[Sponsored]
製造業のAI導入を阻む「個別最適の遺産」をどう打破するか
2026年6月1日(月)
AIの進化が加速するなか、製造業においても競争力を維持するためにデータ活用が不可欠だ。しかし、「データの一元管理ができていない」「データを活かしきれていない」といった課題に直面している企業が多いのではないだろうか。2026年3月11日に開催された「データマネジメント2026」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)にNTTデータ バリュー・エンジニアの宮下純一氏が登壇し、「AI Ready」なデータを作り上げるための、戦略的なデータマネジメントについて解説した。
提供:株式会社NTTデータ バリュー・エンジニア
需要予測による在庫最適化や品質のばらつき抑制、そして、属人化した生産計画からの脱却など、製造業にAIを導入することで期待できることは多い。しかし実情は、AIの予測結果を人間が再チェックしたり、出力された数字をExcelで手直したりといった手間が発生していたり、AIが出力した回答の判断根拠が不明確なために、その確認を巡って部門間をたらい回しにされる事態が発生するなど、DXそのものが止まってしまうケースも少なくないと思われる。
NTTデータ バリュー・エンジニアの宮下純一氏は、「こうしたAI活用を阻む原因は、技術や人材の不足ではなく、日本の製造業が歩んできた“個別最適化したシステム構築の歴史”にある」と指摘する。
 株式会社NTTデータ バリュー・エンジニア データマネジメント 統括部 データエンジニアリング部 シニアエキスパート 宮下純一氏
株式会社NTTデータ バリュー・エンジニア データマネジメント 統括部 データエンジニアリング部 シニアエキスパート 宮下純一氏 日本の製造業は1955年以降の高度経済成長期において生産効率を最優先し、各工場や拠点に強い裁量を与えてきた。当時は「作れば売れる」時代であり、拠点ごとに独自ルールのもとでシステムを構築することが最適解だったからだ。またこのことは、日本の製造業の競争力を支えた重要な要素でもあった。
