AIの本格導入が進む一方で、「期待通りの精度の回答が得られない」と感じている企業は少なくない。だが、その多くの原因は、AIそのものではなく、AIが参照する“データの質”にある。2026年3月11日に開催された「データマネジメント2026」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)のセッションに、創業以来、数億件規模の名刺データを正確にデータ化し続け、自社プロダクト開発と業務効率化の両面でAI活用を実践してきたSansan株式会社から鳴海佑紀氏、猿田貴之氏が登壇。「AI-Ready Data」を成立させるために欠かせないデータ品質マネジメントの要件を、実践知を交えて解説した。
提供:Sansan株式会社
業務における生成AI活用に不可欠な「企業独自データ」
近年のAI、および生成AIは加速度的に進化している。その有用性を自社の業務に取り入れ変革をもたらす「AIトランスフォーメーション」、すなわち「AX」に多くの企業が取り組んでいることだろう。
こうした取り組みを背景に、多くの企業が生成AIツールを導入し、活用を始めている。しかし、Sansan社の調査によれば、「業務で生成AIを活用する中で、期待通りの成果を得られなかった」と回答した企業は、9割に達している(図1)。
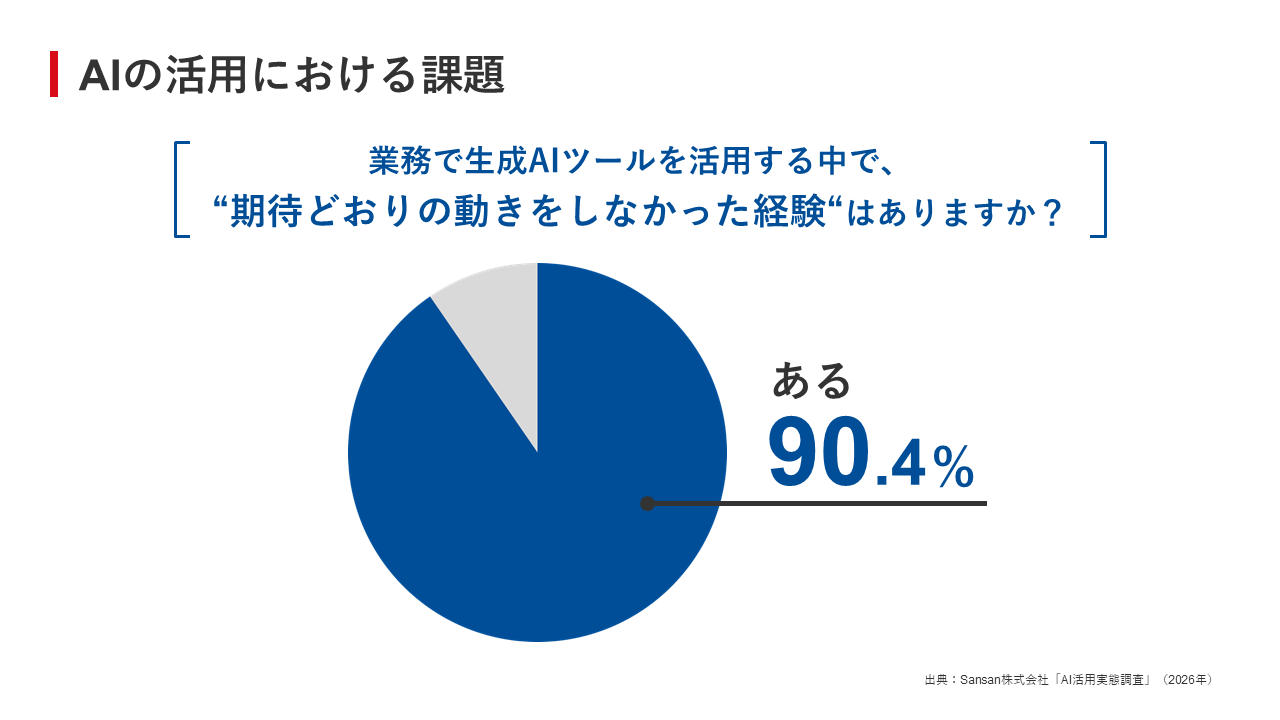 図1:AIの活用における課題
図1:AIの活用における課題拡大画像表示
「生成AIから期待した回答を得るためには、一般に流布されている公開データだけではなく、営業、契約業務、サポート業務など、企業が日々の活動の中で取得してきた独自のデータを学習させる必要があります」と、Sansan社の鳴海佑紀氏は訴える。
 Sansan株式会社 Sansan事業部 SDI推進部 ビジネス統括 鳴海佑紀氏
Sansan株式会社 Sansan事業部 SDI推進部 ビジネス統括 鳴海佑紀氏実際に、先の調査で「人脈、商談内容、契約情報等、企業独自の情報をAIが横断的に活用できたら成果は改善されるか」と聞いたところ、9割を超える企業が「改善される」と回答している(図2)。
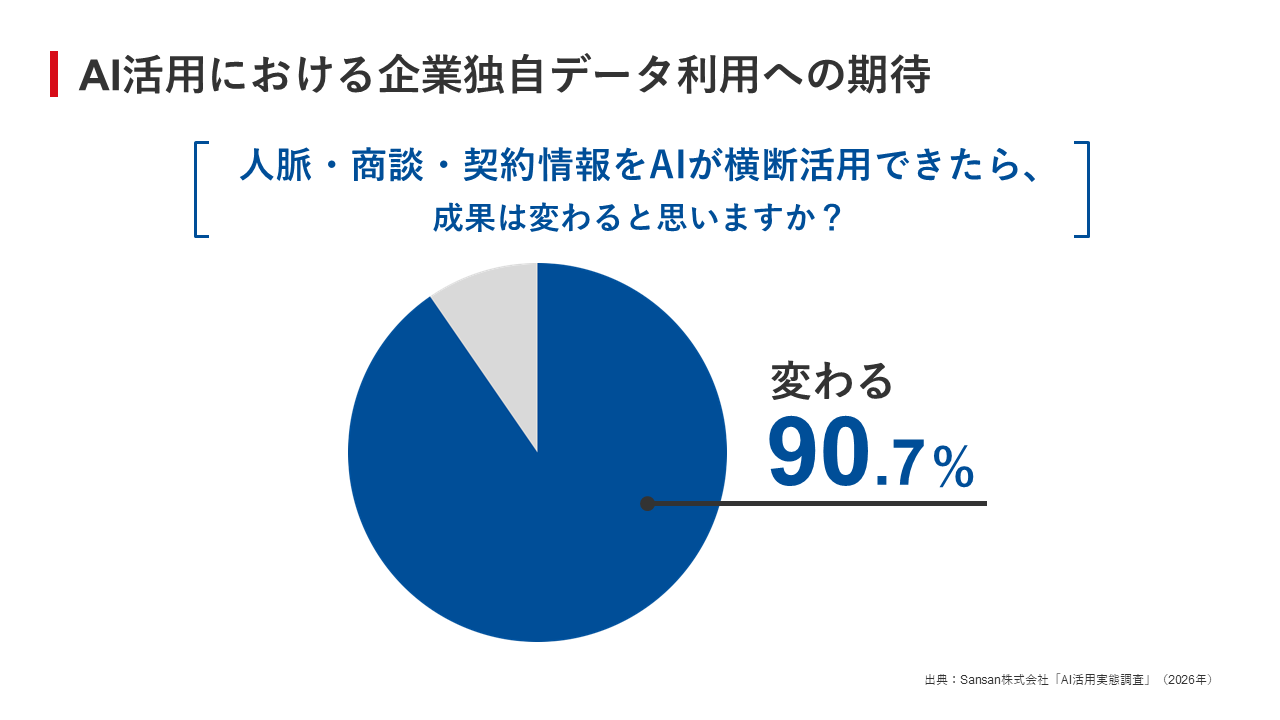 図2:AI活用における企業独自データ利用への期待
図2:AI活用における企業独自データ利用への期待拡大画像表示
「AI-Ready」なデータを作り出すための5つの要件
