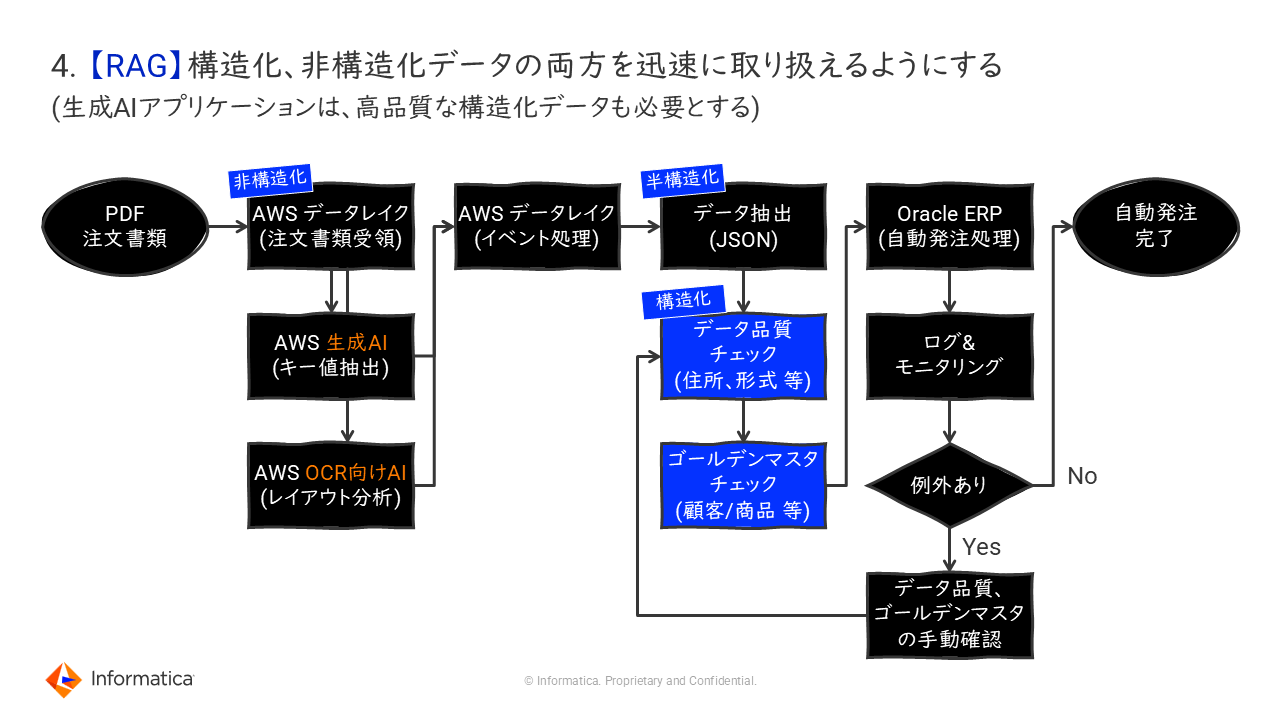
4. 【RAG】構造化、非構造化データの両方を迅速に取り扱えるようにする
生成AIを業務で使う上で必須の技術となるRAG(Retrieval Augmented Generation:検索拡張生成)やAIエージェント。この仕組みにインプットしていくデータについても考慮が必要だ。
「生成AIアプリケーションでは、文書などの非構造化データの取り扱いにフォーカスしがちだが、本番業務を見据えると、高品質な構造化データが不可欠なことも留意しなければならない」(森本氏)
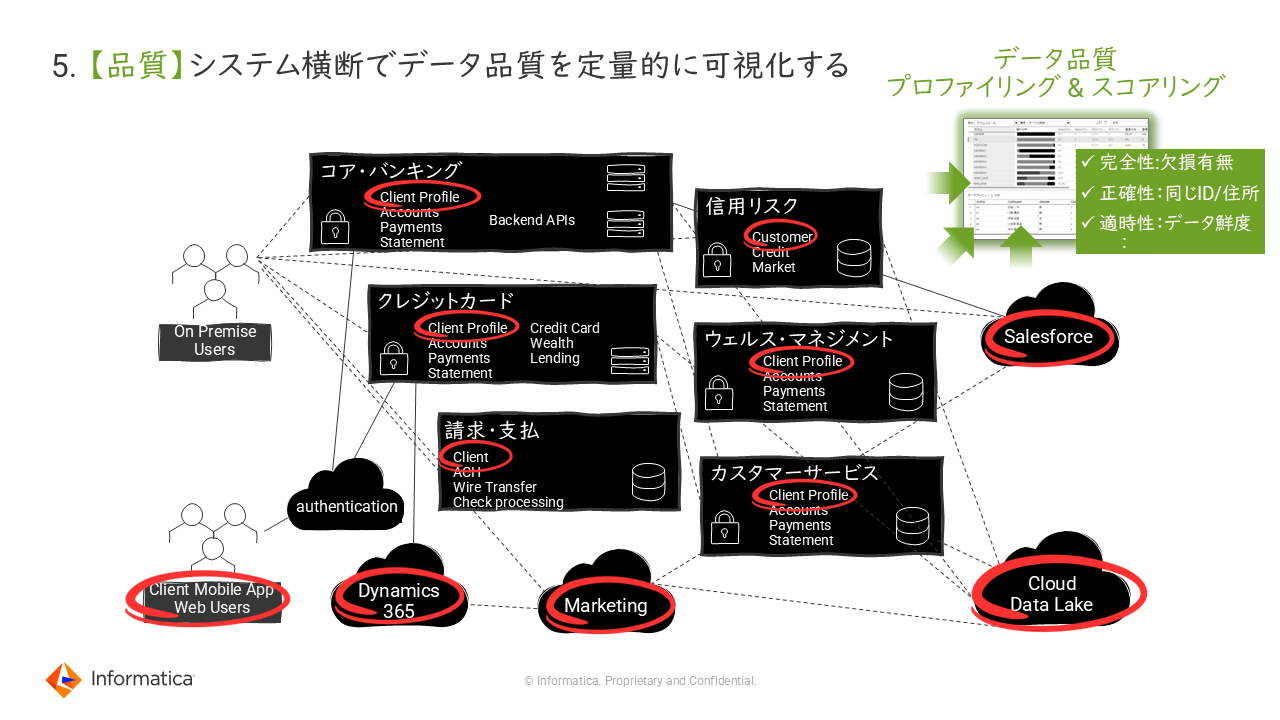
5. 【品質】システム横断でデータ品質を定量的に可視化する
さらに堅牢なデータ、高品質なデータを準備していくにあたっては、データ品質の定量的な可視化が不可欠となる。可視化を行っていくにあたり、近年ではデータ品質サービスやプロファイリングサービス等も提供されているので、それらのサービスを活用することも有効策となる。
