[技術解説]
いまさら聞けないGPUの基礎と、“ニューノーマル時代のAI基盤”としての最新動向
2020年7月3日(金)塚本 祐子(マクニカ クラビスカンパニー ストラテジックマーケティング部長)
今日、AIと言えばディープラーニング(深層学習)であり、それを高速に実行するためのテクノロジーがGPU(Graphics Processing Unit)です。では、なぜGPUがAI/ディープラーニングに適するのか? そして、最新のGPUテクノロジーはどんな性能を備えているのか? そんな、いまさら聞けないGPUの基礎と最新動向を、最大手のNVIDIA(エヌビディア)が毎年開催するプライベートコンファレンス「GPU Technology Conference 2020」からの発表も引用しつつ、GPUの最新事情を平易に解説する。
コロナ禍で活用が広がるAI、それを支えるのがGPU
新型コロナウイルス感染症(COVID-19)のパンデミック以降、AI(人工知能)への注目が以前よりも増しています。例えば、米国疾病管理センター(CDC)の警告よりも早い2019年12月31日の時点で、カナダ・トロントに本拠を置くブルードット(BlueDot)が「新型ウイルスにアウトブレイクの兆しがある」と警告したことが話題になりました。同社は健康モニタリングプラットフォームを提供しており、データ分析にAIを活用しています。
コロナ禍の中で、ほかにも、スーパーマーケットの入店規制やオフィス、公共施設などでのソーシャルディスタンス確保を目的とした混雑予測、レントゲンやCTの医療画像解析へのAI利用は世界各地で行われています。日本でも、厚生労働省がCOVID-19に関係する医療機器として、AIを用いた肺画像解析プログラムを承認したことが話題になりました。
AIというと大がかりで複雑、そして多額の費用がかかる高度なソリューションという印象を持たれるかもしれませんが、ウィズコロナやアフターコロナを見据えて応用範囲の拡大が加速しており、いわゆる“ニューノーマル時代”にはなくてはならない存在になろうとしています。
それを支えるのが、現在のAIの主流であるディープラーニング(深層学習)を高速に処理するプロセッサであるGPUとその急速な進歩です。本記事では知っているようで意外に知らない、今さら聞くに聞けないGPUについて、AIの視点から基礎と最新事情を解説していきたいと思います。
数千個のコアを搭載し、大規模並列処理を実行するGPU
「そもそもGPUとは?」から始めましょう。Graphics Processing Unitの略で、3次元(3D)グラフィックスなどの画像を作成・処理する際の演算を行う半導体プロセッサを指します。3Dグラフィックスでは2次元(2D)の画像に陰影や奥行きを付与して3D的に表現したり、それを連続して行ったりすることで動きを表現します。このとき、画像を構成する個々の画素の値を同時並列で高速に計算しなければなりませんが、これを行うのがGPUであり、並列計算を得意としています。
これに対し、一般的なPCやスマートフォンなどに搭載されているCPUが一度に処理するのは1つのデータです。現在のCPUは高性能なので複雑な計算でもあっという間に終わりますが、1つずつ順番にデータを処理していることは昔から変わりません。表計算や文書処理、比較的単純な描画で済む2Dゲームなどを走らせるのにはまったく問題ありませんが、高解像で動きの速い3Dゲームを、CPUだけでこなそうとすると画面の描画処理が間に合いません。このCPUの不得手な高精度のグラフィックス処理を補うのがGPUというわけです。