企業がAXを推進する上では、独自データをAIが即座に活用可能な「AI-Ready」な状態にしなければならない。AI-Readyとは、企業や組織がAIを効果的に導入・活用し、最大の成果を出すための準備が整っている状態である。鳴海氏は、「AI-Ready Data」の実現に求められる要件として、以下の5つを挙げる。
- 一意性:データに重複がないこと
- 正確性/最新性:データそのものが正しいこと。また、情報が常に新しく、推論可能な文脈が揃っていること
- 充足性:必要な項目が欠けずに揃っていること
- 信頼性:出典が担保されていること
- 機械可読性:AIが構造的に理解できること
しかし、自社が保有する独自データをAI-Ready化することは容易なことではない。その理由として鳴海氏は、5つの障壁が立ちはだかっていると指摘する(図3)。
- データが分断されている
- 活用前提で設計されていない
- データが更新され続ける
- 責任の所在が不明
- 構造化されていない
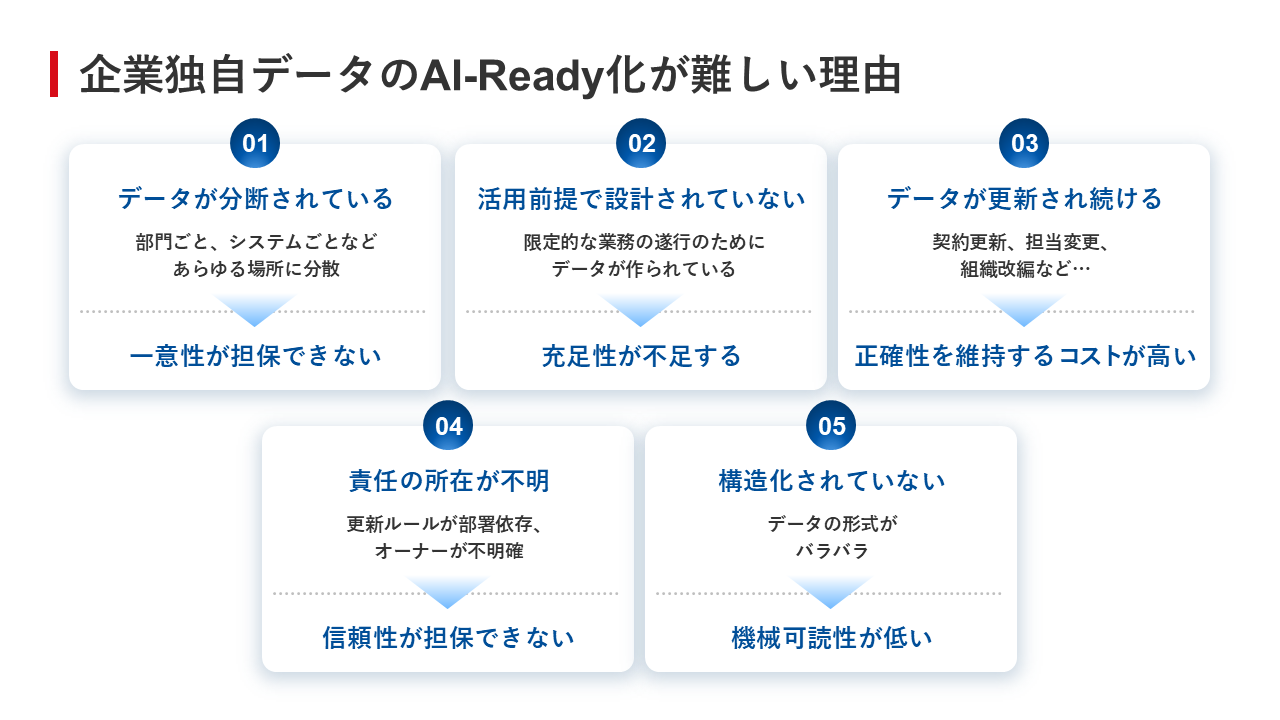 図3:企業独自データのAI-Ready化が難しい理由
図3:企業独自データのAI-Ready化が難しい理由拡大画像表示
「これらの障壁を打破するためのデータ整備には、1人当たり月10時間もデータ修正に工数が費やされているほか、平均で年間約6.4億円もの投資額が必要という試算もあります。そうした膨大な時間とコストの発生も、AI-Ready化を推進していくための障壁となっています」(鳴海氏)
