[海外動向]
データ連携ツールからデータ基盤へ、「Intelligent Data Platform」を発表
2014年5月14日(水)志度 昌宏(DIGITAL X編集長)
データマネジメント関連ツールを開発・販売する米インフォマティカが2014年5月12日から15日(現地時間)にかけて、米ラスベガスで年次ユーザーカンファレンス「Informatica World 2014」を開催中だ。5月13日の基調講演では同社の新ビジョン「Intelligent Data Platform」を発表した。データの多様化が進む中で、誰もが必要なときに必要なデータを利用できるようにするという。データ活用への期待が高まる中、Intelligent Data Platformの考え方は、データマネジメントの1つの方向性を示したといえそうだ。
データの仮想化を前提とした3階層
では、Intelligent Data Platformは、どのようなものか。アバシ氏に続き登壇したエクゼクティブバイスプレジデント兼CPO(Chief Product Officer)のアニル・チャクラヴァシー氏による解説を含め紹介しよう。
写真5にあるように、Intelligent Data Platformは3つの層からなっている。基盤となる同社製品「Vibe」と、「Data Infrastructure」および「Data Intelligence」である。Vibeはデータを仮想化する仕組みで、種々のデータソースに対しデータの定義や変換ロジックを設定することで、データを必要な環境で利用できるようにする。
 写真5:3つの層からなるIntelligent Data Platformの概念
写真5:3つの層からなるIntelligent Data Platformの概念拡大画像表示
Data Infrastructureは、データの流通を支える層で、「Feed」「Integration」「Quality & Mastering」「Management」の4つの機能を提供する。それぞれは同社製品「Power Exchange」、「Power Center」や「Cloud Integration」、「Data Quality」や「MDM」、「Data Masking」などが中核製品になる。
