[市場動向]
NRI、業界/タスク特化型LLMを80億パラメータの小規模モデルをベースに構築する手法を開発
2025年4月15日(火)日川 佳三(IT Leaders編集部)
野村総合研究所(NRI)は2025年4月15日、80億パラメータの比較的小規模なモデルをベースに特定業界やタスクに特化した大規模言語モデルを構築する手法を開発したと発表した。同手法を用いて開発したモデルは、特定のタスクにおいて、大規模な商用汎用モデルであるGPT-4oを超える性能を示したという。
野村総合研究所(NRI)は、80億パラメータの比較的小規模なモデルをベースに特定業界やタスクに特化した大規模言語モデル「業界・タスク特化型LLM」を構築する手法を開発した。同手法を用いて開発したモデルは、特定のタスクにおいて、大規模な商用汎用モデルであるGPT-4oを超える性能を示したという(図1)。
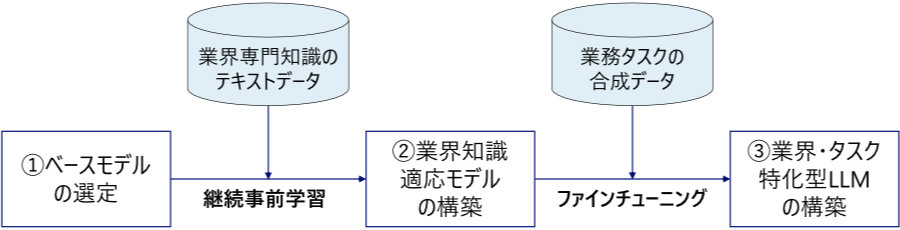 図1:「業界・タスク特化型LLM」の構築プロセス(出典:野村総合研究所)
図1:「業界・タスク特化型LLM」の構築プロセス(出典:野村総合研究所)拡大画像表示
「GPT-4oなどの一般的な汎用モデルは幅広いタスクで利用可能な一方、専門性の高いタスクや特定の業界で求められる専門知識や独自の用語・規制などへの対応が難しい。パラメータ数が大きく、計算コストも高い」(NRI)。同社はこれらの課題を解決するため、実務に即した業界・タスク特化型LLMを、低コストかつ高精度で構築する手法を開発した。
業界・タスク特化型LLMの開発手法は、以下の3段階のアプローチを採る。
(1)コスト効率の高い小規模ベースモデルの選定
(2)継続事前学習による業界知識適応モデルの構築
(3)合成データを用いたタスク特化型LLMの構築
(1)では、ベースモデルとして東京科学大学と産業技術総合研究所が開発した日本語処理性能が高い「Llama 3.1 Swallow 8B」(80億パラメータ)を利用。小規模モデルであるため、計算リソースや運用コストを減らせる。なお、NRIの開発手法はベースモデルを特定のモデルに固定しておらず、目的やタスクに応じて適切に選定可能である。
(2)では、銀行・保険などの金融業界を例に、日本語の専門知識テキストデータを日本語金融コーパスとして独自に構築し、継続事前学習を実施。ベースモデルが持つ一般的な言語能力や知識を維持しつつ、業界特有の専門的知識を効果的に習得させる汎用的な仕組みを構築した。
(3)では、今回ターゲットとした「保険業界の営業コンプライアンスチェック」の場合、規制違反を含む会話データの収集が困難なため、LLMを用いて各種シナリオを想定した合成データを生成。この合成データをもとにファインチューニングを実施することで、該当タスクに特化したLLMを構築した。
これらの取り組みにより、保険業界の営業コンプライアンスチェック試験では、商用大規模モデルのGPT-4o(2024-11-20)を9.6ポイント上回る正解率を実現した(表1)。この試験では、評価データ344件(7種類の違反項目に抵触する会話172件と、いずれの違反項目にも抵触しない会話172件)に対し、違反項目(なしも含む)の正解率を評価した。
| モデル | 正解率 |
|---|---|
| GPT-4o(2024-11-20) | 76.7% |
| ベースモデル(Llama 3.1 Swallow 8B Instruct v0.2) | 51.7% |
| NRI独自特化型モデル(Llama 3.1 Swallow 8B + ファインチューニング) | 83.1% |
| NRI独自特化型モデル(Llama 3.1 Swallow 8B + 継続事前学習 + ファインチューニング) | 86.3% |
NRIは、今回の成果を基に他の業界やタスクへの最適化を進める。汎用モデルでは対応が難しい専門領域への展開も推進していく。2025年度には、東京科学大学の岡崎研究室との共同研究を予定している。具体的な業界課題を反映した実証実験やモデル技術の改良を重ね、生成AIの社会実装を進める。ビッグテック企業やスタートアップとの連携も強化し、技術の商用展開や実用化を推進するとしている。


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