企業独自データの取得からデータ化までの工程そのものが強み
Sansan社は2025年より「AIファースト」というビジョンのもと、全社員が生成AIを利用する環境を作り上げてきた。その推進に当たってどのような取り組みを進めてきたのか。
「生成AIが真の価値を発揮するには、その土台となるデータの準備が必須となります。先にも述べたように、インプットの品質が低ければAIの出力も向上しないため、AI-Readyなデータの構築こそが最重要課題です」と、Sansan社の猿田貴之氏は訴える。
 Sansan株式会社 Sansan事業部 SDIプロダクト室 室長 猿田貴之氏
Sansan株式会社 Sansan事業部 SDIプロダクト室 室長 猿田貴之氏「さらに、データ化の工程においては、生成AIだけで完結できない正確性も求められます。そうしたことからSansan社では、従来からのルールベース判定や機械学習モデルを中核としながらも、生成AIを効率化の手段として組み合わせることで、企業独自データのデータ化に取り組んできました(図4)」(猿田氏)
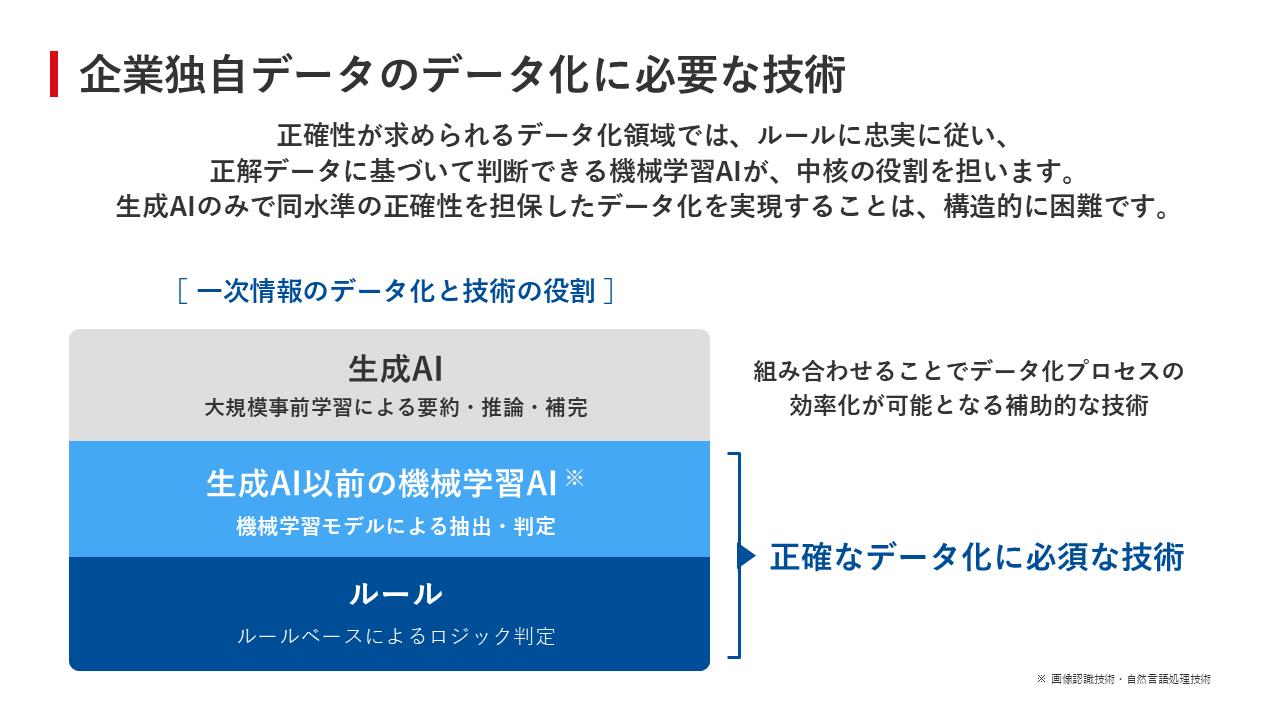 図4:企業独自データのデータ化に必要な技術
