Web 3.0により、データは「個」による自律分散型の管理へ移行すると言われている。その中では、情報資産を「個」同士が直接交換するため、「個」同士の「信用」がより重要となる。その信用を得るためには、データの「品質」を適正に管理・運用する「データマネジメント」を推進していくことが重要だ。2023年3月9日に開催された「データマネジメント2023」のセッションで、NTTデータ バリュー・エンジニア(旧:リアライズ)の内田司氏が、Web 3.0時代のデータマネジメントについて解説した。
Web 3.0時代のデータマネジメントで着目すべき2つの価値
 株式会社NTTデータ バリュー・エンジニア データマネジメント事業本部 データ事業統括部 部長 内田司氏
株式会社NTTデータ バリュー・エンジニア データマネジメント事業本部 データ事業統括部 部長 内田司氏2022年6月、日本政府が発表した「経済財政運営と改革の基本方針 2022」において、Web 3.0を国家方針として推進していくことが閣議決定された。その中ではブロックチェーン技術や、NFT(Non-Fungible Token:非代替性トークン)、DAO(Decentralized Autonomous Organization:分散型自律組織)の利用など、Web 3.0の推進に向けた環境整備の検討を進めていくことが記述されている。また、同閣議の決定以降、政府内におけるWeb 3.0の取り組みに向けた動きも活発化している。
しかし、Web 3.0とはそもそも何を指し示すのか。その定義はまだ明確に定まっておらず、漠然としているのが実情だろう。しかし、NTTデータ バリュー・エンジニア (旧:リアライズ)でデータマネジメント事業本部 データ事業統括部 部長を務める内田司氏は、「Web 3.0の時代を迎える中で、データマネジメントの観点から注視すべき価値は2つあると考えている。それは『データの価値化/資産化』と『分散化』である」と訴える。
