[Sponsored]
セルフサービス型活用支える「Intelligent Data Lake」でビッグデータ・ガバナンスを確立せよ
2016年8月22日(月)
様々なデータを分析し、新たな洞察(インサイト)を得て行動につなげる−−。こうした取り組みの重要性に疑問の余地はないだろう。そんな、事業部門のスタッフがストレスなく必要なデータを取得し、自らの切り口で集計・分析できるための環境になるのが「データレイク」。だが「単に大量データを蓄積しただけではデータレイクとしては不完全だ」と各種のデータマネジメント・プラットフォームを開発・販売するインフォマティカ・ジャパン セールスコンサルティング部ソリューションアーキテクト/エバンジェリストの久國 淳氏は指摘する。企業に価値をもたらすデータレイクに必要な要素とは何だと言うのだろうか。
 写真1:インフォマティカ・ジャパン セールスコンサルティング部ソリューションアーキテクト/エバンジェリストの久國 淳氏
写真1:インフォマティカ・ジャパン セールスコンサルティング部ソリューションアーキテクト/エバンジェリストの久國 淳氏「現場のスタッフによるスピーディな意思決定のためのデータを活用したいと考えている企業は今や珍しくない。先行企業の中には既に、数十ペタバイト級の膨大なデータを蓄積している例もある。その一方で、データは蓄積してみたものの、ファイルの中身が何か、いちいち開けてみないと判別できなかったり、そもそも必要なデータがどこにあるのかすら分からなかったりする企業も少なくない」
インフォマティカ・ジャパンのセールスコンサルティング部でソリューションアーキテクト/エバンジェリストを務める久國 淳氏は、「データレイク」というデータ活用のための基盤がまだまだ十分に機能していないと指摘する。上記のような状態では、「データレイクとは呼べず、単なるファイルサーバーに過ぎない」と手厳しい。
「とりわけ昨今は、オンプレミス環境だけでなく、クラウド上でも多くの業務システムが利用され、それぞれにデータが発生・蓄積されています。IoT(モノのインターネット)に象徴されるように今後、データの取得・蓄積は、ますます容易になっていきます。それだけに、これまで以上にデータがサイロ化していきかねません」(久國氏)という。
セルフサービス型でビジネス上の課題解決をアジャイルに
経営に資するデータレイクとしてインフォマティカが提供するのが「Intelligent Data Lake」である。データサイエンティストやデータアナリストといったデータ分析の専門家から、データマネジメントに責任を持つデータスチュワード、そして事業部門の利用者までが、セルフサービス型でビジネス上の課題解決にアジャイル(俊敏)に取り組める環境だ(図1)。
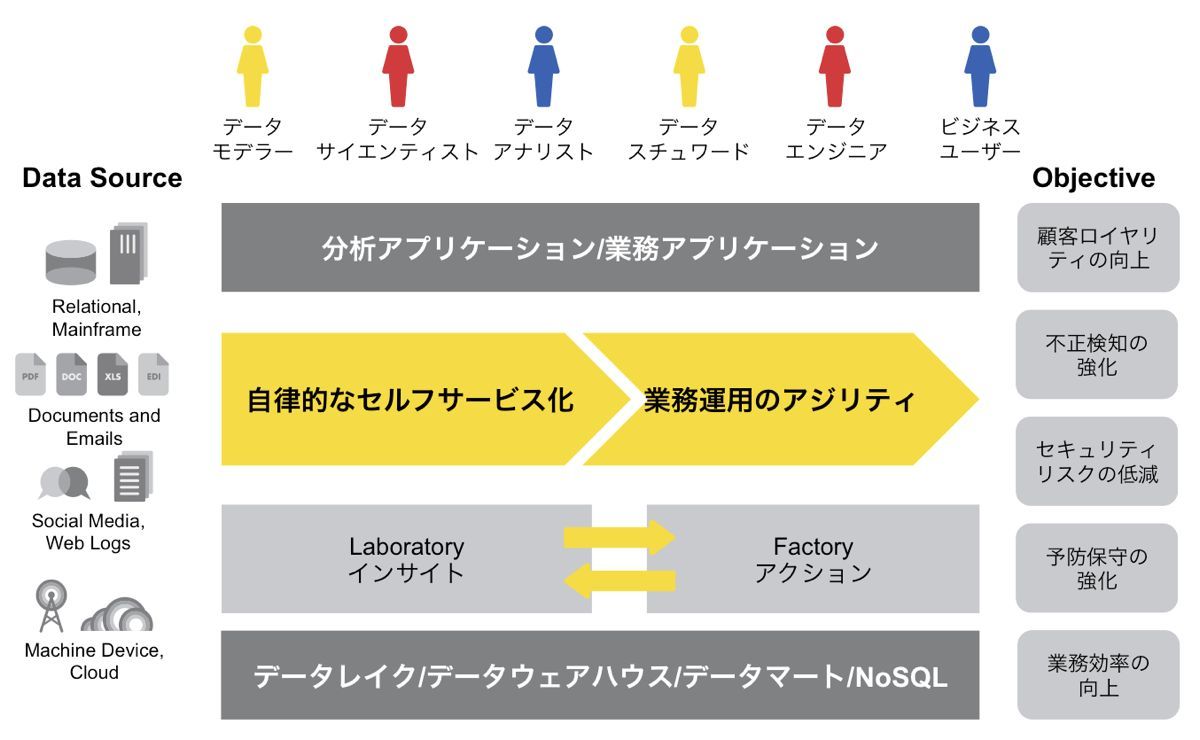 図1:経営に資するデータ活用環境のあり方
図1:経営に資するデータ活用環境のあり方拡大画像表示
日本ではデータサイエンティストやデータスチュワードといった専任者を置いている企業は必ずしも多くはない。そうした役割をIT部門が担っているかもしれない。そうしたケースを含め、「データ分析に携わる複数の利用者がストレスなく必要なデータセットを選び、様々な切り口で集計・分析できるようにする」(久國氏)のがIntelligent Data Lakeなのである。
図1で着目すべきは、Intelligent Data Lakeの目的(Objective)が、顧客ロイヤリティの向上や不正検知、予防保守の強化などビジネス上の課題になっていることだ。「ビジネス部門がデータ活用に集中するためには、データの“海”から求めるデータを見つけ出し、加工して活用するというサイクルをいかに速く回せるかが重要となります。データを溜めておくだけでは真の活用にはつながりません。データの海で溺れないためにはインテリジェンスが必要です」と久國氏は説明する。Intelligent Data Lakeの「Intelligent」には、人の行動を支援するという意味と、増え続けるデータを容易に利用するために人工知能技術を適用するという意味がある。
用途別のツール導入ではデータ処理がブラックボックスに
ビジネス部門におけるセルフサービス型のデータ活用を可能にするというIntelligent Data Lakeだが、業務部門のスタッフが必要なタイミングに、必要なデータを使える状態にするために、その裏側ではどんな仕組みが動いているのだろうか。そのためにインフォマティカが訴求するのが「ビッグデータアーキテクチャー」の確立である。
データマネジメントの基本が、データの取得から活用までの間に発生する、データの抽出や変換、機密保持、品質向上、共有などであることは、従来から変わらない。そのため各機能に対し複数ベンダーが用途別の専用ツールなどを市場投入している。しかし久國氏は「用途別のツールをそれぞれに適用していては、データに対する処理がブラックボックス化し、全体としての最適化や可視化が図れなくなることが問題です」と語る。




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