図4:企業独自データのデータ化に必要な技術拡大画像表示
Sansan社は現在、ビジネスデータベースの「Sansan」、経理AXサービスの「Bill One」、取引管理サービスの「Contract One」という3つのプロダクトを展開している。これらに共通するのは、名刺や請求書、契約書といったビジネスの一次情報を、独自の高度な工程を経て正確にデータ化している点だ。このように、企業独自データの取得からデータ化に至るまでの一連のプロセスこそが、同社のコア技術といえる(図5)。
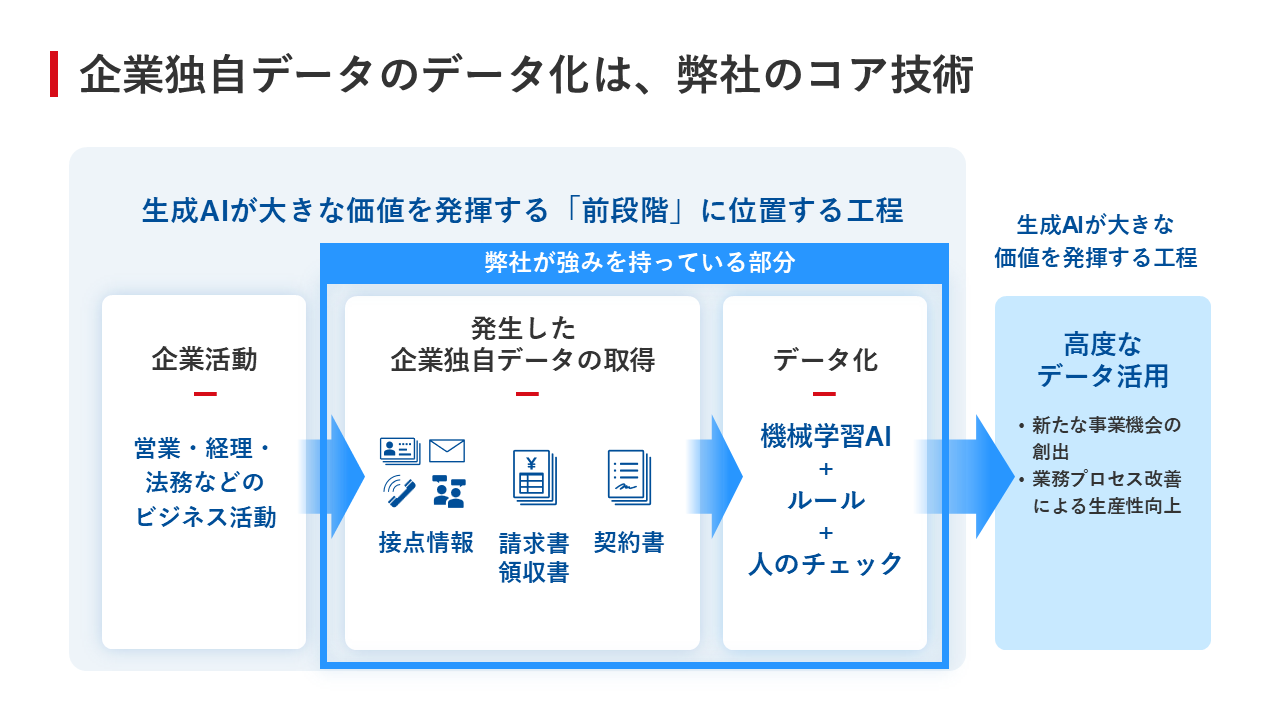 図5:企業独自データのデータ化は、Sansan社のコア技術
図5:企業独自データのデータ化は、Sansan社のコア技術拡大画像表示
社内に分散した取引先データをAI-Readyにする「Sansan Data Intelligence」
Sansan、Bill One、Contract Oneが取得するのは、名刺交換や請求書の受領、契約締結といった「外部との接点」から発生する「外部起因」のデータである。一方、企業の社内システムには、各部門が独自に管理している「内部起因」のデータも数多く存在する。AXを本格的に推進していくためには、これらのデータを統合的に扱っていかなければならない。