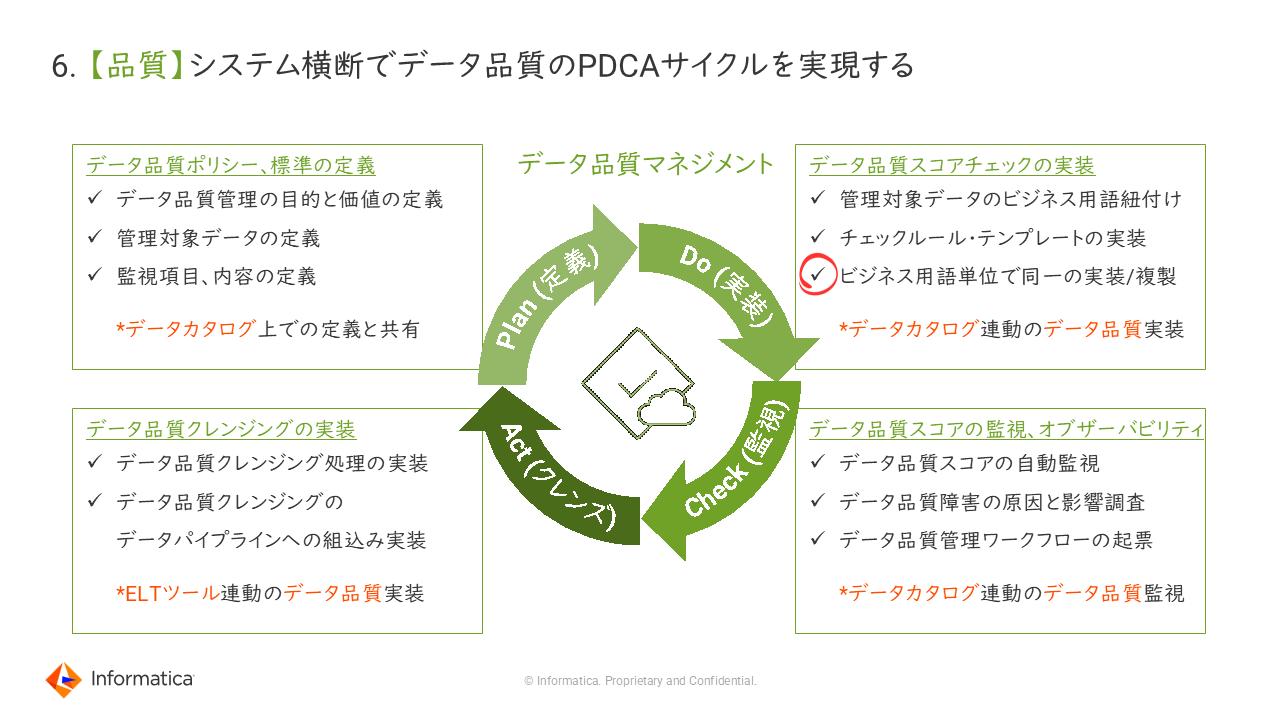
6. 【品質】システム横断でデータ品質のPDCAサイクルを実現する
単にデータ品質を可視化するだけではなく、品質に問題が発見された場合に改善していくためのPDCAサイクルを回していく仕組みも重要だ。そのためには、データ品質に関する全社的なポリシーをデータカタログの上に定義して全社共有していく。また、すべてのデータの品質チェックを行うことは今や現実的ではないので、対象を絞り込むことも肝要だ。
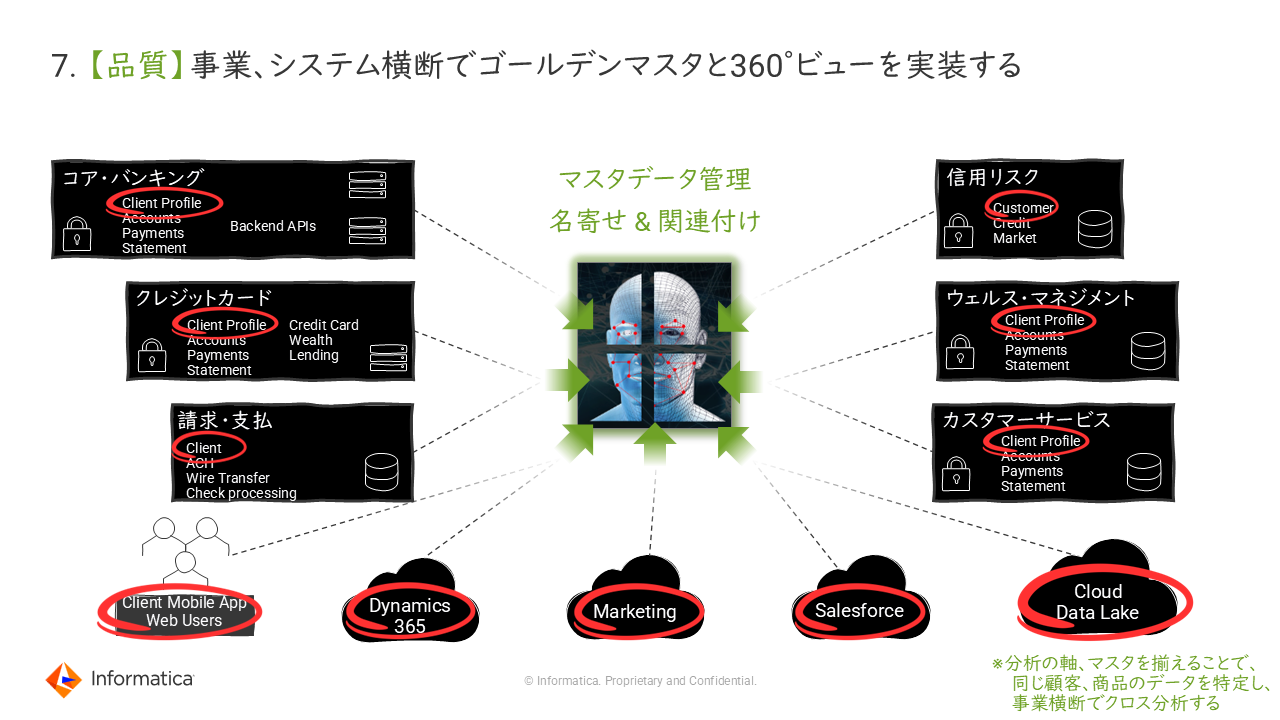
7. 【品質】事業、システム横断でゴールデンマスタと360°ビューを実装する
社内で利用している各SaaSやERP等は、それぞれ個別にマスターが実装されているケースが多い。各マスターからデータを抽出しクロス分析等を行う際には、名寄せや関連付け等の処理が必須となる。
そのために各システムの外部に共通MDM基盤を構築することが先進企業においては当たり前となりつつあり、事業を横断するAI活用を成功させるための必須条件となる。
