[新製品・サービス]
エクサウィザーズ、画像の内容を対話型で説明する生成AIモデル「exaBase Visual QA」
2023年9月20日(水)日川 佳三、河原 潤(IT Leaders編集部)
エクサウィザーズは2023年9月20日、生成AIモデル「exaBase Visual QA」を開発したと発表した。画像の内容を対話型で説明する生成AIモデルで、例として、建設現場の作業員を撮影した写真を見せて、何が危険なのかを文章で説明させる使い方を挙げている。現時点ではPoC(概念実証)用途で提供する。当初は静止画を対象とするが、動画での活用も可能である。
エクサウィザーズの「exaBase Visual QA」は、画像の内容を対話型で説明する生成AIモデルである。ソフトウェアやシステムに組み込んで使う。現時点では、PoC(概念実証)用途で提供する。当初は静止画を対象とするが、動画での活用も可能である。
exaBase Visual QAは、オープンソースの生成AIモデルをベースに、エクサウィザーズが追加学習を行って構築している。個別の分野のデータを学習して設定を調節するファインチューニングを同社が行い、特定分野での精度を向上させることも可能という。
exaBase Visual QAを実装したシステムと、チャットボットのように対話することで、画像の状況を説明する文章を生成する。解釈した意味・内容に基づいてデータを振り分ける「分類モデル」としての利用も可能である。主な活用例として以下を挙げている。
- 建設現場などでの作業における危険性の判定
- 育園や学校など多様な人の動きがある場所での状況把握
- 各種の対象における故障場所の把握や内容分析
- カメラやセンサーなどの画像に対する事件や事故の把握
- 大量動画の文章化、特定の場面を抜き出すことでのデータ圧縮
- 製品ラインなどで合否を判定する分類モデルの構築
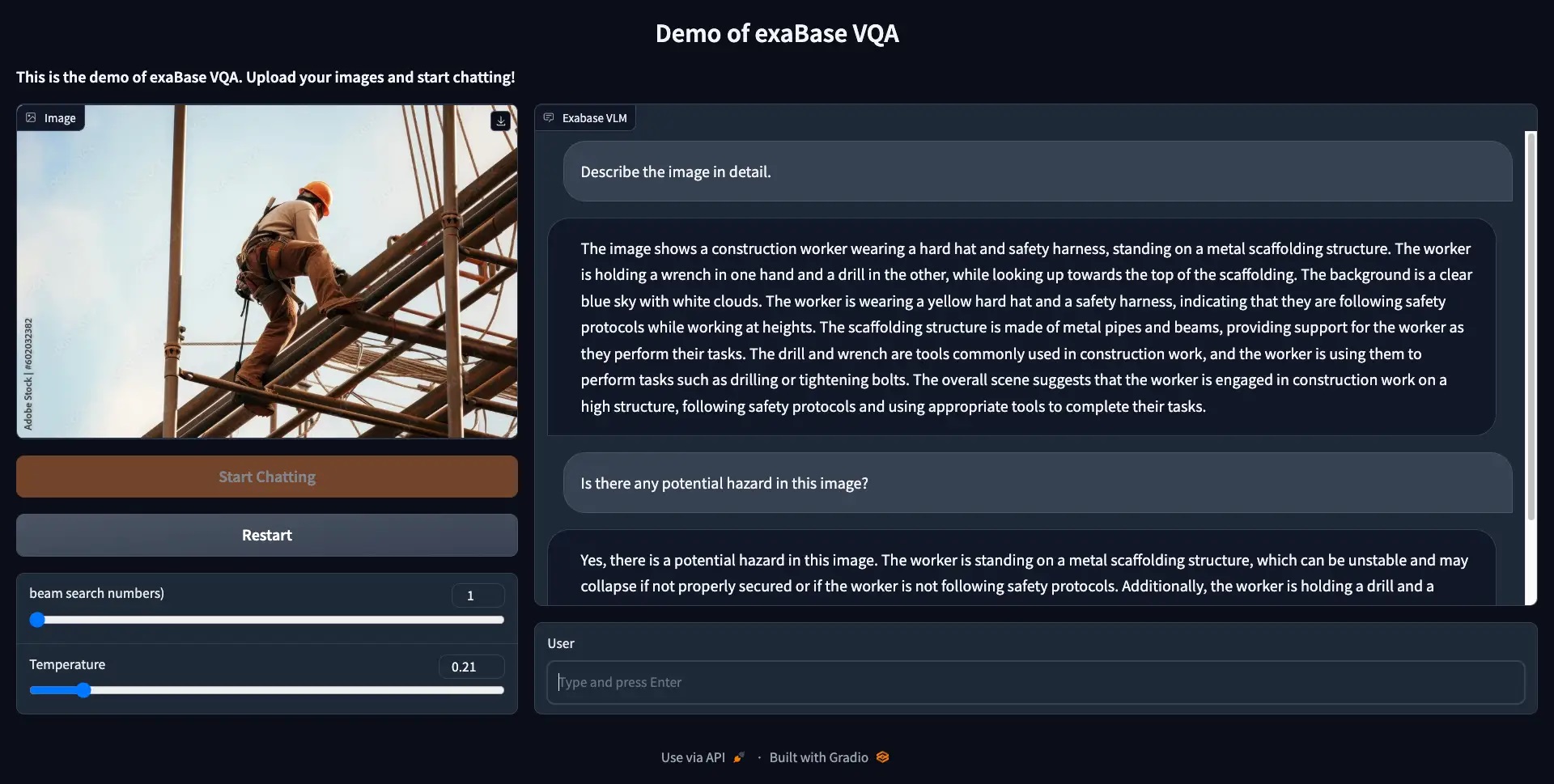 画面1:exaBase Visual QAのプロトタイプ画面。建設現場の写真から何が危険かを説明させている(出典:エクサウィザーズ)
画面1:exaBase Visual QAのプロトタイプ画面。建設現場の写真から何が危険かを説明させている(出典:エクサウィザーズ)拡大画像表示
「画像を認識する一般的な生成AIモデルでは、複雑な画像について内容を的確に文字情報として出力するのが難しい。そこで、『人が画像を見た時に、どこに注目するのか』を生成AIモデルに学習させることに取り組んだ」と説明している。その結果、人が直感的に認識可能な、画像内の危険性や違和感といった状況を高精度で解釈可能になった。
画面1は、exaBase Visual QAのプロトタイプ画面である。「建設現場の作業員を撮影した写真を見せて、何が危険なのかを文章で説明させる」使い方を示している。
建設現場の作業員を撮影した写真に対し「潜在的な危険性はありますか」と入力したところ、「作業員がバランスを崩したり足場が崩れたりすると落下事故につながる。作業員は電動工具を使用しており、工具が滑って負傷する可能性がある。適切な安全予防措置を講じるべきである」と回答した。システム実装時には長文を出力するが、ChatGPTを用いて要約可能である。
なお、同社での評価実験では、他の商用利用可能なモデルと比べて最大で1割弱高い解釈の精度を持つことを確認したという。同様の精度のモデルと比べてモデルのサイズも小さく、推論の実行や生成速度も高速だとしている。



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
