NTTテクノクロスは2021年11月12日、音声認識ソフトウェア「SpeechRec Server(スピーチレック サーバー)」の新版を発表した。同年11月19日から販売する。新版では、これまで一部の音声情報処理だけに適用していたディープニューラルネットワーク(DNN)を音声データ入力からテキスト出力までエンドツーエンドで適用する。これにより、人間の脳と同じような処理体系で音声から日本語を理解できるようになり、音声認識精度が向上している。価格は要問い合わせ。
NTTテクノクロスの「SpeechRec Server」は、多言語に対応した(日本語、英語、北京語、広東語、台湾語、韓国語、タイ語、ベトナム語、インドネシア語、マレーシア語)音声認識ソフトウェアである。
Webサーバー/クライアント間の双方向通信プロトコルであるWebSocket APIを介して、アプリケーションに音声認識機能を提供する。IVR(自動音声応答)システムとの連携に用いるMRCP(Media Resource Control Protocol)プロトコル(MRCPv2)にも対応している。
新版の特徴として、音声情報処理に、メディア処理AI技術「MediaGnosis」のエンドツーエンド方式(注1)での採用を挙げている。MediaGnosisは、NTTコンピュータ&データサイエンス研究所が開発した、音声音響処理や自然言語処理などの情報処理を人間の脳と同じように処理する技術である。
