米dotDataは2026年6月23日、データ構造化・加工ツール新版「dotData TextSense 1.3」を発表した。CSVデータとしてアップロードした非構造化テキストから生成AIが意味を抽出してラベルを付与し、活用・分析しやすい形へと加工するクラウドサービスである。新版では機械学習モデルをダウンロードしてローカルで推論処理を実行できるようにした。大規模なテキストデータのラベリング運用コストを抑制する。
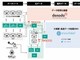
米dotDataの「dotData TextSense」は、テキストデータから意味を抽出してラベルとして付与し、分析に適した構造化データへと加工するクラウドツールである。1行1レコードのCSVデータとしてクラウドにアップロードすると、生成AIがテキストから意味を抽出してレコードごとにラベルを付与する(関連記事:dotData、テキストデータに意味ラベルを付与して構造化する「TextSense」を発表)。
抽出する「ラベル」もAIが自動で提案する。例えばVOC(顧客の声)分野なら「価格不満」や「配送遅延」などである。ラベルに対してOK/NGのフィードバックを与えるだけで生成AIのプロンプトをチューニングできる。プロンプトが確定したら、全量データに対してラベルを推論・付与する。こうして生成したラベル付きの構造化データをダウンロードして使う。
従来版では、テキストに意味ラベルを付与する処理のすべてでLLMのAPIを呼び出していた。同社によれば、100万件のテキストをAPIで処理した場合、1回の実行あたり約1000~2000ドルのコストが発生する。定義したラベルを全件のデータに適用する本番運用フェーズでは、このコストが導入の障壁となっていた。情報セキュリティの観点でも、顧客情報や機密情報を含むテキストを外部のLLMサービスへ送信しなければならない点が課題だった。
新版では、LLMでプロンプトと初期ラベルを生成したうえで、軽量な機械学習モデル(ローカルモデル)を構築する仕組みを導入した。本番運用ではローカルモデルを使ってラベリングを実行するため、LLMのAPI呼び出しが不要になる。同社の実験では、財務報告書データ約100万件に対し、LLMによるラベリング結果を基準(100%)とした場合に、約98%の精度を維持しながら約100分の1のコストでラベリングできるとの結果を得たとしている。
ローカルモデルは、ローカル環境に出力してPythonライブラリとして実行できる。LLMのAPIを使わないため、オンプレミス環境や閉域網でデータのガバナンスを確保したまま運用できる。バージョン1.3の各機能は、大規模テキストデータの運用を想定し、データパイプラインや定期的なバッチ処理に組み込みやすいPython版として提供する。



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
