日本弁理士会は2017年11月15日、都内で説明会を開き、マシンラーニング(機械学習)などの人工知能(AI)と著作権の関係について、現状の課題を解説した。学習用データ、学習済みモデル、AI生成物というの要素とプロセスごとに、著作権法との適合性や法改正の動きなどについて説明した。
「機械学習においては、学習用データ、学習済みモデル、AI生成物という3つの要素が存在する。学習用データを集めてきて、これを学習させて学習済みモデルを生成する。こうして生成した学習済みモデルを使って、AIに成果を生成させる。こうしてAI生成物ができる」(日本弁理士会)
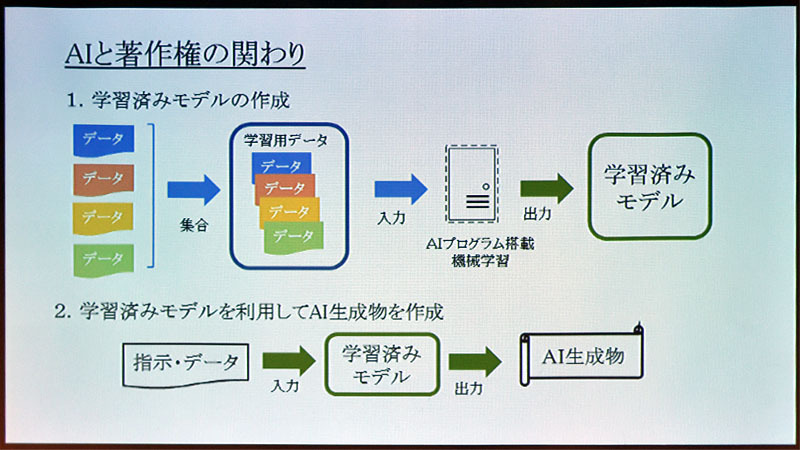 図1:機械学習の3つの要素(学習用データ、学習済みモデル、AI生成物)と著作権の関係を考える(出典:日本弁理士会)
図1:機械学習の3つの要素(学習用データ、学習済みモデル、AI生成物)と著作権の関係を考える(出典:日本弁理士会)拡大画像表示
「要素の1つ目である学習用データとしては、世の中にある著作物を複製して利用しても構わない」と同会。著作権法47条の7に、コンピュータによる情報解析のためであれば、必要と認められる限度において、著作物を記録して複製できるという旨が書かれているという。
バックエンドで行われる著作物の蓄積などは権利を制限
 写真1:日本弁理士会著作権委員会委員長の大沼加寿子氏
写真1:日本弁理士会著作権委員会委員長の大沼加寿子氏拡大画像表示
日本弁理士会著作権委員会委員長の大沼加寿子氏は、AIと著作権における論点の1つとして、著作物を含んだ学習用データを作成した人から、学習済みモデルを作成する人に対して、学習用データを提供することが著作権上問題になるかどうか、という視点を提示した。
「特定の当事者間で学習用データを受け渡した場合には適法だということになったとしても、どのみち不特定多数に渡したら違法になる。この一方で、不特定多数で学習用データを共有すれば学習効率が上がる、という見方がある」(大沼氏)
この論点に対しては、情報システムのバックエンドで行われる著作物の蓄積といった、著作物の表現の知覚を伴わない利用行為などは、権利者の利益を害するものではないことから、権利を制限するなど法改正の方向で動いているという。
AI生成物が学習用データの著作権を侵害する可能性
学習モデルによって生成するAI生成物について大沼氏は、「AIを道具として利用して作った創作物については、作者の著作物になる。一方、人が関与せずにAIが自律的に創作したAI生成物は、著作物ではない」と説明した。
大沼氏は、AIを道具として利用して作った創作物における論点の1つとして、学習済みモデルのベースとなった学習用データに含まれる世の中の著作物と、AIを道具として利用して作った創作物が似ているかどうかという点を提示した。
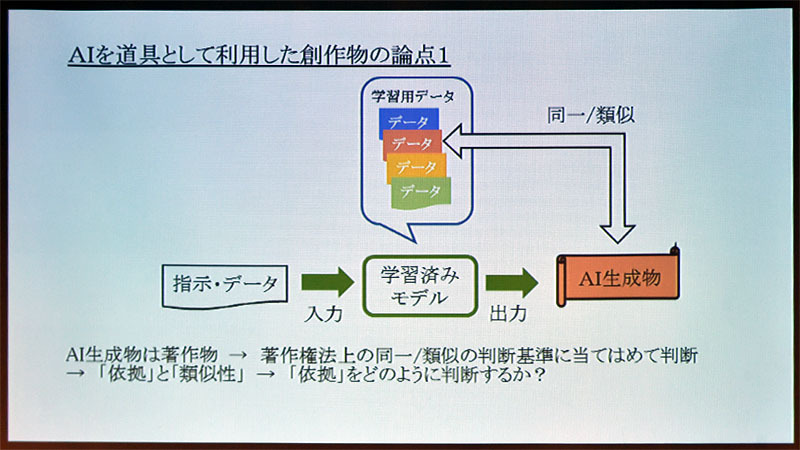 図2:学習用データに含まれる著作物と、AIを道具として利用して作った創作物が似ている場合がある(出典:日本弁理士会)
図2:学習用データに含まれる著作物と、AIを道具として利用して作った創作物が似ている場合がある(出典:日本弁理士会)拡大画像表示
「特に、AIを道具として利用して創作物を作成した人が、学習済みモデルの作成者とは異なっている場合、創作物の作者は、学習済みモデルに含まれているデータのすべてを把握できているわけではない」(大沼氏)
「学習済みモデルによっては、学習用データの表現をそのまま内部に保持するものもあれば、パラメータ化して抽象化したデータを保持するものもある」(同氏)。パラメータ化したデータを使っている場合は、表現ではなくアイディアを利用しているだけに過ぎないので問題ないという見方もあるとした。
AIを道具として利用して作った創作物の論点としてはまた、著作権侵害と認められた場合の責任を誰が負うのか、というものもあると大沼氏は指摘する。
人が関与せずにAIが自律的に生成した創作物を保護するか
大沼氏は、人が関与せずにAIが自律的に創作したAI生成物に関する論点も挙げた。まず、人が関与していないため、現行の著作権法では権利の対象とならない。この上で、AI生成物を法律で保護するかどうかという論点があるという。
「例えば、AIが生成した創作物を、人が創作した著作物であると偽って市場に流す人が出てくることが考えられる。この場合、AIは人に比べて生産性が高いため、大量のコンテンツが生み出される可能性がある」(大沼氏)



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