1980年代以降のグローバル化やM&Aの進展に際しても、サイロ化されたシステムの統合は先送りにされてきた。その結果、拠点ごとにデータ構造や定義が分岐してブラックボックス化が進行し、深刻なサイロ化を招いてしまった。全社横断でデータをつなぎ、AIで最適化しようとしても、過去の個別最適の遺産が巨大な壁として立ちはだかり、AIがデータを読み解けないという状況が発生しているのだ。
AI導入の成果が得られない理由
そうした弊害の1つが「方言」の発生だ。宮下氏は、「製品名が各国で異なるケースは往々にしてある。国ごとのブランディング戦略や商標の関係もあり、それ自体は大きな問題ではない。深刻なのは“データの分断”だ」と指摘する(図1)。
 図1:拠点ごとに最適化された「方言」が発生する理由
図1:拠点ごとに最適化された「方言」が発生する理由拡大画像表示
「例えば、国内拠点では製品コードが数字5桁の体系であるのに対し、欧州拠点では英数字が混在しているといった具合に、同一製品のはずがシステム上では別物として扱われている。その結果、データが繋がらなくなり、データが示す意味を読み解けない状態を生み出してしまっている」(宮下氏)
この問題を解決するため、IT部門が主導してコードの統一に取り組むケースも少なくないだろう。しかし、システム変更に伴う多大なコストや、現場部門からの反発によって断念するケースも多い。断念したままAIを導入しても、下記の理由から期待する成果が得られない。
- 収集不能……「同じ製品である」という判断が拠点間で統一されていないため、全社横断のデータが収集できない
- 解読不能……データの持つ意味や粒度が揃っておらず、AIが学習用のインプットとして読み取ることができない
- 品質不良……重複や欠損があるデータを投入することで、根拠のない回答(ハルシネーション)を返し、現場に確認作業を強いる
「不完全なデータをAIに投入することは、高性能なF1マシンに不純物の混じった燃料を入れて走らせることと同じだ。AI本来の性能を導くためには、“データを磨く”プロセスが不可欠」(宮下氏)
AI Readyなデータを作り上げるための5つのポイント
AI導入の成否はツールの性能ではなく、AIが理解できる形、すなわち「AI Ready」なデータをいかに作り上げるかにある。宮下氏は、そのためのポイントとして、以下の5つを挙げる(図2)。
