IoT(Internet of Things:モノのインターネット)が現在、注目キーワードであることは間違いない。だが、それと引き替えに、ビッグデータの分析・活用が、どこかへ行ってしまうとしたら問題だろう。IoTとビッグデータは表裏一体の関係にあり、それはモバイルなども同じ。ITで経営や事業に貢献するにはビッグデータの分析・活用が必須だ。では、ビッグデータの分析・活用にどう取り組めばいいのか−−。こうした問いかけに答えようと、データ専門企業のランドスケープが2015年4月下旬、米Googleのエンジニアを含む著名な専門家を招いて“ビッグデータ分析の今”を伝えるセミナーを開催した。
当時開発されたのが、「MapRuduce」と「GFS」と「BigTable」である。MapRuduceとGFSは2001年、Hadoopに発展、BigTableは2004年、Hbaseにつながっていく。
当然、Googleはそこに留まっているわけではなく、現在では大量のログデータを処理する「Flume」や、SQLで大量のデータを処理する「Dremel」、GFSの後継技術である「Colossus」、そして地球規模でデータを複製できるリレーショナルなデータベース「Spanner」へと受け継がれている。
 図2:Anysize Dataを扱うためのGoogle Cloud Platformのサービス
図2:Anysize Dataを扱うためのGoogle Cloud Platformのサービス拡大画像表示
これらの技術は、それぞれが興味深いが、ここまでは前置き。「今やビッグデータを超え、エニーサイズデータ(Anysize Data)を扱う必要がある。ビッグかどうかは問題ではない。Googleのサービスは、Anysize Dataを処理できる」という話が本題である。Anysize Dataを処理するツール(サービス)は存在するのだから、どう処理するのかのプランが大事というわけである(図2)。
 図3:データから気づきを得るための5つのステップ
図3:データから気づきを得るための5つのステップ拡大画像表示
具体的なプランとして示すのが、図3の「5 steps to data enlightment(データから気づきを得るための5つのステップ)である。一見、当たり前のことが並んでいるように思えるが、1つひとつが深い示唆を含んでいる。
各ステップをJordan Tigani氏は、2014年に開催された2014 FIFAワールドカップの予測を例に解説した。ちなみに、同ワールドカップでGoogleは、決勝トーナメント16戦の勝敗を確率で予測。16戦中14戦を的中させている。
データソースには、世界のサッカーリーグのデータを取得・提供するOpta Sportsのものを使った。「Optaは大量のスコアラーを動員し、個々の試合、個々の時間における選手の位置、ゴールキーパーの動きなどをデータ化している」。データ量は数1000試合、数百万件のプレーデータとビッグデータとは言えないが、Anysize Dataなので、そのこと自体は何の問題もない。そこから試合運びや得点の傾向を明らかに、予測モデルを作ることが重要だ。
生データを”クリーン”に使えるように加工
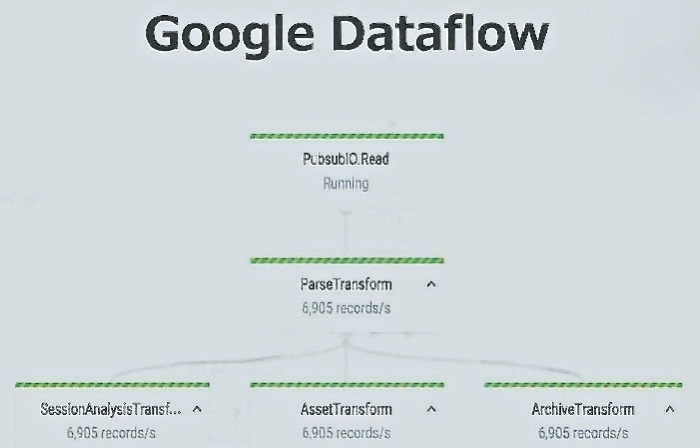 図4:Google Dataflowを使ったデータ加工
図4:Google Dataflowを使ったデータ加工拡大画像表示
この点で大事だったのはデータ加工のステップだという。「Optaのデータが使い勝手がいいとは限らない。それをクリーニングしたり、使いやすくなるように加工したりするために、分析全体の40%を費やした」。この段階で、そのほかのデータ、例えばTwitterのデータも取り込む。加工にはGoogle Dataflowを使っている(図4)。「Dataflowを使えば、簡単なコード(プログラム)を書くだけでクリーニングなど高度な処理ができる)。
Google Cloud / アナリティクス / BigQuery / Bigtable / Spanner




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