CPUとGPUの大きな違いが、コア(Core)と呼ばれる演算機構の数です。PCやスマホのCPUではデュアルコア(コア数2)やクアッドコア(コア数4)が典型的なコア数です。先ほど「CPUは順番にデータを処理している」と書きましたが、実際には4コアのCPUなら4つの処理を並列して実行できます。
一方のGPUは、単体のプロセッサに数千個ものコアを搭載しています。並列の度合いが違うわけですね。当然、その“副作用”としてGPUのコアはCPUのそれに比べて単純な処理しかできませんが、画素を計算するだけなのでそれで十分なのです。
ディープラーニングでGPUが必要とされる理由
では、グラフィック処理用のプロセッサであるGPUが、なぜ、現在のAIの処理を支えているのでしょうか。
その理由は現在のAIの主流であるディープラーニング(Deep Learning:DL、深層学習)と相性がとてもよいことにあります。ディープラーニングは人間の神経細胞(Neuron:ニューロン)の仕組みを模したニューラルネットワーク(Neural Network:NN)という計算モデルをベースとしています。神経細胞の動きはいまだよくわかっていないことも多いので「神経細胞の仕組みを模した」というのは少し過剰な表現なのですが、それはともかくこの計算モデルではニューロンにあたるノードを複数、入力層と中間層、出力層に配置し、各層のニューロンをシナプス(Synapse:神経細胞などの接合部位)にあたるエッジで接続します(図1)。
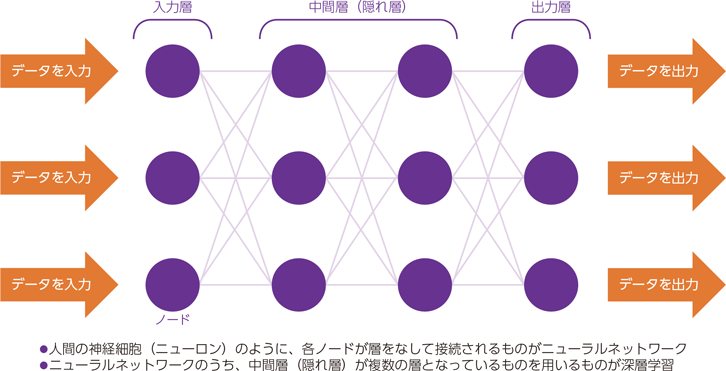 図1:深層学習の仕組み(出典:総務省 令和元年版 情報通信白書)
図1:深層学習の仕組み(出典:総務省 令和元年版 情報通信白書)拡大画像表示
ちなみに、中間層が1つのものをニューラルネットワーク、多層の中間層があると層が深い(deep)ということでディープラーニングと呼ばれます。多いものになると数百の中間層を持つディープラーニングがありますが、各層のノード数(エッジの接続数)や中間層の数に決まりはないし、これらが多ければ高性能になるわけでもありません。直感的に大規模なほうが高度な処理ができそうだということは理解いただけるでしょう。
しかし、中間層の数が多くなると、問題が生じます。ディープラーニングでは、例えば大量の画像データを用いて学習を行いますが、その際、内部的には多くのノードやエッジの値が適切になるように計算を行っています。この計算量が何万、何十万回というように膨大になることがその問題です。1つのノードやエッジの計算は複雑ではありませんが、数が多くなるとCPUでは時間がかかってしまいます。そこで大量のコアを有し、並列で計算できるGPUが広く利用されるようになったのです。
では、GPUの計算能力は今どれほどのものなのでしょうか。GPUはコンピューティングの世界でどれほどの比重を占めるようになりつつあるのでしょう。GPUの最新トレンドを知る1つの機会として、GPUの世界最大手ベンダーである米NVIDIA(エヌビディア)が主催する「GPU Technology Conference(GTC)」というプライベートコンファレンスがあります。GPUの技術動向はもちろん、ディープラーニング、IoTやロボット、自動運転など幅広い領域をカバーする年次イベントです。今年のGTCは新型コロナウイルスの影響からオンラインでの開催になりました。
その基調講演で、NVIDIAのCEO、ジェンセン・ファン(Jensen Huang)氏が披露したのが、次に説明する次世代GPUです。なお今回、オンライン開催ということでファン氏は自宅から講演したのですが、よくある書斎やリビングルームではなく、キッチンからでした。何かを生み出す場所であることを伝えようとしたのかもしれません(笑)。
次世代GPUはディープラーニングに特化した演算器を搭載