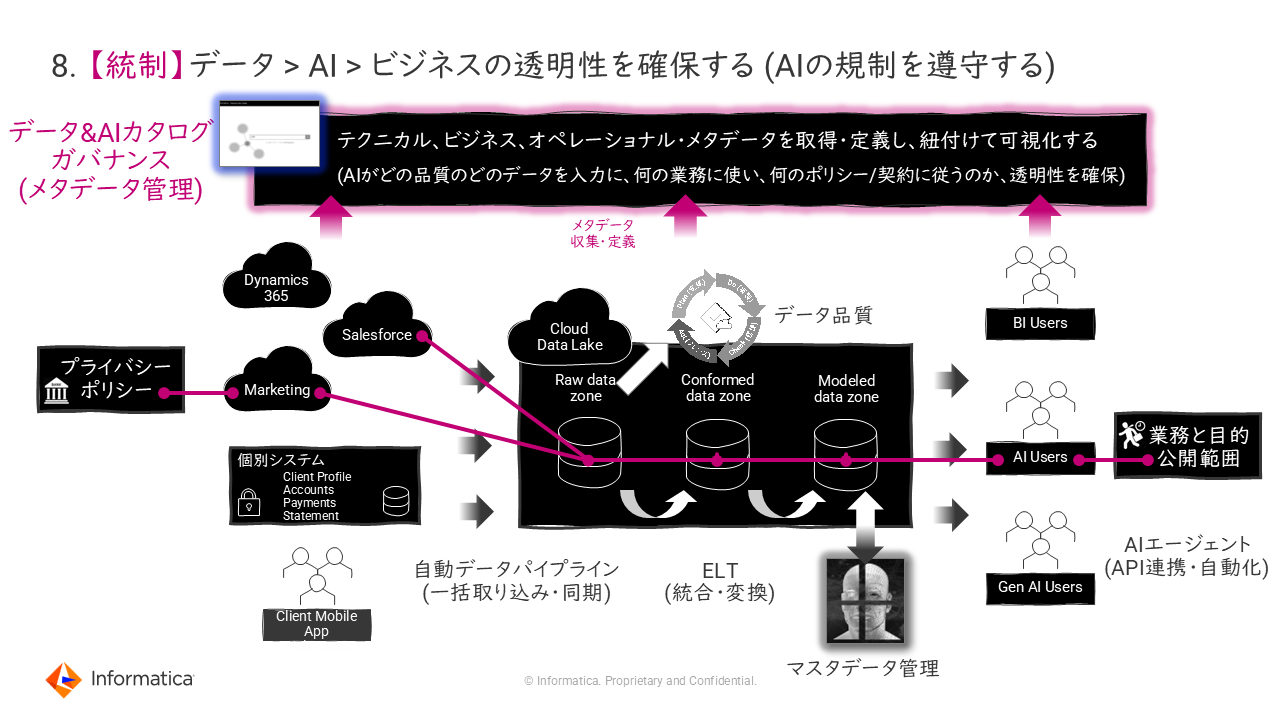
8. 【統制】データ>AI>ビジネスの透明性を確保する(AIの規制を遵守する)
現在、AIの規制に関して世界各国で日々、整備が進められており、これまで以上により強固なデータガバナンスが求められている。そうしたことから、データとAI、それを使う業務の透明性確保は絶対条件となる。
「データの流れを把握し、どのAIのインプットになり、どの業務で利用されているのかを、テクニカルとビジネス、オペレーションといった横断的な観点からデータ・リネージュ(データの生成から消費に至るまでの流れや履歴)として入手することが重要となる。そのためには、データ&AIガバナンスに対応したデータカタログの導入が必要だ」(森本氏)
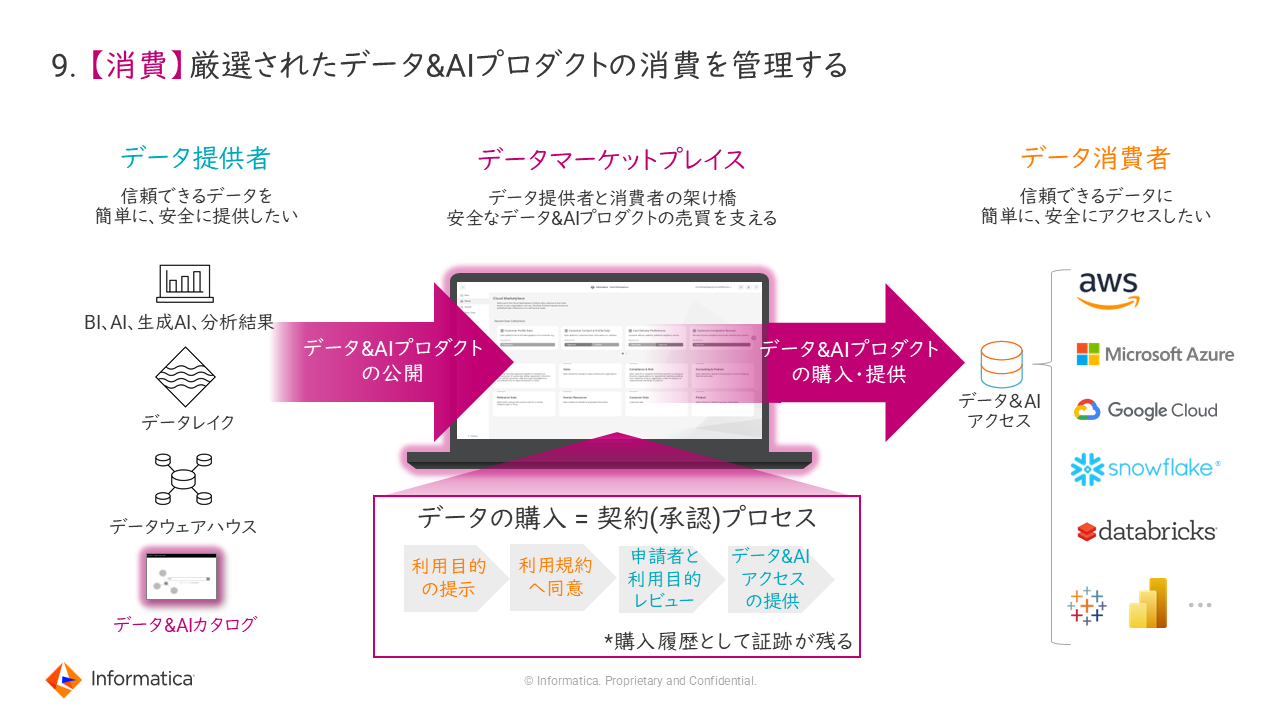
9. 【消費】厳選されたデータ&AIプロダクトの消費を管理する