今回、4つの機能領域それぞれで、Intelligent Data Platformの実現に必要な製品/機能を追加投入した。例えば、センサーデータなどの取り扱いを可能にする「Vibe Data Stream」や、Publish/Subscribe型のデータ統合を可能にする「Data Integration Hub」などだ。Data Integration Hubでは、複数のアプリケーションが利用するデータについては一度、中間DBに格納し、すべての利用先が取り出した段階で消去する。
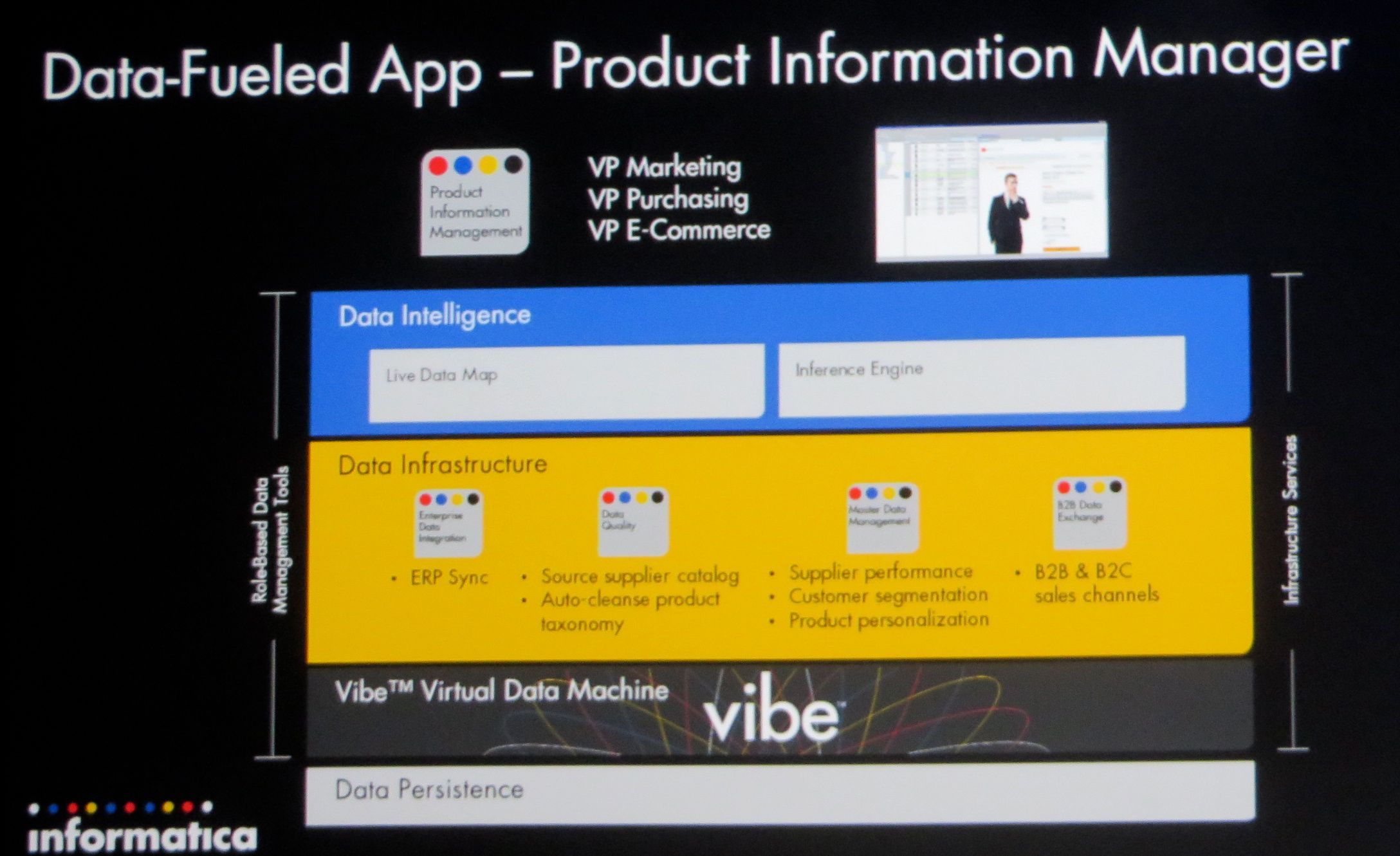 写真6:オムニチャネル用の製品情報管理ツール「PIM(Product Information Management)」
写真6:オムニチャネル用の製品情報管理ツール「PIM(Product Information Management)」拡大画像表示
Data Intelligenceは、データ活用を容易にするための層で、データの関連性を管理したり機械学習によって求められるデータを推論したりレコメンドしたりする。アバシ氏が基調講演前半で紹介したSpringbokやSecure@Sourceは、Data Intelligence層の活用例になる。オムニチャネル用の製品情報管理ツール「PIM(Product Information Management)」も同列に並ぶ(写真6)。
クラウド統合では業務プロセスの自動化ツールも提供
Intelligent Data Platformの詳細説明に続き、チャクラヴァシー氏はクラウド統合とビッグデータに対するインフォマティカの最新の取り組み状況も披露した。クラウド統合では、大量データをAWS(Amazon Web Services)に簡単な操作で投入するデモに続き、複数のクラウドにまたがるアプリケーションを連携させる「Cloud Process Automation」をデモして見せた。