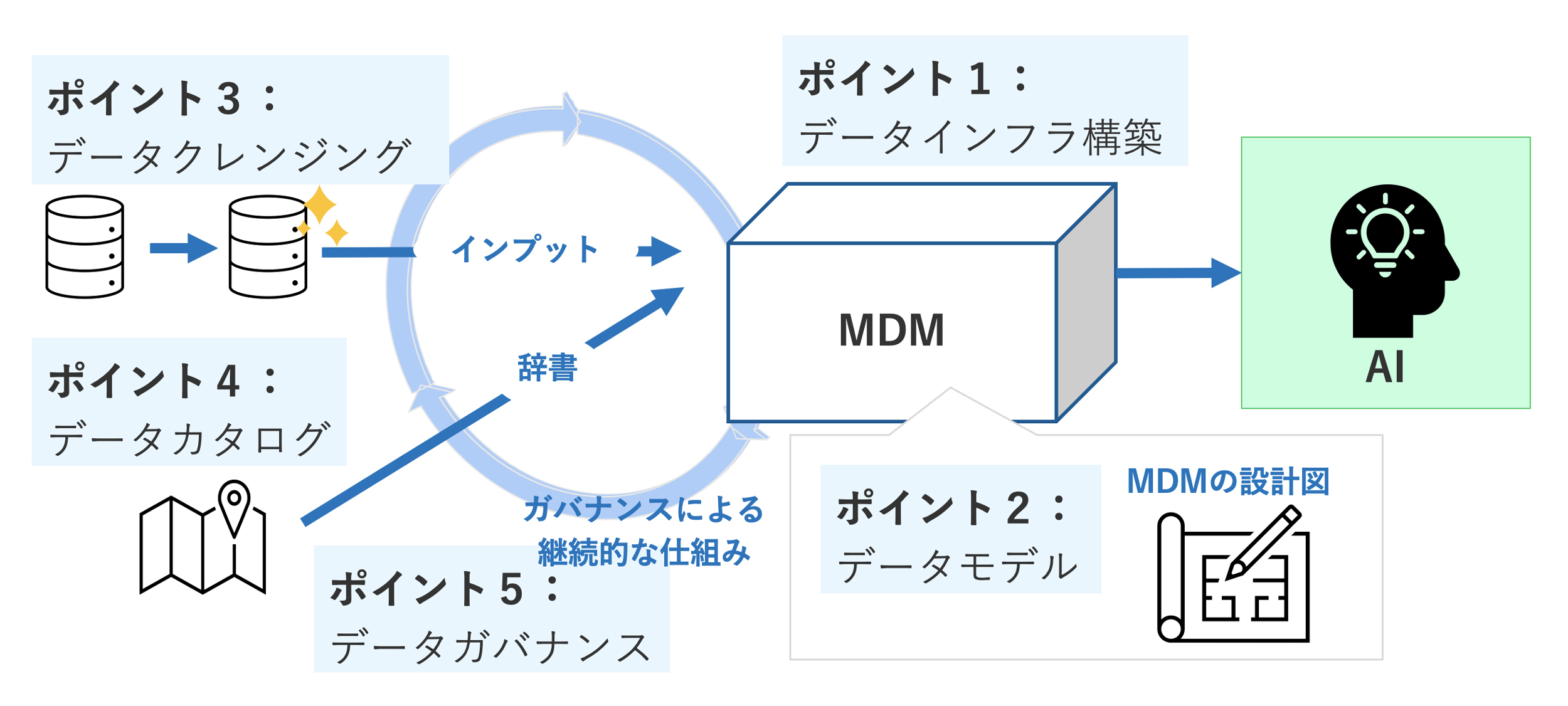 図2:AI Readyなデータを作り上げるための5つのポイント
図2:AI Readyなデータを作り上げるための5つのポイント拡大画像表示
①データインフラの整備(MDMの導入)
各システムに散在するデータを名寄せし、重複を排除して「信じられる唯一の正解(ゴールデンレコード)」を生成する。これにより誰の判断が正しいかではなく、システム上のデータが正しいと言える環境を構築する。
②データモデルの設計
たとえば自動車メーカーの製品の場合、製品の型式、車名、車種タイプといった情報がデータとしてどのような関係性で管理されているか整理し、データモデルとして可視化する。拠点ごとに異なる管理構造の差異を把握し、それらをどう変換して統合するかという変換設計を定義する。
③データクレンジングの徹底
機械的な置き換えと人の目によるチェックを組み合わせて、データの表記揺れを解消する。特にシステム刷新時のデータ移行は、不完全なデータを新システムに持ち込ませない、いわば「データデトックス」の最大かつ最後の機会となる。
④データカタログの構築
作成者、更新日時、用途、関係部署などの付帯情報をメタデータとして付与する。メタデータは「どのデータがどこにあるか」を即座に特定するための検索インデックスとして機能するため、AI活用までのリードタイムを短縮し、組織全体のデータ活用スピードを底上げする。
⑤データガバナンスの確立
せっかくクレンジングしたデータを再び混乱状態に戻さないための仕組みを設定する。具体的には、下記の5つの継続管理メソッドを実践する。
- データ管理体制の構築……役割、スキル、体制などを定義する
- 標準ガイドラインの整備……課題や検討ポイントを踏まえて各種規定を整備する
- データマネジメントスキルの定着化……研修・教育コンテンツを作成する
- データムーブメントモデルの可視化……現行の業務間データフロー、システム間データフロー、概念データモデルを可視化する
