AIやIoT、クラウドなどの最先端技術を活用し、デジタルトランフォーメーション(DX)を加速する企業が増えている。そのチャレンジを根底で支え、デジタル戦略の核となるのがデータ活用だ。そこで求められるのは、社内外のさまざまなITサービスやデータソースと連動し、データ収集から価値の創出・実行までフルサイクルでサポートし、データの利用者と提供者の双方のニーズに応える全社横断データプラットフォームである。「データマネジメント2019」のセッションでは、日本アイ・ビー・エムの久保俊彦氏が、「『AI×データプラットフォーム』で挑むデジタルトランスフォーメーション」と題して講演を行った。
「データ×AI活用」のトレンドと課題
 日本アイ・ビー・エム株式会社 Data & AI 事業部 シニアアーキテクト 久保 俊彦 氏
日本アイ・ビー・エム株式会社 Data & AI 事業部 シニアアーキテクト 久保 俊彦 氏業務の効率化や自動化を発展させて新たなビジネスモデルを創出し、その価値をさらに高めていくデジタルトランスフォーメーションが進んでいる。その取り組みの中心に位置するのが「AI」と「データ活用」である。
しかし、企業の思いと現実の間には、まだまだ大きなギャップがあるようだ。日本IBM Data & AI 事業部のシニアアーキテクトである久保俊彦氏は、「わずか15%の企業しかデータから価値を引き出せていません」と実態を示した。
久保氏によれば、データ×AI活用は「データ連携・アクセス→データの準備・加工→分析・機械学習のモデル構築→AI・分析 モデルのアプリへの適用と管理」というステップで進んでいく。しかしながら、その節々で多くの企業は「データをどのように使えるかわからない」「隣の部門ともデータを共有できていない」「データの準備・整形に手間がかかる」「どのように分析を始めればよいか」「新たな分析を“やってみる”環境がない」「業務プロセスへの組み込みに手間がかかる」「AIの判断基準を説明する必要がある」といった課題に直面しているのだ。
加えて久保氏は、「全社的にデータ活用を促進していくためには、チーム・コラボレーションの強化も忘れてはなりません」と説いた。
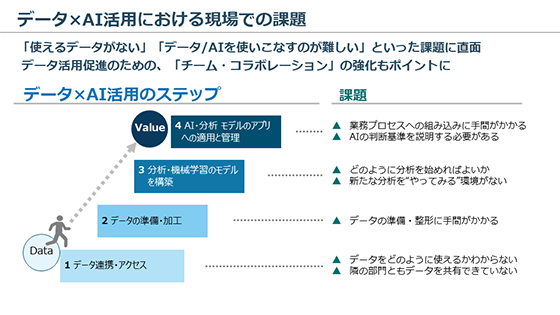 データ×AI活用における現場での課題
データ×AI活用における現場での課題このようにデータ×AI活用では、データ準備から分析の効率化、データ活用サイクルの自動化(AI/機械学習の活用)に至るまで、エンドツーエンドの取り組みを通じてデータ環境のモダナイゼーション(近代化)を図っていく必要がある。
では、この課題をいかにして解決していくか――。IBMは「AI Ladder」と呼ばれるアプローチを提唱している。さまざまな場所に散在する多様なタイプのデータに対し、シンプルなアクセスを実現する「COLLECT」に始まり、データを実際の業務で利用できる状態に整備する「ORGANIZE」、獲得したインサイトをAIとともにスケールさせる「ANALYZE」を経て、信頼性のあるAIを業務に組み込む「INFUSE」へと発展させていくものだ。
「この取り組みをフルサイクルで支援する、全社横断のデータプラットフォームをIBMは提供しています」と久保氏は訴求した。
 IBMの「AI Ladder」というアプローチ
IBMの「AI Ladder」というアプローチチーム連携の促進&アジリティの強化へ
DXを支える全社横断データプラットフォームのポイントの1つとして、久保氏が挙げたのは「チーム連携の促進」および「アジリティの強化」である。
利用者の視点からデータ活用のプロセスを見ると、その全体作業のうちの8割がデータ準備に費やされているのが実情だ。「このデータ準備作業を極小化し、誰もがもっとデータ利用に専念できる環境の整備が必要です」と久保氏は語った。
