「これまでのコンピューティングには2つの時代(Era)があった。1つは19世紀後半から1950年代までの自動計算機(タビュレータ)、機械式の集計機や手回し計算機の時代だ。もう1つがその後から今日に至る、プログラム可能なコンピュータの時代。大型コンピュータとスマートフォンは違うものに見えるが、極論すればサイズが小さく、使い勝手が向上しただけの違いでしかない。そして今、コンピューティングは第3の、新しい時代(Era)に入った。システム自体が学習する”コグニティブコンピューティング”の時代だ。これは(社会や企業に)、非常に大きなインパクトをもたらす」(米IBMのバージニア・ロメッティCEO)。
コンピュータの歴史をこのように3世代に分けることの是非論はともかく、人間のように学習したり、考えたりするコンピュータの開発が長年の夢だったことは間違いない。特に1980年代後半から1990年代前半にかけ、世界各国で人工知能(AI)を開発する動きが沸き起こった。
音声認識、自然言語理解、機械翻訳などはもとより、人間の専門家が持つ知識やノウハウをコンピュータに取り込むエキスパート・システム(ES)、0と1のデジタル情報ではなく曖昧な情報を扱うファジィ論理、人間の脳の動作を真似たニューラルネットワークなどが開発された。
しかしクレジットカードの不正利用検出など一部を除き、少なくとも実用という観点からはさほど大きな成果を上げられずに来ている。記憶や学習、思考のメカニズムがよく分かっていないこと、コンピュータの性能や記憶容量の不足などがその理由だ。
そんな状況を変革し、ロメッティCEOが期待するマシンが、IBMの創業者からその名をとった「Watson」だ。米IBMは10月にシンガポールで開催したカンファレンス「InterConnect2012」において、その最新状況を明らかにした。実際にWatsonは、第3の時代(Era)を切り拓くポテンシャルを備えているのか。どれほどのマシンなのか。
以下では説明会で話されたことと、責任者へのインタビューを併せて報告する。現在、医療や金融、通信などの分野で特定の企業、組織と組み、応用開発が進んでいる。2013年にはコールセンター向けのパッケージ型のWatsonを販売し、またクラウド型のサービスとしてWatsonを広く公開する計画もあるという。
Watsonは思考はしない、学習と推論のみ
専門機関と共同でガン治療への応用進める
まずはWatsonの簡単な歴史から。IBMと複数の大学による共同プロジェクト「DeepQA」として2006年にWatsonの研究開発がスタートした。「今日、生み出されるデータや情報の量は級数的に増加しているが、その80%は非構造データであり、既存のコンピュータでは効果的に扱えない。ビジネス・リーダーの2人に1人は必要なデータにアクセスできないでいる。ビジネスは、データの海の中で、渇きに耐えかねて死にかけているのが実情だ」(Watson担当のManoj Saxena IBMジェネラルマネジャー、写真1)。そこで大量の情報を蓄積し、効果的にアクセスできるシステムの開発が始まった。

それから5年、成果を示すために2011年2月、米国の人気クイズ番組「Jeopardy!」にWatsonが出場。歴代出場者のうち最も名高い2名のクイズ王(賞金王)と戦って勝利した。自然言語で出題された複数ジャンルにまたがるクイズに、リアルタイムで、しかも音声で回答したことで、一気に認知度が向上した。2011年8月には商業化に踏み切り、医療や金融などの分野で実用システム開発が進められている。
その一つが米国最大手の医療保険会社であるWellPoint、ガン専門の医療機関であるMemorial Sloan-Kettering Cancer Center と提携しての、ガン治療への応用(写真2)。「米国人の死因の2番目がガンであり、3人に1人がこれで死亡する。最適な治療法を見いだすのが難しい病気でもあり、初期では44%が、その後も20%は診断に誤りが起きている。この問題に対し、Watsonは100万以上の症例や関連する膨大な研究論文、統計データなどを学習し、最適な治療法を医師に提案して意思決定を支援する」。

どんなに優れた医者でも数百万件の情報を覚えるのは不可能。一方、あらゆる情報を記録したDBがあれば検索をかけられるが、ガン治療の場合、検索用に入力する情報自体が多岐にわたり、またヒットする症例データや文献が多数になりがちで、結局どんな治療が最適なのかを見出すには、医師の経験や能力に頼るしかない。「Watsonはエビデンス(証拠)に基づく意思決定を支援する。例えば最適と推論された治療法を確率とともに表示し、推論の詳細を知りたい場合にはオリジナルの症例や文献を表示する。Watsonのインパクトは明らかだろう」。
学習や推論とはどういうことか。Watsonは自然言語理解、機械学習といった技術を使って、大量の文献や症例を構造化して蓄積していく。これが学習であり、UIMAという技術が使われる。「UIMAは構造化されていない情報を、構造化する仕組み」である。推論時には、問い合わせの内容を理解し、仮説を生成。その仮説を蓄積した情報をもとに検証していく。ここで使われるのがDeepQAアーキテクチャだ(写真3)。推論が進むに従い仮説は増えていく。これを並列処理で検証し、最後に「バランスとコンバインにより、適切な結果を導出する」。
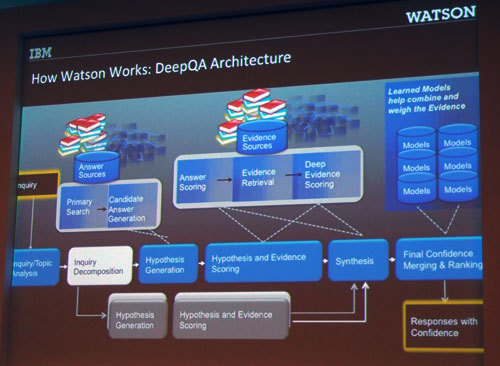
説明会でIBMが強調したのが「Watsonは思考はしない。推論と学習を行うだけ」という基本原理だった。人間のように情報を組み合わせて新しい何かを思いついたり、自ら決定することはできない。つまり「特定の問題領域に特化して専門家を支援するシステムであり、代替することはできない」。1990年前後に追求された人工知能(AI)とは違うアプローチである。
機能はどうか?Watsonは問い合わせ応答の「ASK」、答えを検索する「DISCOVER」、意思決定を支援する「DECIDE」という3タイプのサービスを備える。ASKは次世代のチャット、DISCOVERは次世代の検索エンジン、DECIDEは意思決定支援のアプリケーションだという。「次世代の検索エンジンとは、サーチではなく発見であるという意味だ。検索語にない情報やデータも見出すことができる」。
使っているハードウェア構成は日々、進化しているようだ。クイズ番組「Jeopardy!」の時点では、IBM POWER 750(サーバ10ラック分、2880個のPowerプロセサ、15テラバイトのメモリを持ち、大きさは冷蔵庫10台分だった。現在では冷蔵庫2個分になり、2013年には野菜庫のサイズにする。急ピッチで小型・高性能化しているわけである。




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
