[新製品・サービス]
NTTデータ、特定の業務領域に最適化したBERT言語モデルのフレームワークを開発
2021年3月17日(水)日川 佳三(IT Leaders編集部)
NTTデータは2021年3月16日、汎用言語モデルのBERTを、特定の業務領域(ドメイン)に応じて最適化し、顧客が扱う業務文書に合った言語モデルを自動で構築する仕組みとして「ドメイン特化BERT構築フレームワーク」を開発したと発表した。これを使うことで、ユーザーの業務領域に特化したBERTを短期間で構築できるようになったとしている。
NTTデータの「ドメイン特化BERT構築フレームワーク」(略称:ドメイン特化BERT-FW)は、汎用言語モデルのBERT(Bidirectional Encoder Representations from Transformers)に追加学習を行い、ユーザーの業務文書に合わせた言語モデルを構築する仕組みである(図1)。
ユーザーの業務文書から一般的なBERTモデルが苦手とする文を抽出し、インターネット上から類似文章を自動で収集して追加学習する、というアプローチをとる。
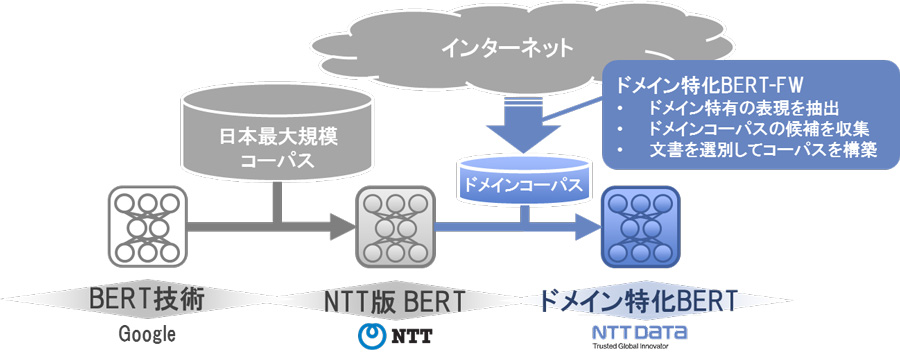 図1:ドメイン特化BERT-FWの仕組み(出典:NTTデータ)
図1:ドメイン特化BERT-FWの仕組み(出典:NTTデータ)拡大画像表示
ドメイン特化BERT-FWによって、専門用語や特有の文脈への対応が必要だった分野においても、自然言語処理技術を活用できる。NTTデータでは、2021年4月以降順次、文書を扱う業務の効率化やサービスの高度化を検討している企業を募る。2021年度中に、ユーザーとの共同検証を5件実施することを目指す。
同フレームワークでは、言語モデル自体をユーザー企業の業務文書に合わせることで、従来のBERTと比べて、専門用語や特有の文脈を含む文書を解析する際の精度を高めている。また、言語モデル構築の一連の流れを自動化し、専門家がチューニングする場合よりも短期間でモデルを構築できるようにした。
NTTデータは、ドメイン特化BERTモデルの性能を評価するため、金融系資格試験に解答するタスクを用いて検証した。汎用モデルであるNTT版BERTや、NTTデータが2020年7月に構築した金融版BERTモデルと比べても、ドメイン特化BERT-FWで構築したモデルは高精度であることが確認できたという。
モデルの構築期間については、性能の検証に用いた言語モデルの場合、金融版BERTモデルの構築に29日かかったのに対して、ドメイン特化BERT-FWを用いたモデルは8日で構築を終えている(図2)。また、自動化による副次効果として、業務有識者(ユーザーなど)による作業が不要となった。
 図2:ドメイン特化BERT-FWによるモデル構築期間短縮のイメージ(出典:NTTデータ)
図2:ドメイン特化BERT-FWによるモデル構築期間短縮のイメージ(出典:NTTデータ)拡大画像表示
●Next:NTTデータが取り組む、業界に特化したBERTの開発に至る経緯
会員登録(無料)が必要です


- 1
- 2
- 次へ >




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