Cloud Process Automationは、特定のデータに予めしきい値を設定しておき、そのデータがしきい値を超えると、必要なプロセスを自動的に起動するもの。デモでは、Salesforce.comのデータにしきい値を設定し、そこから発注処理の承認を求めるメールを上司に送り、承認後は自動発注し、その結果をSaaS型ERPのNetSuiteに反映させるまでを自動化した。単なるデータ連係にとどまらず、既存サービスを組み合わせて新たなアプリケーションを開発できることになる。
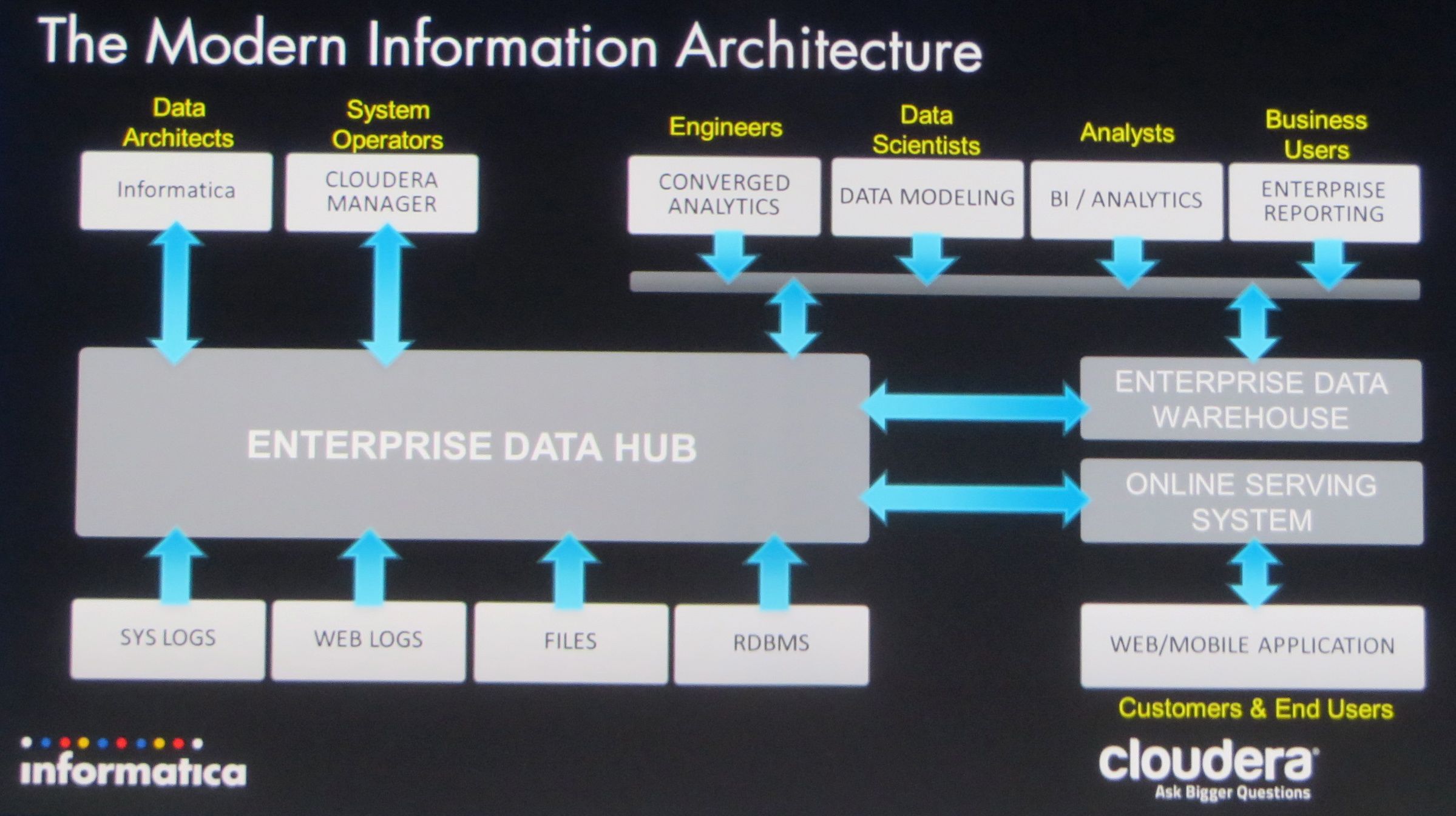 写真7:インフォマティカとClouderaが進める次世代アーキテクチャの概念
写真7:インフォマティカとClouderaが進める次世代アーキテクチャの概念拡大画像表示
ビッグデータ関連では、PowerCenterのビッグデータ対応において、分散処理基盤であるHadoopの関連製品を開発する米Clouderaとの共同開発の進捗状況を紹介した(写真7)。両者は共同で、ビッグデータインテグレーションのスペシャリスト認定も始めている。
従来、情報システムの構築では、アプリケーションに集中し、データはその従属物とする考え方が強かった。結果、その時々に必要なビジネスプロセスを最新の製品やテクノロジーを使って構築することに、データについては「利用できれば十分」として、ETLなどのデータ連係ツールを導入したり、あるいは専用ツールを個別開発したりするのが一般的だった。
だが、ビッグデータの時代に、これまで同様のアプローチを続けていては、システムのサイロ化はもとより、データ/システム連携のしくみそのものが複雑化するとともに、個々の仕組みに長けた技術者が必要になり、結果として運用コストの高止まりを招いていた。
単なるデータ連係ツールではなく、データ活用のための基盤を構築すべきとしたインフォマティカのメッセージは、新しい種類のアプリ−ケーション構築を可能にするだけでなく、「データの流れを追いかけ、企業活動全体に横串を刺す」ことを求められているIT部門の存在価値を高めるためにも十分に検討する価値がありそうだ。
Informatica / データ活用基盤 / データ連携




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