先進企業は、データ&AIの消費を自動化して管理するため、データカタログの中から分析や業務に利用可能なプロダクト化されたデータを公開する「データマーケットプレイス」を整備している。これにより、データ消費者は必要なデータを簡単に見つけ出し、安全に活用できるようになる。また、データの利用申請から承認までのプロセスもログとして証左が残るため、管理性も大幅に向上する。
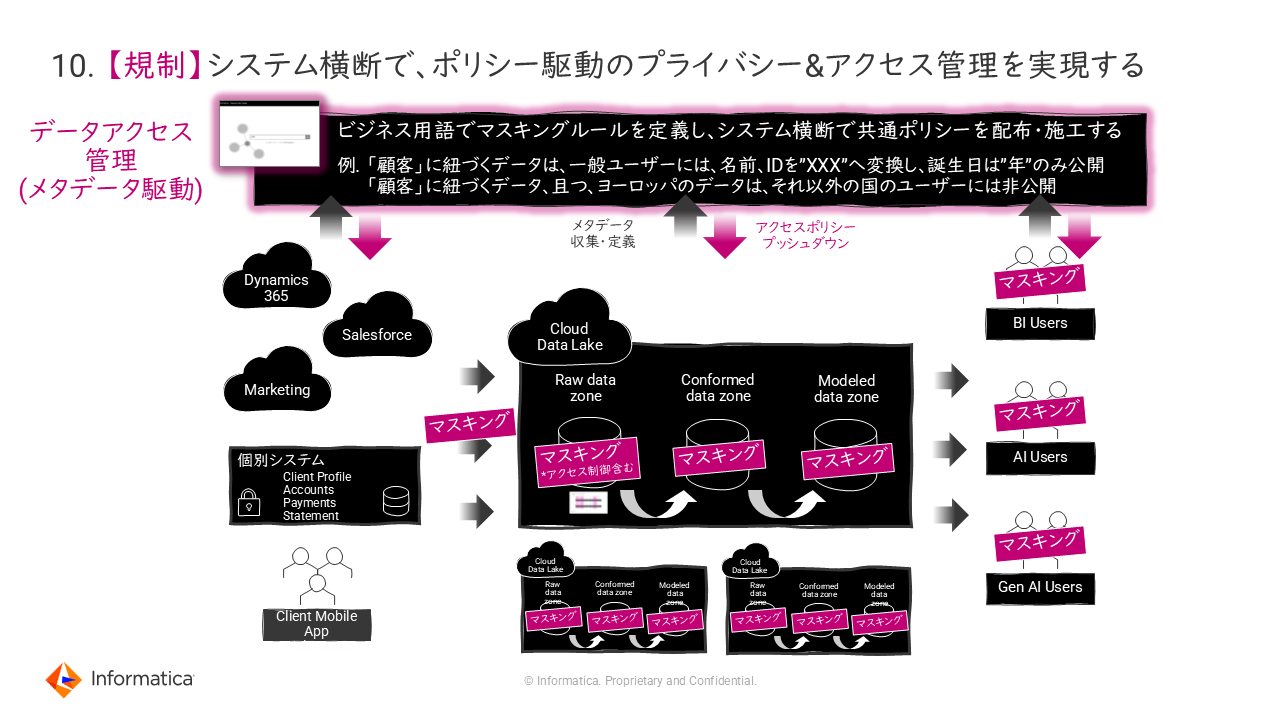
10. 【規制】システム横断で、ポリシー駆動のプライバシー&アクセス管理を実現する
顧客データ等の活用にあたって、機密情報は保護されなければならず、厳密なアクセス管理が必要となる。しかし、データソースが多様化し、今後も増加が予期される中では、データ分析ツールごとにアクセス管理を行っていたのでは、運用負荷は増すばかりだ。そうした課題の解決に向け、先進企業では「ポリシー駆動型のアクセス管理」を導入するケースが増えている。
「具体的には、データカタログ上で、ビジネス用語でマスキングルールを定義し、システム横断で共通ポリシーを配布・施行することで集中管理を行う仕組みだ」(森本氏)
