ペンギンソリューションズ(旧称は日本ストラタステクノロジー)は2026年6月24日、大規模AI推論用の「MemoryAI KVキャッシュサーバー」を発表した。4Uラックマウントの筐体に11TBのメモリーを積んだストレージキャッシュ装置であり、LLMが推論時に生成するトークンのKV(キーバリュー)キャッシュを外部ストレージ階層にオフロードする際のI/O性能を高められる。2026年第4四半期に提供を開始する。
ペンギンソリューションズの「MemoryAI KVキャッシュサーバー」は、大規模なAI推論の応答性能を高めるための装置である(写真1)。4Uラックマウントの筐体に11TBのメモリーを積んだストレージキャッシュ装置であり、LLMが推論時に生成するトークンのKVキャッシュを外部ストレージ階層にオフロードする際のI/O性能を高める。
 写真1:「MemoryAI KVキャッシュサーバー」の外観(出典:ペンギンソリューションズ)
写真1:「MemoryAI KVキャッシュサーバー」の外観(出典:ペンギンソリューションズ)拡大画像表示
前提として、LLMの推論では、生成したトークンのKVキャッシュが大量に発生する。例えば、RAG(検索拡張生成)でLLMに渡す情報量が多い場合や、長い対話のやり取りなどでは、KVキャッシュがGPUメモリーを圧迫する。このため、CPU配下のメインメモリーにKVキャッシュを退避させ、必要に応じて再ロードする。それでも容量が足りない場合は退避先としてストレージも使う。
米NVIDIAは、大規模推論時におけるKVキャッシュの運用モデルをNVIDIA Dynamoフレームワークとして公開している(図1)。推論サーバーのローカルSSDだけでなく外部ストレージも使うことで、大容量のKVキャッシュを利用できるようにしている。複数台の推論サーバーでクラスタを組んでKVキャッシュを共有する使い方も想定している。
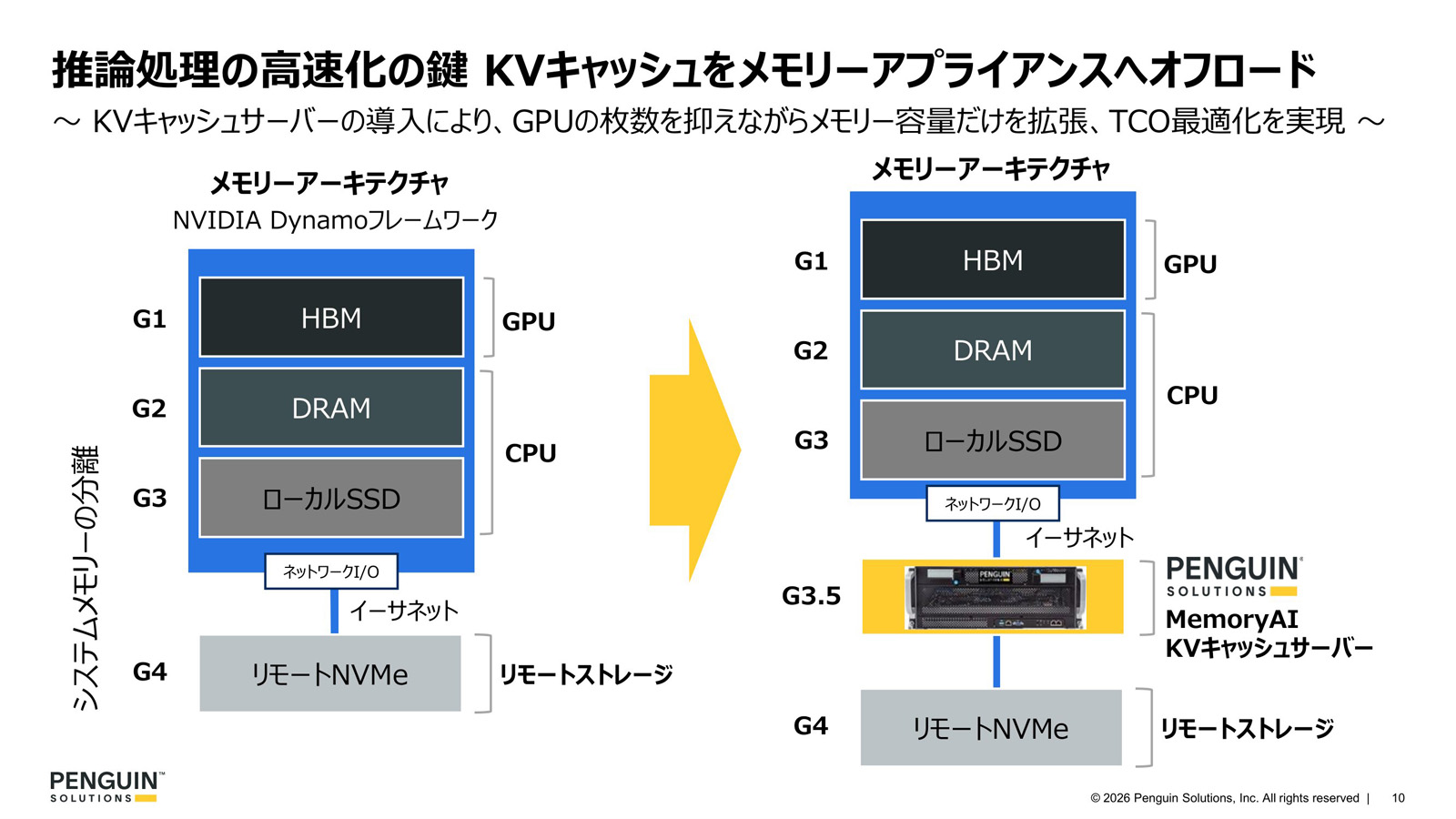 図1:NVIDIA Dynamoの運用モデルとKVキャッシュサーバーの位置付け(出典:ペンギンソリューションズ)