そこでIBMでは、データ準備の作業をより細かく「探索」「確認」「加工」の3つのステップに分解し、それぞれの効率化とスピードアップを実現するために、次のような機能を提供しているという。
1つ目の「探索」を強化するのはデータカタログだ。ユーザーが目的に合った正しいデータを、ビジネス用語を用いて探して取り出せるようにする。また、AIによるビジネス用語とIT資産の自動マッピングで登録作業を軽減する。
2つ目の「確認」を強化するのはデータプロファイル。定期的に対象データをモニタリングし、欠損値や外れ値、ばらつきなどの品質状態をあらかじめ把握し、修正する。
3つ目の「加工」を強化するのはセルフETL。ユーザー自身が、さまざまなデータをGUIで簡単に加工することができる。スケジュール機能を利用すれば一度実行した手順を覚えて、同じ処理を自動で再実行も可能だ。
 データ準備 (探索・確認・加工) の効率とスピードを強化
データ準備 (探索・確認・加工) の効率とスピードを強化低コストでオープンなデータプラットフォームを徹底追求
もう1つの重要なポイントとして久保氏が挙げたのは、データ提供者の視点に立った「低コストでオープンなデータプラットフォーム」であることだ。
これまで全社横断のデータプラットフォームを実現するためには、さまざまなシステムに分散しているデータの全量をコピーして蓄積する大きな基盤(データウェアハウス)を構築する必要があった。ハードウェアの調達や各システムからバッチでデータを集めてくる仕組みづくりなど多大な初期コストをかけながら、結局だれにも使いこなせず放置されてしまうことも珍しくない。「そんな失敗に陥らないためにも、低コストでスモールスタートできる枠組みが重要なのです」と久保氏は強調した。
この取り組みの中で、先に述べたデータカタログと共に大きな役割を果たすのが「データ仮想化」の機能である。簡単に説明すれば、クラウドやオンプレミスに点在する複数のデータソースを、物理的に1箇所に集めることなく仮想的にデータ統合し、データの照会や更新、演算処理を行うことができる最先端テクノロジーだ。これにより「スモールスタートでさまざまなユースケースを順次試し、効果を確認しながら、データプラットフォームを段階的に拡張していくことができます」と久保氏は語った。
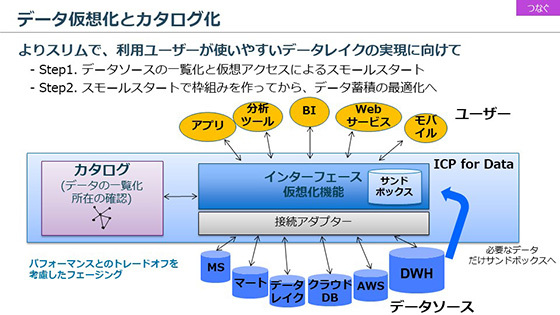 データ仮想化とカタログ化
データ仮想化とカタログ化そしてIBMでは、上記のようなデータ利用者と提供者の双方のニーズに応えるデータプラットフォームのソリューションとして「IBM Cloud Private for Data (ICP for Data)」を提供する。2019年2月に開催されたグローバル・カンファレンス「Think 2019」では、Watsonサービス群とICP for Dataの統合も発表され、マルチクラウド環境でのデータ×AI活用をさらに加速させていく考えだ。
●お問い合わせ先

日本アイ・ビー・エム株式会社
URL: ibm.biz/ICP4D_jp
- データドリブン経営の実践に向けて、データトランスフォーメーションのための変革のポイント(2019/05/10)
- 世界140万人以上の技術者の知見が活用できる「Topcoder」の仕組みと先端システムの開発事例(2019/04/16)
- 急増するデータから将来を洞察するために――BIツールを革新する“3つ”のトレンド(2019/04/15)
- 行動に潜むニーズを顧客データから洗い出す! AIの自動分類が営業高度化の“鍵”に(2019/04/10)
- デジタル化を実践する上で重要なのは「Why-What-How」――部分最適に陥らないためのプロセスとプラットフォームの在り方とは(2019/04/08)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