AIのためのデータマネジメントを全方位でサポート
これまで説明してきたAIのためのデータマネジメントのベストプラクティスをまとめると、下図のようなものとなる(図2)。
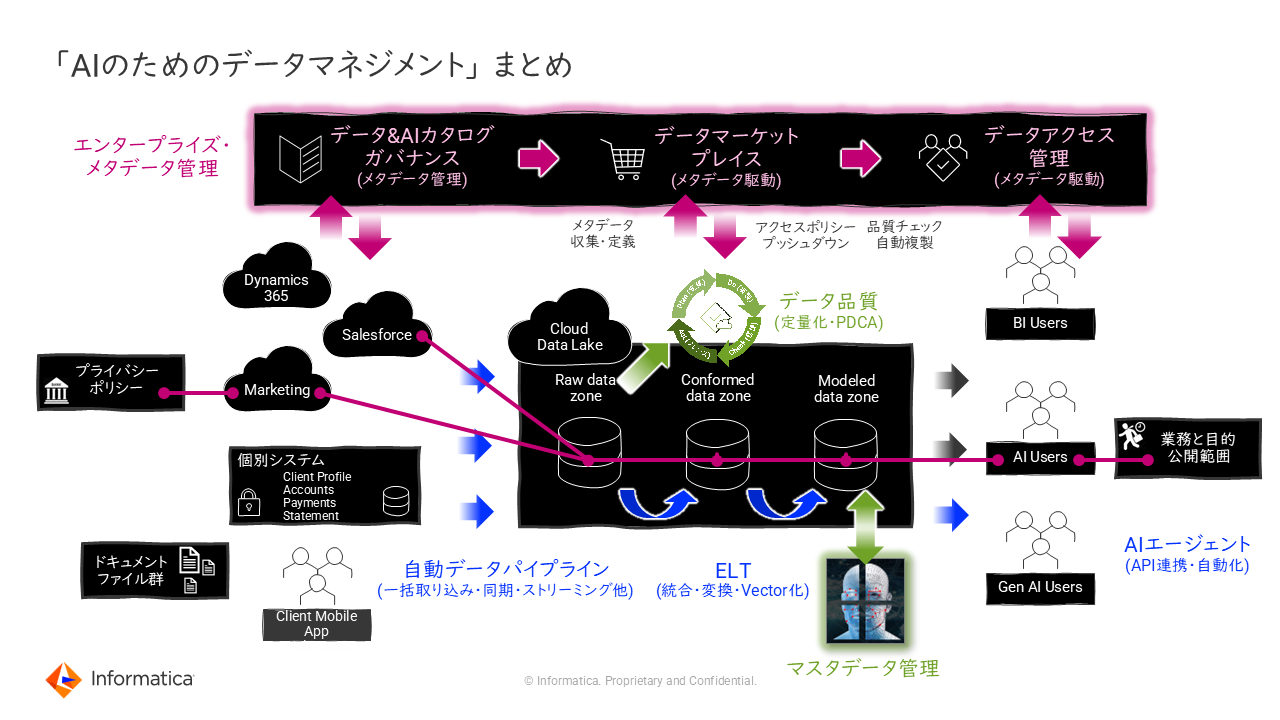
「“AIのための”と言いながらも、実際にはこれまで行ってきたデータマネジメントと同様の仕組みであることがわかるだろう。生成AIをイメージした場合には非構造化データに着目しがちであるが、先述したように構造化データの管理も重要だ。したがって、従来のデータマネジメントを確実に実践することも肝要となる」(森本氏)
ただし、従来型のデータマネジメントと異なる点は、今後のデータの種別、量の増大に対応可能な、より高度化、自動化されたデータマネジメントが求められることだ。
そこで改めて重要となるのが、データマネジメントのためのAIである。
「データマネジメントのためのAIを実装することで、より関連性があり、より堅牢な、より責任ある、AIレディなデータを入手可能となる。結果、よりアジャイルに、より簡単に、よりスケーラブルな、AIの本番運用が実現される」(森本氏)
