日立ソリューションズは2019年11月25日、大量の文書ファイルをAIで解析し、ファイル同士の関係や特徴的なキーワードを可視化するソフトウェア「活文 知的情報マイニング」の新版を発表した。新版では、米Googleの自然言語処理技術「BERT」を採用し、より高精度にテキストを分類できるようにした。2019年12月2日から販売する。価格(税別)は、60万円から。
「活文 知的情報マイニング」は、報告書やマニュアルなど大量の業務文書をAIで解析し、文章を構成する特徴的なキーワードを自動抽出するとともに、文書ファイル同士の関係を可視化するソフトウェアである(図1)。ファイルサーバー内にある過去の事例や報告書といった大量の情報の中から、情報の関係性が分かる。
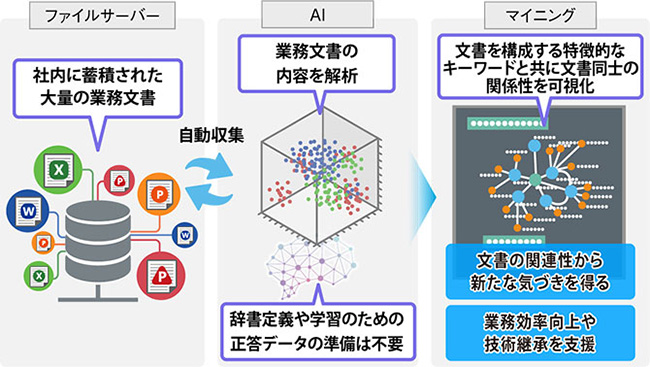 図1:活文 知的情報マイニングの概要(出典:日立ソリューションズ)
図1:活文 知的情報マイニングの概要(出典:日立ソリューションズ)拡大画像表示
「ある単語が、どのような単語と一緒に、どのような順番で使われているか」といった、単語の並びや文脈を数値化してマッピングする仕組みである。このため、同義語や類似語の辞書を定義したり、学習のために正答データを準備したりする必要がない。この仕組みにより、短期間での導入できるほか、導入後のメンテナンスも負荷を軽減できる。
主な用途の1つが、文書の分類である。大量の文書を内容を解析した上で分類できる。さらに、キーワード検索にもも利用できる。質問文とFAQでキーワードが一致しないために全文検索にヒットしないといった問題を解決できる。これらにより、手元にある文章や頭に浮かんだキーワードから、必要なマニュアルや資料を見つけ出せるようになる。
Web APIを提供することから、既存システムとの連携も可能である。
今回の新版では、米Googleが開発した、自然言語処理分野で事前学習モデルを作成するための手法「BERT(Bidirectional Encoder Representations from Transformers)」を採用した。Web上に公開されている大量の文章で事前学習したモデルを利用することによって、高精度に文書を分類できるようになるとしている。ユーザーは、少量の教師データを追加学習させるだけでBERTを利用できる。
日立ソリューションズ / BERT / 自然言語処理 / Google / 活文




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