ファン氏が基調講演で発表したのは、GPUを次のステップへと押し上げる新しいアーキテクチャ「Ampere(アンペア)」とそれに基づく新GPU「NVIDIA A100」です。CPUもそうなのですが、GPUも数年に一度アーキテクチャ=基本設計が新しくなります。現行のアーキテクチャは2017年に発表された「Volta(ボルタ)」であり、GPUとしての製品名は「NVIDIA V100 Tensor コア GPU」です。NVIDIA V100では、「CUDA」コアと呼ばれる汎用のグラフィック/AI演算用途の並列演算器に加えて、初めて「Tensor」コアと呼ばれるディープラーニングに特化した演算器が加わりました(図2)。
いきなり難しくなった印象を持たれるかもしれませんが、実はそれほど難解な話というわけではありません。Voltaより前はCUDAコアだけを搭載したGPUでした。3Dグラフィック処理用に設計されたコアを搭載したGPUをディープラーニングに転用していたわけですから、必ずしも処理効率がよくない面があるのは当然です。そこでVoltaではディープラーニングに特化したTensorコアが追加搭載され、従来は数週間かかっていた学習を数時間に短縮し、推論性能も大幅に向上しました。
 図2:GPUアーキテクチャの変遷(出典:マクニカ)
図2:GPUアーキテクチャの変遷(出典:マクニカ)拡大画像表示
では、Voltaを発展させたAmpereは、どんな特徴を持っているのでしょうか。新GPUは正しくは「NVIDIA A100 Tensor コア GPU」と呼ばれ、Tensorコアを搭載する点は同じです。違うのは「TF32」と呼ぶ、FP32(単精度浮動小数点数)とFP16(半精度浮動小数点数)のハイブリッド方式でFP32演算を行える仕組みを採用したことです(図3)。これによりソフトウェアを修正することなく、ディープラーニングの処理性能を20倍に高めたとNVIDIAはアピールしています。
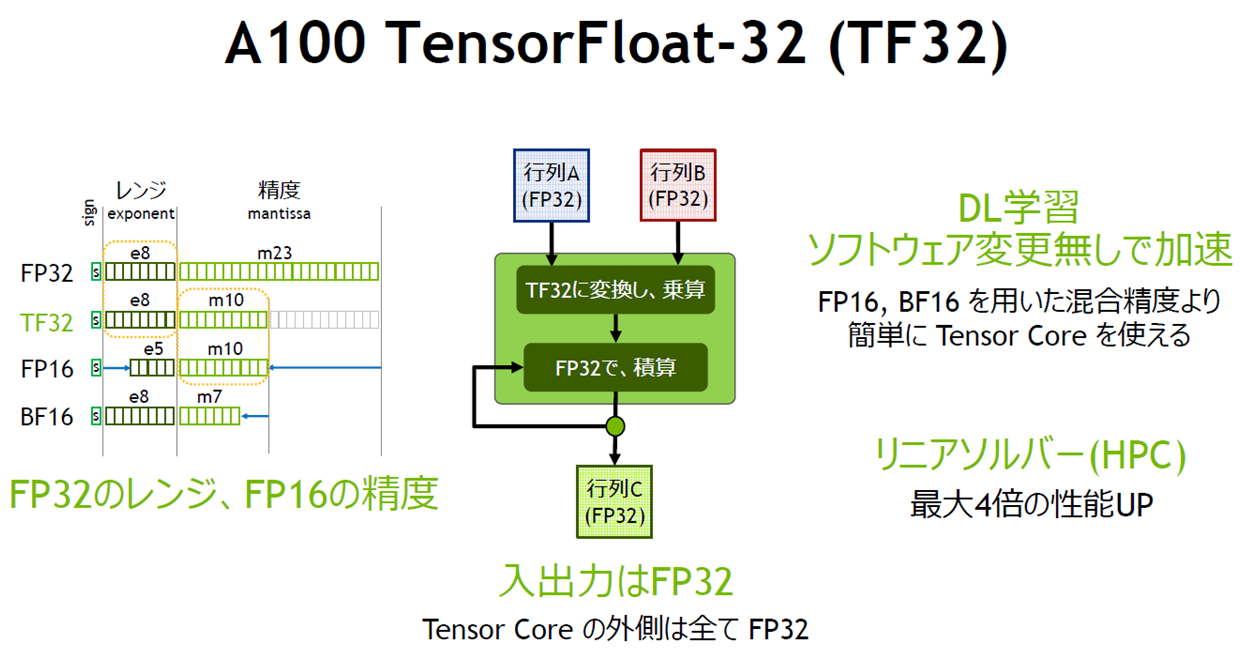 図3:A100 TensorFloat-32 のハイブリッド方式(出典:NVIDIA)
図3:A100 TensorFloat-32 のハイブリッド方式(出典:NVIDIA)拡大画像表示
簡単に説明すると、FP32は32ビットの長さを持つデータを演算処理します。32ビット=2の32乗=42億という非常に大きな値を表現できますが、ディープラーニングで扱う値は実のところ、これほどの値が不要である場合が多いです。FP16=2の16乗=6万5000でも問題ありませんし、処理するデータが小さくなりますから、その分処理性能を高められます。そこで、TP32ではソフトウェアからはFP32であるように見えながら、内部ではFP16で処理することで性能を飛躍的に高めているのです。
余談になりますが、NVIDIA A100はこういった機能を搭載しながら、プロセッサの面積(ダイサイズ)は826平方mm(3cm×3cm弱)と、Voltaとほぼ同等のサイズです。そこに540億ものトランジスタを集積するために、7nm(ナノメートル)という最先端のプロセスで製造されています。AmpereのNVIDIA A100はすでに量産に入っていて、皆さんも今後この名前を聞く機会が増えると思います(図4)。
 図4:NVIDIA Ampereアーキテクチャの特徴(出典:NVIDIA)
図4:NVIDIA Ampereアーキテクチャの特徴(出典:NVIDIA)拡大画像表示
●Next:新サーバー「DGX A100」がディープラーニング処理にもたらすインパクトは?
会員登録(無料)が必要です


- 1
- 2
- 次へ >



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