- データマネジメントの評価……標準ガイドラインの検討をもとに評価軸・評価指標を設定し、評価運用ルールを作成する
IT部門の孤立を解消するには
AIの導入の難易度が高い大きな要因には、IT部門の孤立もある。経営層からはAI導入を丸投げされる一方、現場部門からは「通常業務が忙しい」「現状で困っていない」と協力を拒まれるといった状態だ。「この状況を打破するには、お願いベースの調整ではなく、客観的な事実に基づいた“3つの武器”が必要」と宮下氏は強調する。
①サブジェクトエリアマップ
まずはデータのありかを整理し、ターゲットを定めることが必要となる。そのために必要なものがサブジェクトエリアマップだ。これは製品、部品、設備、チャネルなど、企業内のデータ領域を俯瞰できる、いわば地図のようなものだ。さらに、データモデルと組み合わせることで、どのマスターがビジネスにとって重要なのか、どこから整備すべきなのかを明確化できる(図3)。
 図3:「サブジェクトエリアマップ」でデータを整理する
図3:「サブジェクトエリアマップ」でデータを整理する拡大画像表示
②データフロー
どの部署がデータを作り、誰が加工してどこで使っているか、データの流れから関係者を特定する。これにより、特定の担当者に対して具体的な協力要請が可能になる(図4)。
 図4:「データフロー」で関係者を明確にする
図4:「データフロー」で関係者を明確にする拡大画像表示
③プロファイリング
データの現状を客観的に診断し、欠損や重複を数値化して品質を評価する。現状のデータの「健康状態」を可視化することで、経営層や現場に対して改善の必要性を納得させる強力な材料とする(図5)。
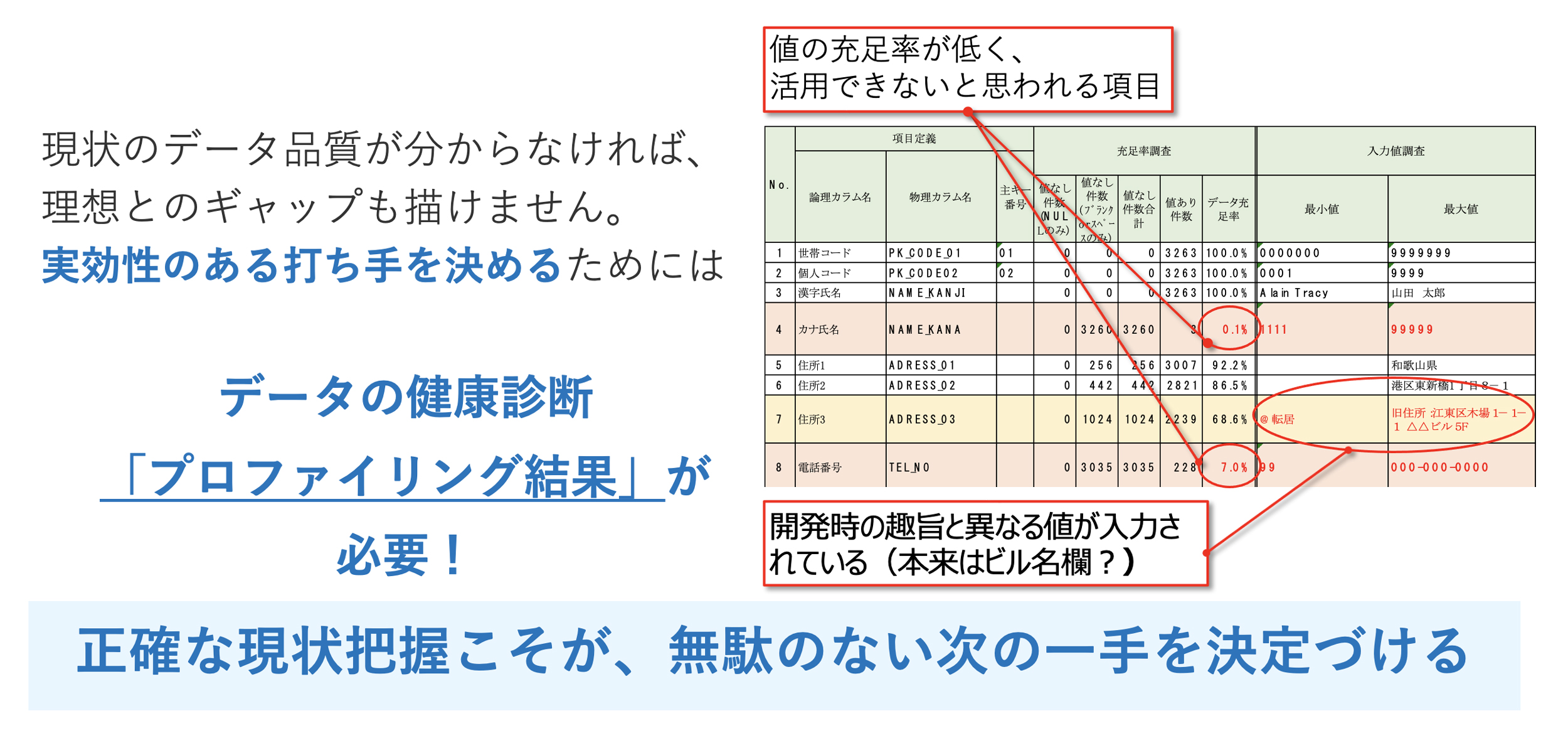 図5:「プロファイリング」でデータ品質を把握する
図5:「プロファイリング」でデータ品質を把握する拡大画像表示
「これらの判断材料が揃うことで、IT部門は孤独な戦いから抜け出し、全社を巻き込んだAI推進へと踏み出せるようになる」(宮下氏)
AIが正しく学習するためのソリューション