SpeechRec Serverでは、これまで一部の音声情報処理のみに適用していたディープニューラルネットワーク(DNN)を、音声データ入力からテキスト出力までエンドツーエンド(一括)で適用する。人間の脳と同じような処理系統で音声から日本語を理解できるようになり、音声認識精度が向上している(図1)。
注1:従来は音響モデルや認識辞書、言語モデルなど複数の処理を組み合わせるハイブリッド方式だったが、エンドツーエンド方式ではそれらの処理をDNNにより一括で行うことが可能になる
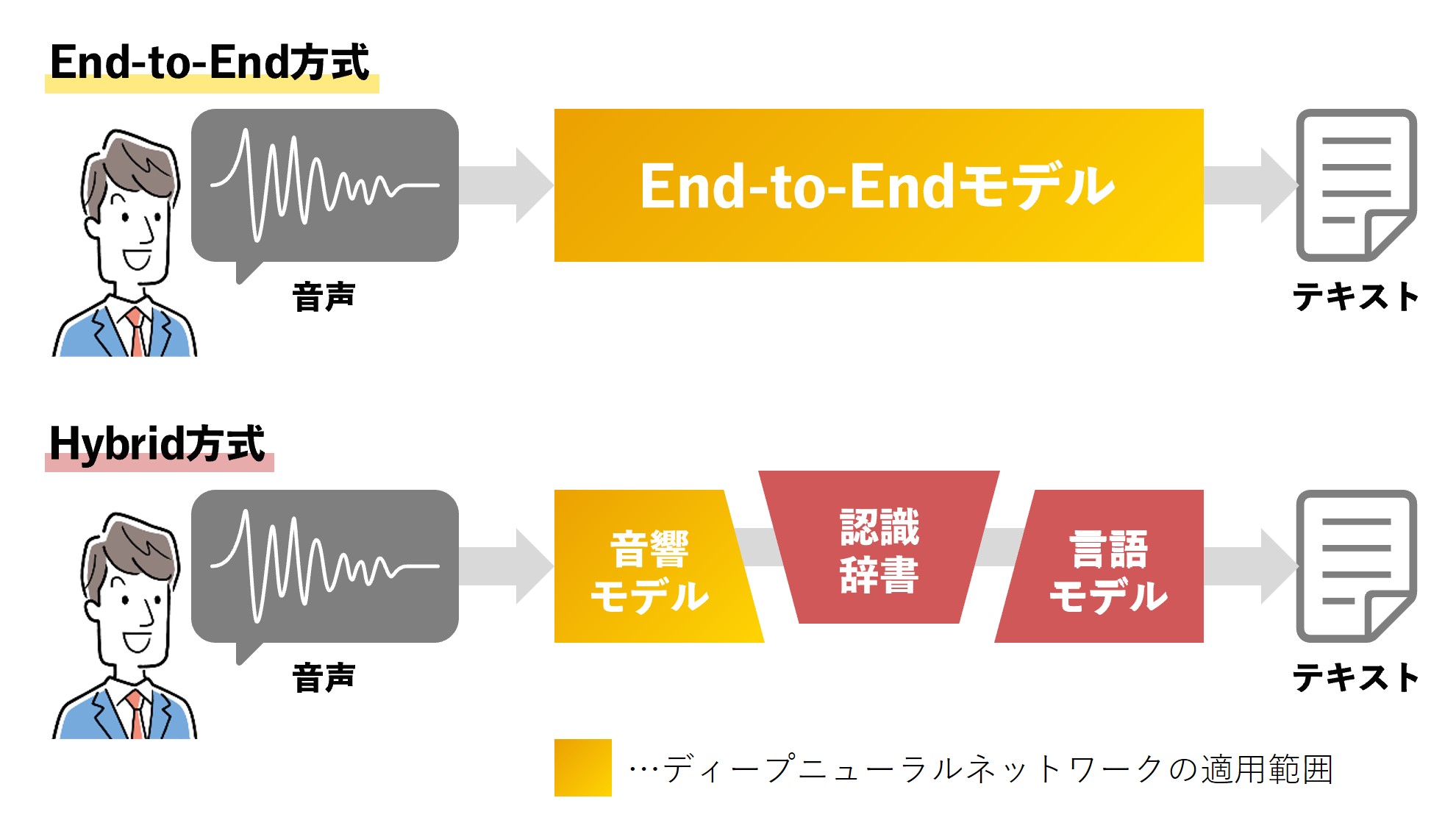 図1:AI技術「MediaGnosis」を採用し、ディープニューラルネットワークを、音声データ入力からテキスト出力までエンドツーエンドで適用できるようになった。音声認識精度が向上した(出典:NTTテクノクロス)
図1:AI技術「MediaGnosis」を採用し、ディープニューラルネットワークを、音声データ入力からテキスト出力までエンドツーエンドで適用できるようになった。音声認識精度が向上した(出典:NTTテクノクロス)拡大画像表示
新版では、音声の特徴から話者を識別する話者ダイアリゼーション機能も利用できるようになった。複数の話者が話す場合でも、話者を識別するために話者の音声を事前登録したり、話者ごとにマイクを分けたりする必要がない。話者の声質や波形などの特徴からMediaGnosisが自動で話者を識別する(図2)。
