[市場動向]
SMBC、架空の不正取引データを量子アニーリングで生成してAIモデルを学習
2021年3月22日(月)日川 佳三(IT Leaders編集部)
三井住友フィナンシャルグループ(SMFG)、日本総合研究所(日本総研)、NECの3社は2021年3月22日、金融取引の不正を検出するAIモデルにおいて、学習用のサンプルが少ない不正取引データを量子アニーリングで生成する検証を実施したと発表した。不正取引の再現率を比較した結果、再現率がランダムより6~15%、従来手法のSMOTEより3~6%程度向上することを確認した。
三井住友フィナンシャルグループ(SMFG)、日本総研、NECは、2020年2月から共同で、量子アニーリングの実用性を検証している。
検証テーマの1つが、マシンラーニング(機械学習)への応用である。サンプルが少ない学習用データを、量子アニーリングによって生成する使い方である。
「金融取引における正常/不正を識別するAIモデルを構築する際には、正常に取引が行われた学習データ(負例データ)と、不正が行われた学習データ(正例データ)が必要になる。しかし、不正の事例は実際にはほとんど存在しないことから、正例データは少量しか取得できない。この問題への対処法の一種として、実際の正例データを基に「実在しないが確からしい」正例データを大量に生成する操作(オーバーサンプリング)を行うことがある」という。
今回の検証では、規則性のない数値を生み出せるという量子アニーリングの特性を活用し、統計的に確からしい正例データ生成器を開発し、これを用いてオーバーサンプリングを実施した。
量子アニーリングで不正データの再現率が3~6%向上
不正取引を識別するAIモデル(主にデータの分類に用いる決定木と呼ぶモデル)の学習に、オーバーサンプリングしたデータを適用した。この結果、従来手法(「ランダム」および「SMOTE」)と比較して不正データの再現率が向上することを確認した(図1)。
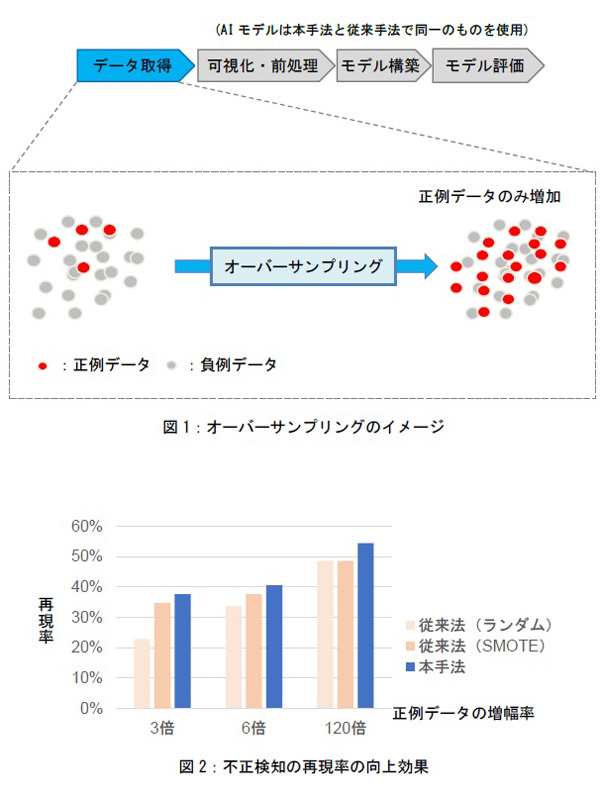 図1:サンプルが少ない不正取引データを量子アニーリングで生成した。従来の生成手法と比べて不正取引データの再現率が向上した(出典:三井住友フィナンシャルグループ、日本総合研究所、NEC)
図1:サンプルが少ない不正取引データを量子アニーリングで生成した。従来の生成手法と比べて不正取引データの再現率が向上した(出典:三井住友フィナンシャルグループ、日本総合研究所、NEC) 量子アニーリングを用いたオーバーサンプリング手法は、正例データをボルツマン分布と呼ぶ確率分布で再現する手法である。ボルツマン分布は確からしいデータを生成するために利用する。今回、正例データの生成時に量子アニーリングを適用している。
従来手法の1つ、ランダムは、「複数存在する正例データから、いくつかの正例データをランダムに選び、これらをそのまま複製する形で新たなデータを生成し、正例データに加える手法」である。
従来手法の1つ、SMOTE(Synthetic Minority Over-sampling TEchnique)は、「複数存在する正例データから、類似した正例データを2件選び、これらの中間的な特徴を持つ新たなデータを生成し、正例データに加える手法」である。
なお、検証は、2020年9月から2020年12月まで実施した。検証環境として、カナダD-Wave Systemsの量子アニーリングマシンなどを使った。取引データには、海外クレジットカード会社における実際の取引履歴から作られた公表データを利用した。




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