そうしたAIのためのデータマネジメントの推進を阻害しているのが、データマネジメントツールのサイロ化だ。
特に、“モダンデータスタック”と呼ばれるような、複数のツールを組合せて実装してきた企業の場合、各データマネジメントツールを横断するメタデータを共有できず、連動したAIの恩恵を享受することが困難になりがちだ。
これらの課題解決に向けて、インフォマティカでは単一のプラットフォーム上において、これまで説明してきた全てのソリューションを実現する、包括的なデータ管理サービスを展開している(図3)。
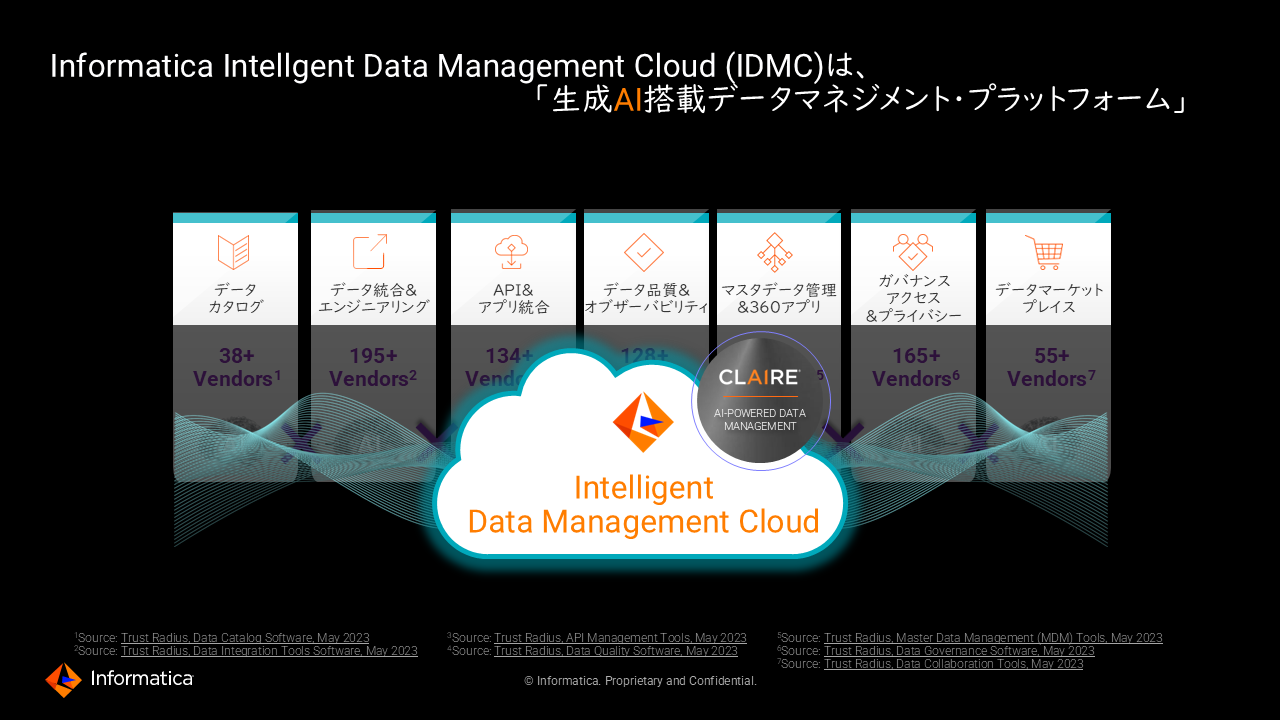 図3:データマネジメントツールを横断する生成AIを搭載したインフォマティカのデータマネジメント・プラットフォーム
図3:データマネジメントツールを横断する生成AIを搭載したインフォマティカのデータマネジメント・プラットフォーム拡大画像表示
