日本IBMは2018年10月9日、説明会を開き、分析用のデータを整備することの重要性を説くとともに、データの整備を支援する同社製品やサービスについて紹介した。データ分析者がセルフサービス型で分析用データを調達できる基盤として“データカタログ”の構築が重要だとした。
データを分析して活用する上での最大の課題として日本IBMは、分析対象のデータの品質と整合性に問題があることを挙げる。日本IBMが手がけたIBM Watsonの導入プロジェクトのケースでも、そのまま利用できたデータは30%以下だったという。例えば、ある金融機関では、支店ごとにデータの形式が異なっており、これらを合わせる必要があった。
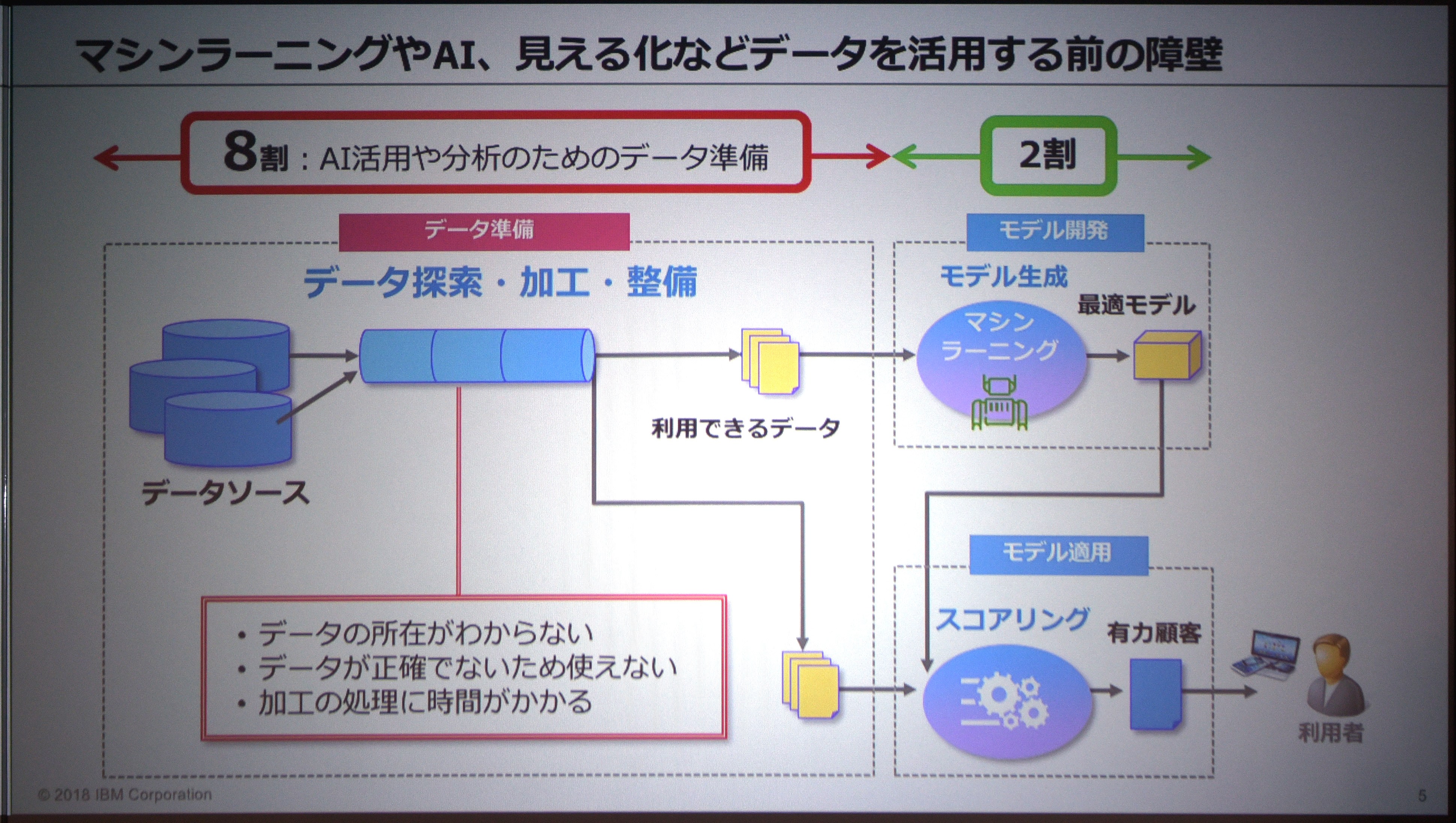 図1:分析可能な状態へとデータを整備する作業の負荷が大きい(出典:日本IBM)
図1:分析可能な状態へとデータを整備する作業の負荷が大きい(出典:日本IBM)拡大画像表示
分析用データを整備することが何よりも重要だ、と日本IBMは説く。このための基盤として日本IBMは、“データカタログ”と呼ぶ概念を紹介する。「データの所在が分からない。データが不正確。データの加工に時間がかかる。こうした課題をデータカタログによって解決できる」(日本IBMのIBMクラウド事業本部アナリティクス事業部第二テクニカルセールスでシニアITスペシャリストを務める高田和広氏)という。
 写真1:日本IBM IBMクラウド事業本部アナリティクス事業部第二テクニカルセールス シニアITスペシャリスト 高田和広氏
写真1:日本IBM IBMクラウド事業本部アナリティクス事業部第二テクニカルセールス シニアITスペシャリスト 高田和広氏拡大画像表示
データの利用者は、データカタログを利用することによって、必要なデータを入手できる。ビジネス用語で検索するだけで、必要としているデータのありかや、そのデータの品質などが分かる。メタデータ同士の関連図から関連キーワードへの気付きも得られる。
データカタログを実現し、データの前準備にかかる負荷を減らす製品として、日本IBMは、「IBM InfoSphere Information Server」と呼ぶパッケージソフトを提供している。ETL(抽出/変換/加工)やクレンジング(名寄せなど)といった基本的なデータ処理機能に加えて、ビジネス用語で検索可能なデータカタログ、データ品質の監視、データの来歴や影響分析、といった機能群を提供する。
2018年10月9日からは、IBM InfoSphere Information Serverとは別の製品で、データの収集、整備、分析の機能を包括的に支援するソフト「IBM CloudPrivate for Data」(ICP Data)の試用版を、ホスティングサービスの形態で提供開始した。試用版では、ICP Dataを7日間、無料で利用できる。ICP Dataにもデータカタログを作成/運用する機能が含まれる。ICP Dataの価格(税込み)は、1仮想プロセッサあたり212万4000円。
日本IBMはまた、データの活用を支援するコンサルティングサービス「」(DFM)も提供している。ユーザーにあらかじめ100項目程度の質問に答えてもらい、数度のワークショップを介して、ロードマップを提示する。日本IBMでは、100人のデータサイエンティスト集団「Data Science Elite Team」を組織しており、130社のユーザーのプロジェクトを支援している。
IBM / アナリティクス / データプレパレーション / データカタログ


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
