SIベンダーの三井情報(MKI)は2018年11月29日、テキスト解析に特化した機械学習エンジン「KIBIT(キビット)」(FRONTEOが開発)を販売開始すると発表した。VOC(顧客の声)データの活用を高度化する、といった提案に利用する。
三井情報は今回、FRONTEOが開発したマシンラーニング(機械学習)エンジンで、類似テキストを見つけるなどのテキスト解析に特化したKIBITの取り扱いを開始した。これまで金融機関に対して提供してきた音声認識システムなどにKIBITを加えることで、音声認識によって収集したテキストデータやVOCデータを解析して高度に活用できるようにする狙いがある(図1)。
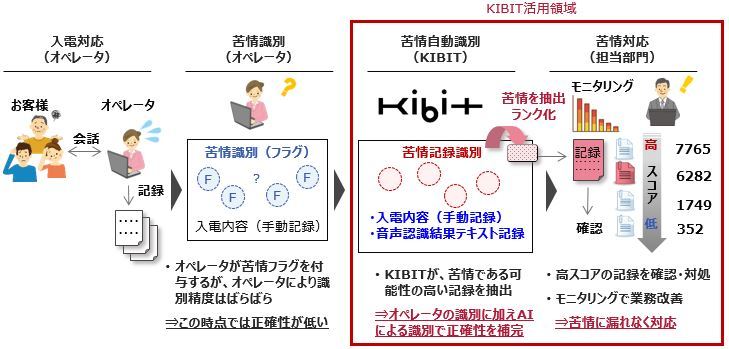 図1:コールセンターの苦情対応における活用例(出典:三井情報)
図1:コールセンターの苦情対応における活用例(出典:三井情報)拡大画像表示
開発会社のFRONTEOが4つの金融機関の協力を得て2018年5月に取り組んだ金融庁の「FinTech 実証実験ハブ」では、KIBITを活用した業務記録のチェック作業において「42%の時間短縮、正解検出数2倍、能力の標準化や高度化にも効果あり」との試験結果が得られたという。
なお、KIBITは、テキスト解析に特化した機械学習エンジンである(関連記事:少量のサンプルで類似テキストを見つける機械学習ソフト、FRONTEOが提供)。学習データとして、見つけたいテキストのサンプルを与えることで、判定するテキストが学習データとどれだけ似ているかをスコア化する。
KIBITの特徴は、教師データが少なくても使えることである。例えば、100件のデータのうち1件だけを教師データとして指定すると、指定した教師データに似た10%のデータを教師データとして使って判定モデルを作成できる。この判定モデルを用いて残りの90%のデータをスコア化できる。
三井情報が挙げる、従来型のキーワード検索に対するKIBITの優位性は、表1の通り。
| ポイント | 従来型のキーワード検索やテキストマイニング | KIBIT |
|---|---|---|
| 音声認識変換精度 | 音声認識で100%の精度を出すことは難しく、数%の精度を上げるために学習データとコストがかかる | 会話全体の文脈から検知するため、多少の誤変換は問題なし |
| キーワード検索の限界 | そもそも会話に違反のキーワードが含まれていない場合がある | 特定のキーワードが含まれていなくとも文脈から検知可能 |
| 膨大な通話件数 | 音声通話件数が多いと、解析時間が膨大になり迅速な監査ができない | 高速な解析処理により迅速な監査が可能 |
| 監査体制 | 全件の通話を聞くことができず、テキスト変換されても交換精度が悪いと検索ができない。監査体制にも限界がある | 解析結果がスコアリングされるので、スコアの高いものから優先順位付けしチェックを効率化 |




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