図1:NVIDIA Dynamoの運用モデルとKVキャッシュサーバーの位置付け(出典:ペンギンソリューションズ)拡大画像表示
今回提供するMemoryAI KVキャッシュサーバーは、ローカルSSDと外部ストレージの間に挟まり、外部ストレージをメモリーでキャッシュする。これにより、NVIDIA Dynamoフレームワークにおける外部ストレージをより高速に利用できるようにする。外部ストレージにKVキャッシュを退避させるような大規模推論時において応答性能が高まる。
装置の実態は、4UラックマウントのI/Oボックスに、PCI Expressの物理仕様を流用したインターコネクト規格であるCXL(Compute eXpress Link)接続のメモリーユニット8個を収容し、このうえでKVキャッシュ機能を持つサーバー機を搭載したものである。推論サーバーとはイーサネットまたはInfiniBandで接続する。
CXLメモリー1ユニットには、容量128GBのDIMMを8枚(合計1TB)積んでおり、8ユニットで合計8TBになる(写真2)。サーバー機が3TBのメモリーを積んでいるので、4Uの装置全体では11TBのメモリーをキャッシュ用途に利用できる。
 写真2:CXLメモリーユニットの外観。DIMM×8枚を装着する(出典:ペンギンソリューションズ)
写真2:CXLメモリーユニットの外観。DIMM×8枚を装着する(出典:ペンギンソリューションズ)拡大画像表示
なお、ペンギンソリューションズは、2026年4月に日本ストラタステクノロジーから社名を変更している。米国本社の事業ブランド統合を受けたものであり、これまで販売してきた無停止型サーバーをストラタス(Stratus)ブランドで継続して販売すると同時に、今後はブランド統合先である米ペンギン・ソリューションズの製品(AI用途のGPU搭載サーバーなど)を販売する(関連記事:日本ストラタステクノロジーがペンギン・ソリューションズに社名変更、無停止型サーバーに加えてAI向けGPUサーバーを販売)。




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