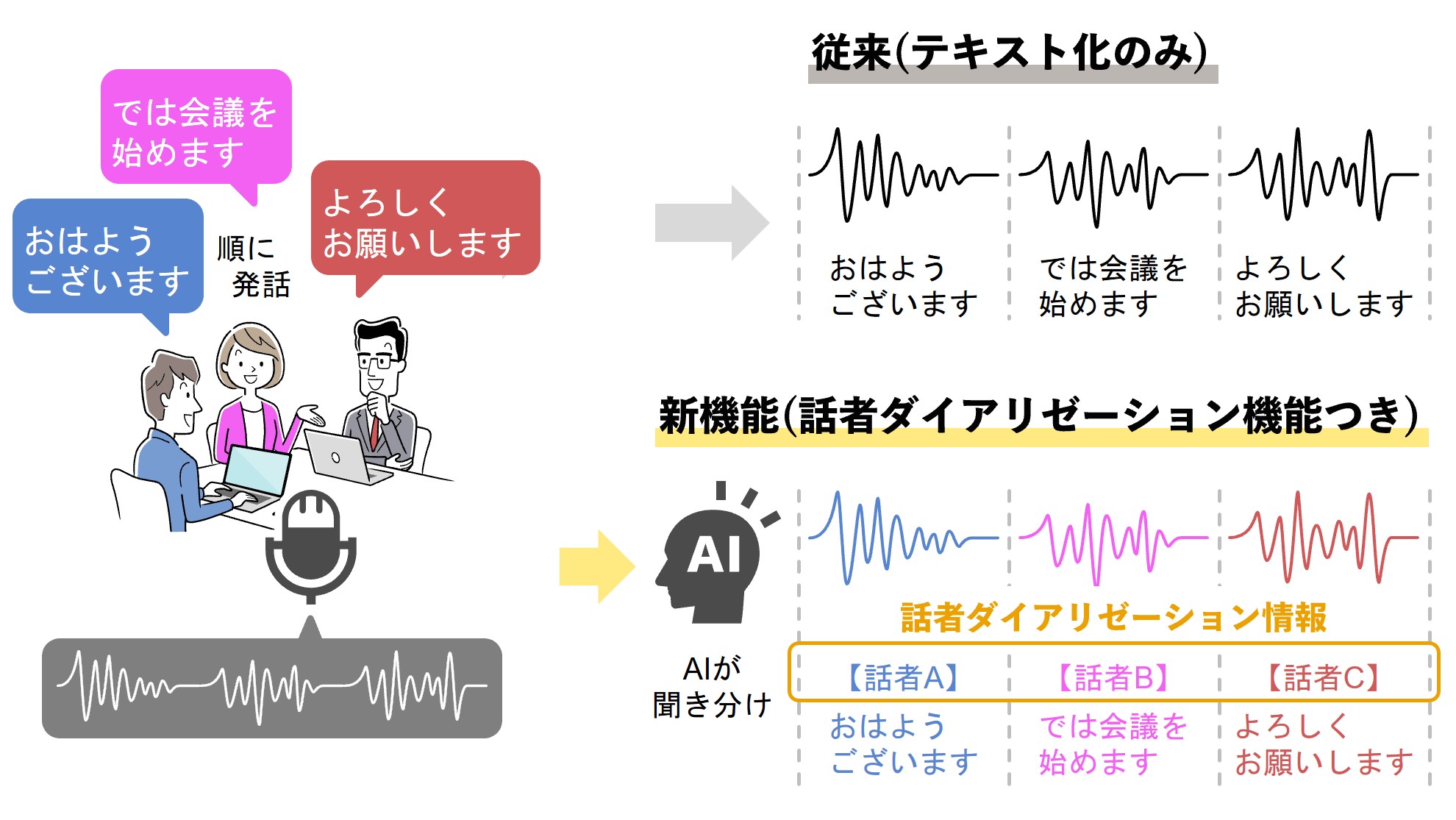 図2:AI技術「MediaGnosis」の採用によって、話者を識別できるようになった(出典:NTTテクノクロス)
図2:AI技術「MediaGnosis」の採用によって、話者を識別できるようになった(出典:NTTテクノクロス)拡大画像表示
新版ではさらに、話し言葉を読みやすく変換し、内容を分類できるようになった(図3)。話し言葉の変換では、相づちや「えー」、「あのー」などのつなぎ言葉に加え、「私なんかは」などの話し言葉特有の表現を認識し、話の意味を理解しやすいようなテキストに変換する。内容の分類では、テキスト化した情報を、質問文と回答文のように、内容ごとに分類して表示できる。
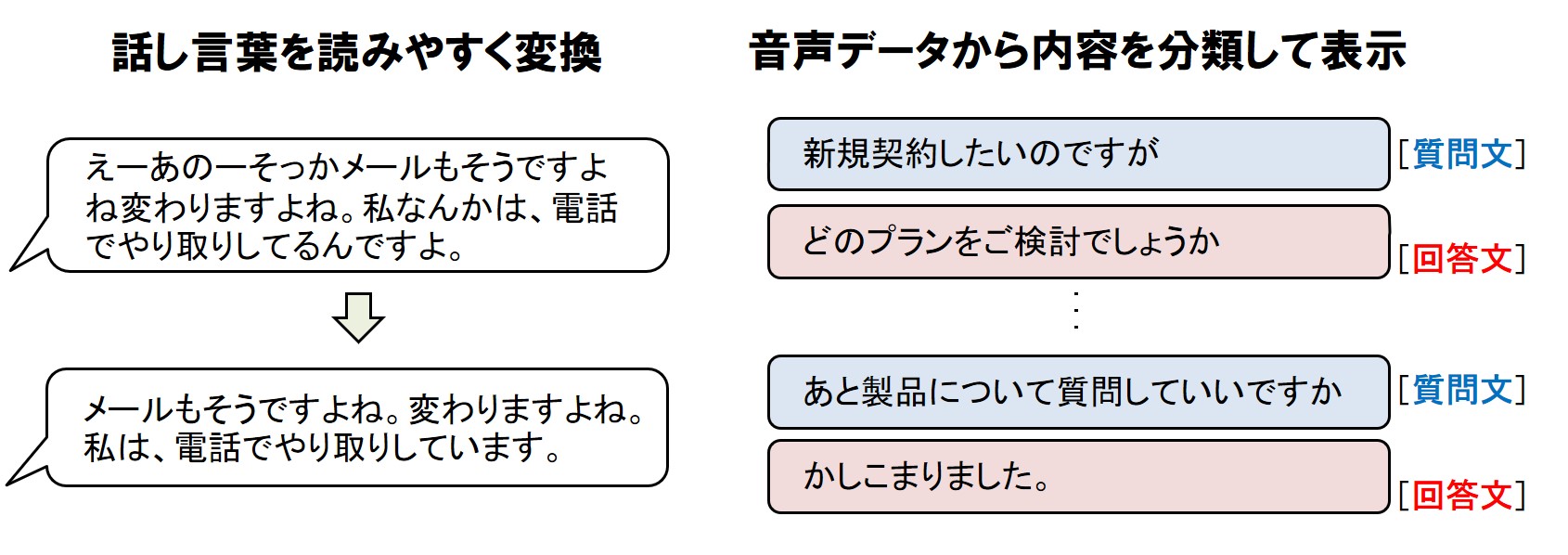 図3:AI技術「MediaGnosis」の採用によって、話し言葉を読みやすく変換し、内容を分類できるようになった(出典:NTTテクノクロス)
図3:AI技術「MediaGnosis」の採用によって、話し言葉を読みやすく変換し、内容を分類できるようになった(出典:NTTテクノクロス)拡大画像表示
NTTテクノクロス / SpeechRec Server / 音声認識 / ディープニューラルネットワーク / コンタクトセンター / コールセンター / MediaGnosis




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