株式会社NTTデータ バリュー・エンジニアでは、MDM(Master Data Management)システム構築支援を提供している。MDMシステム構築支援では、まず各システムに散らばるデータを照合し、表記揺れや重複を検出して名寄せする。次に、顧客や製品をユニークなIDで一元管理し、親子関係や部品構造といったビジネス上の関係性を定義する。
こうして作られるのが、「ゴールデンレコード」と呼ばれる唯一の正解データだ。ゴールデンレコードがあることで、全社で同じものを同じ意味で扱えるようになり、分析の精度や意思決定の一貫性が飛躍的に高まる。AI活用において心臓部となる基盤が、このMDMなのだ。
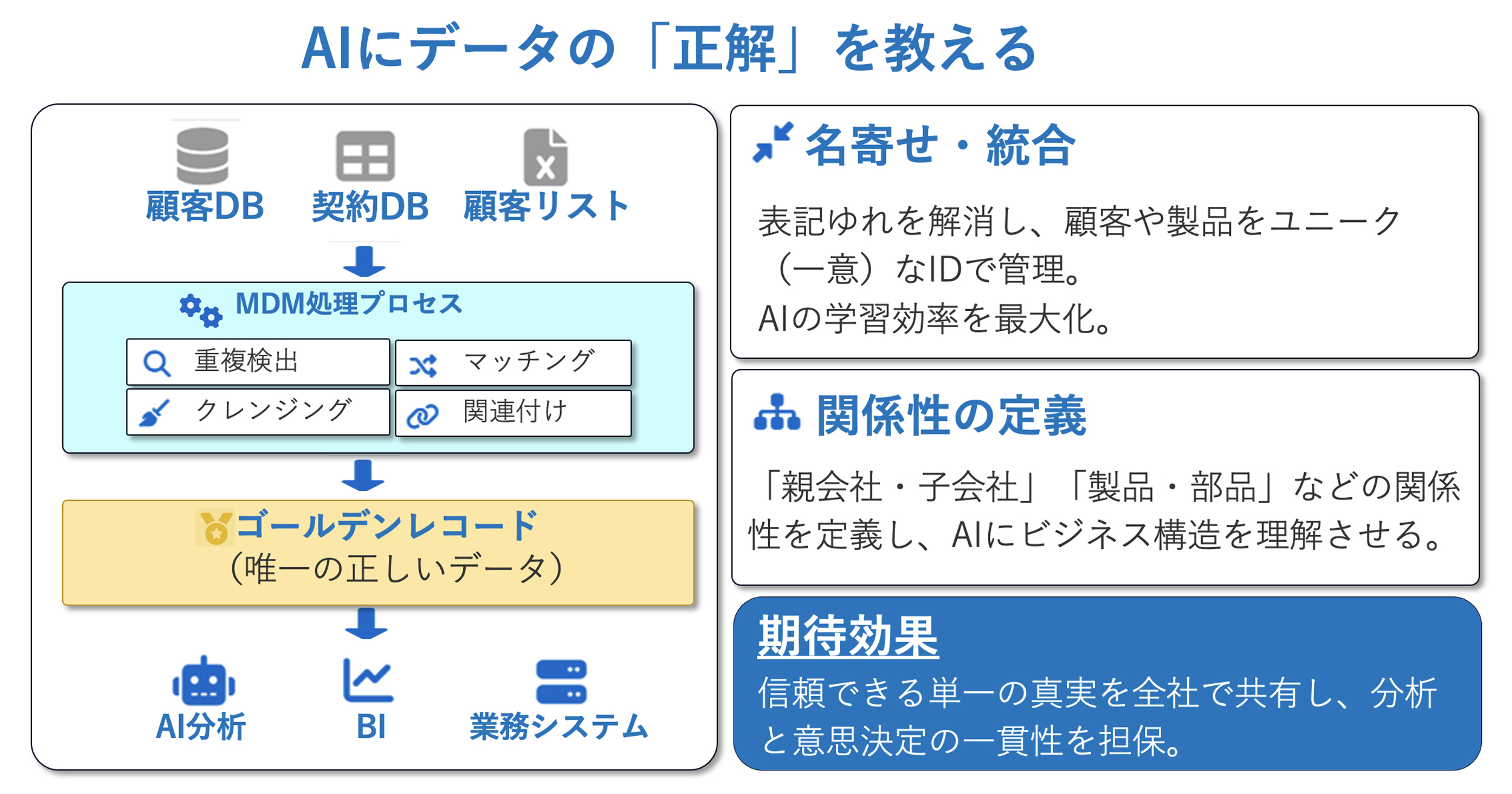 図6:MDMシステム構築支援の概要
図6:MDMシステム構築支援の概要拡大画像表示
また、文書の種類、作成日時、関連部署、機密度といった高度なメタデータのタグ付けを行い、データの文脈をAIが理解できるように整備する「メタデータ構築支援」も提供している。
AIの性能は投入されるデータの品質で決まる。宮下氏は最後に、「全社的な大規模改革から始めるのではなく、まずは重要なマスターデータに絞り、スモールスタートで早期に成果を出すべきだ。現場の事実に即してデータを磨き、AIが理解できる“AI Ready”な状態にすることこそが、製造業が停滞を脱却し、確実な成果を出すための唯一の鍵となる」と訴えた。

●お問い合わせ先
株式会社NTTデータ バリュー・エンジニア
- データエージェントが導く「データマネジメント」の民主化とAI活用の未来(2026/06/17)
- Sansan社の実践知に基づく、AX時代のデータ品質マネジメント(2026/06/15)
- AI対応のデータ基盤「レイクハウスアーキテクチャ」が、ビジネス成長を加速させる鍵に(2026/06/03)
- 「BIとAI、ぶつかる壁は同じだった」─東急レクリエーション5年の実践が示す「データ整備」という現実解(2026/05/26)
- 生成AI活用の第一歩はマスターデータマネジメント(MDM)から(2026/05/14)
NTTデータ バリュー・エンジニア / 製造 / MDM / データクレンジング


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