「中でも全社業務を横断する起点データとなるものが、取引先データです。取引先データは企業のデータ活用におけるインフラのような存在です(図6)」(猿田氏)
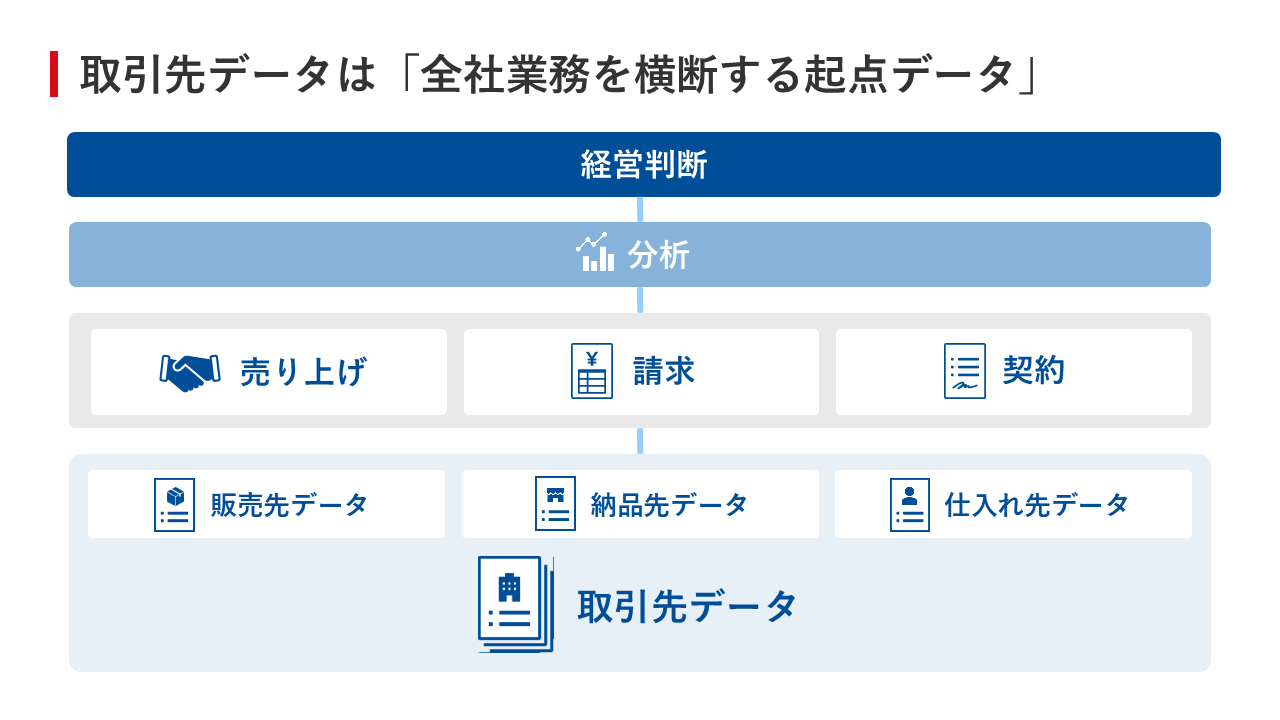 図6:取引先データは「全社業務を横断する起点データ」
図6:取引先データは「全社業務を横断する起点データ」拡大画像表示
しかし、この取引先データは、部門ごとに管理されていることから明確なオーナーが存在していないケースが多い。また、社内の各部門でそれぞれデータが分散、管理されているだけでなく、表記ゆれ、レコードの重複、更新漏れが発生しており、全社的なデータ統合が困難となっているのだ(図7)。
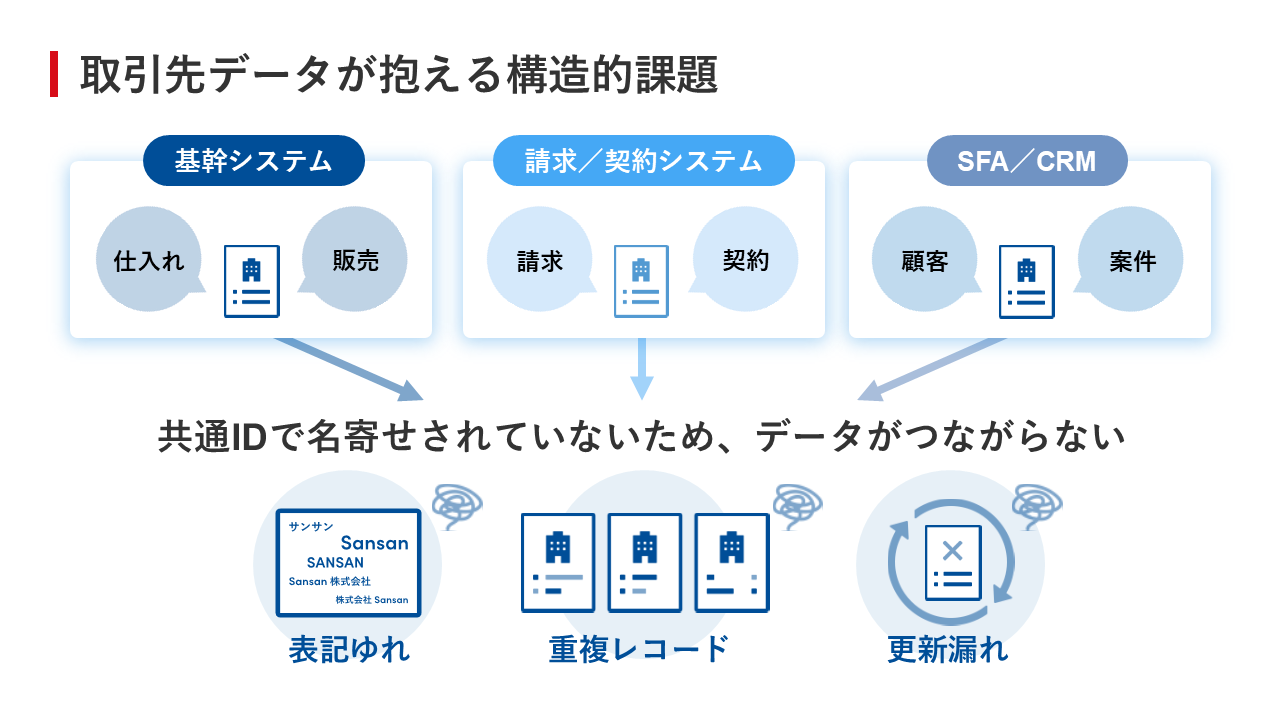 図7:取引先データが抱える構造的問題
図7:取引先データが抱える構造的問題拡大画像表示
このような課題に対してSansan社が提示する解決策が、2025年12月にリリースされた「Sansan Data Intelligence」である。
 図8:取引先データをAI-Readyデータに変換し続ける
図8:取引先データをAI-Readyデータに変換し続ける拡大画像表示