「インフォマティカは、あらゆるサービスの情報、メタデータを全サービス横断で共有し、それをインプットにしたデータ管理専用のAIである『CLAIRE』を提供している。そして、このCLAIREを内包した私たちのプラットフォームを『Intelligent Data Management Cloud』、略してIDMCと呼んでいる。このIDMCを活用することで、AIのためのデータマネジメントのプラクティスがすぐに実践可能となるほか、データマネジメントのためのAIであるCLAIREの恩恵がすぐに受けられるようになる」(森本氏)
最後に森本氏は、データマネジメントのためのAIを活用することで、「AIのためのデータマネジメント」の適正なループを加速させていくことが可能となると述べ、「そのための実践を実現できるのがインフォマティカであり、すでに数多くの導入事例も積み重ねている。AIのためのデータマネジメントを検討しているのであれば、ぜひ一度インフォマティカにご相談いただきたい」とアピールし、セッションを終えた。
●お問い合わせ先

インフォマティカ・ジャパン株式会社
URL: https://www.informatica.com/ja/
TEL:03-6403-7600
お問い合わせ:https://www.informatica.com/ja/contact-us.html
- 食品・消費財業界の共通課題が「店舗周りの断絶の壁」─“MDM×データサービス”が打開の鍵に(2025/08/13)
- 生成AI時代のデータ急増への“処方箋”。容量、電力効率、運用問題を抜本解消可能なストレージとは?(2025/06/09)
- 既存データから新たな示唆を得る─エンタープライズ企業の先進事例に見るAI SaaSのインパクト(2025/06/02)
- タクシーアプリ「GO」のデータ活用と、Google Cloudが目指す生成AIデータエージェントを解説(2025/05/22)
- AIに真の力を発揮させるデータ活用に不可欠な「ビジネスメタデータ」の意義と整備法(2025/05/09)
Informatica / 生成AI / RAG


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