Sansan Data Intelligenceは、取引先データを最新・正確に維持し続けることで、取引先データを継続的にAI-Readyな状態へ変換することを可能にするものである(図9)。
1つ目の特長は、独自の識別コード「SOC」である。同社の高度な名寄せ技術で企業を識別し、識別したデータに付与される独自のコード「SOC(Sansan Organization Code)」により、「グループ系列」「企業」「事業所」の3つの単位で取引先を管理できるようになる。
2つ目の特長は、約1000万件の企業・事業所データベースをマスターデータとして保有していることである。国税庁・各省庁のオープンデータ・企業Webサイトなど複数のソースを組み合わせ、継続的にデータベースを最新の状態に維持している。
これらの特長により、取引先データのクレンジングをはじめ、取引先企業の全体像の把握、未接触の取引先を精緻に把握するためのターゲットリストの作成などを実現する。
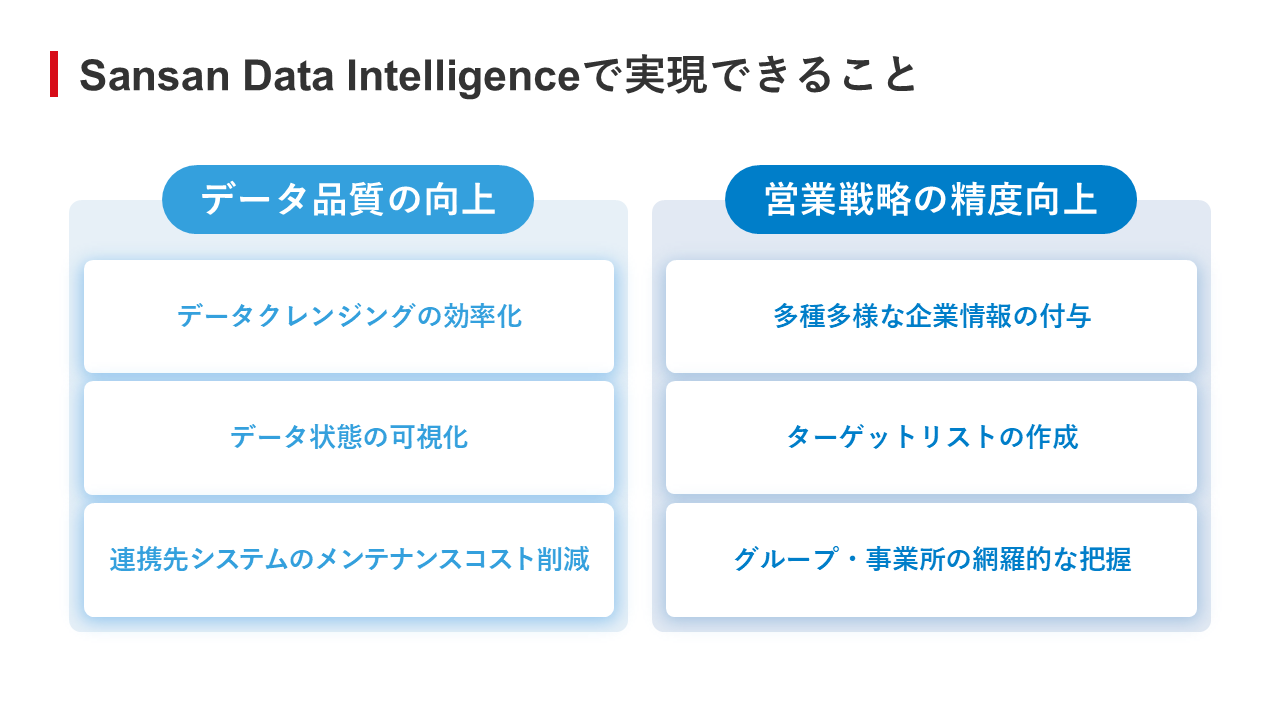 図9:Sansan Data Intelligenceで実現できること
図9:Sansan Data Intelligenceで実現できること拡大画像表示
データが正しく整備されることで、営業活動はより鋭敏になり、守りから攻めまで一貫したDXおよびAXの推進が可能となる。
最後に鳴海氏は、「経営判断に直結する取引先情報をAI-Readyな状態に保ち続けることは、AXの成果を左右する鍵となります。そのための支援を行うのがSansan Data Intelligenceです。その導入を検討しているのであれば、データの重複や鮮度を診断してどのような改善が必要なのかを提示する『取引先データ診断サービス』も提供しているので、是非一度、私たちにお声がけください」とアピールし、セッションを閉幕した。

●お問い合わせ先
Sansan株式会社
- AI対応のデータ基盤「レイクハウスアーキテクチャ」が、ビジネス成長を加速させる鍵に(2026/06/03)
- 製造業のAI導入を阻む「個別最適の遺産」をどう打破するか(2026/06/01)
- 「BIとAI、ぶつかる壁は同じだった」─東急レクリエーション5年の実践が示す「データ整備」という現実解(2026/05/26)
- 生成AI活用の第一歩はマスターデータマネジメント(MDM)から(2026/05/14)
- 企業AIの95%はなぜ使われないのか─Qlikが提唱するエージェンティックAIによるデータ統合の新機軸(2026/05/11)




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