はじめにデータの価値化/資産化について説明していこう。現実世界においては木や土、水といった様々な資源が存在しており、木を加工すれば木材に価値化される。そして木材は家具に加工されることで、さらに新しい価値が生み出される(図1)。
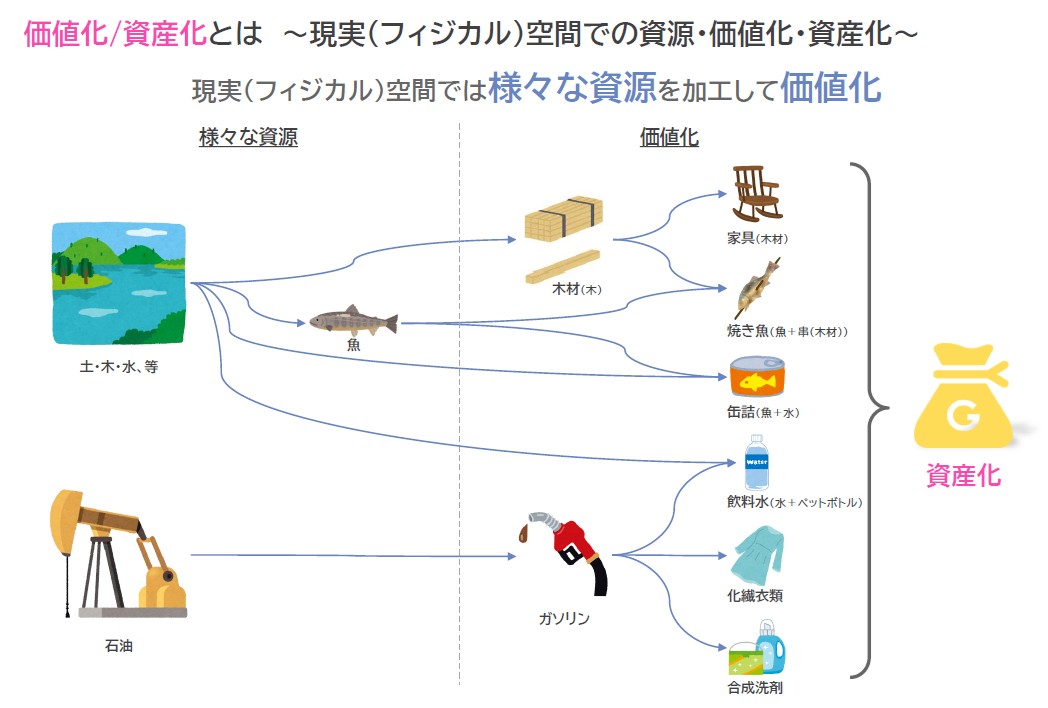 図1 現実空間では様々な資源を加工して価値化する
図1 現実空間では様々な資源を加工して価値化する拡大画像表示
対して仮想空間では、データが唯一無二の資源となる。データはあらゆるものに形を変えることで価値化され、資産を生み出す。分析レポートやメタバース上の構造物はその一例だろう。また、物理空間では価値がないと思われていた、「コト」「モノ」もデータ化、精錬されることで新たな価値を生み出し、資産へと変わるようになる(図2)。
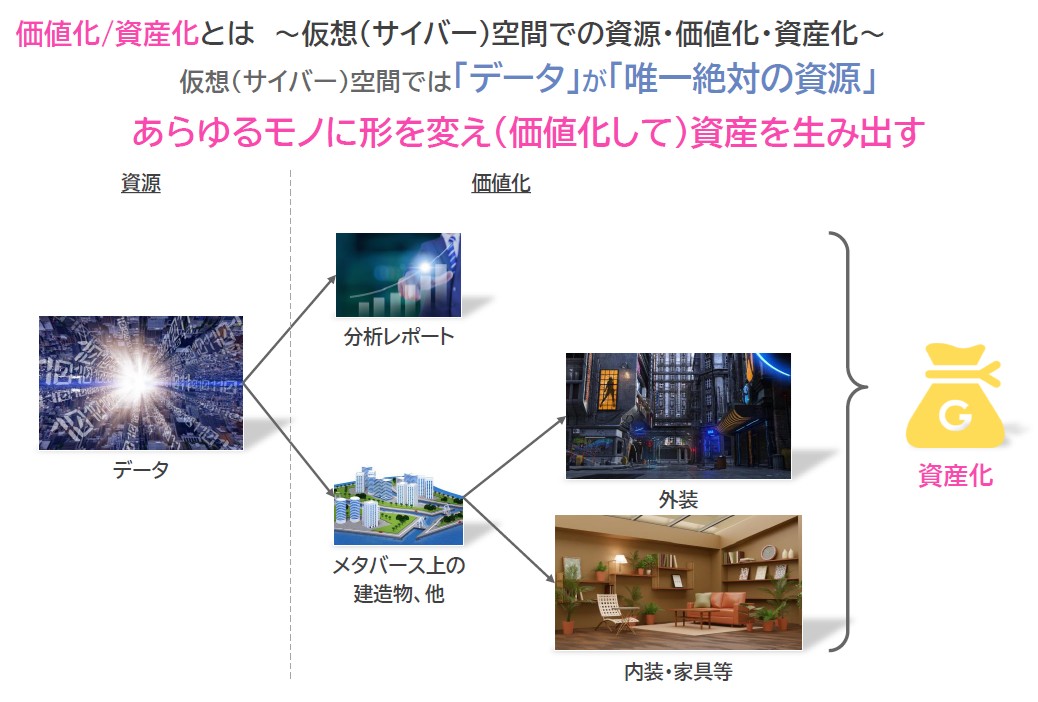 図2 仮想空間ではデータがあらゆるモノに価値化され、資産を生み出す
図2 仮想空間ではデータがあらゆるモノに価値化され、資産を生み出す拡大画像表示
「Web 3.0の時代はサイバー空間上に立ち上げられた市場が隆盛し、そこでは唯一の資源となるデータの価値や品質が問われるようになる。その品質を守るために、データマネジメントがより一層求められるようになる」(内田氏)。
続いて分散化について説明しよう。Web 2.0の時代、データはプラットフォーマーによって集中管理されていた。つまり、データを提供する、利用するユーザーに関する信用はプラットフォーマーが肩代わりしていたとも言える。対してWeb 3.0では、データは分散管理されるようになり、取引するお互いがピアツーピアで繋がるようになる。すなわち、取引相手と個々に信頼関係を築き、信用を得るような時代となる(図3)。
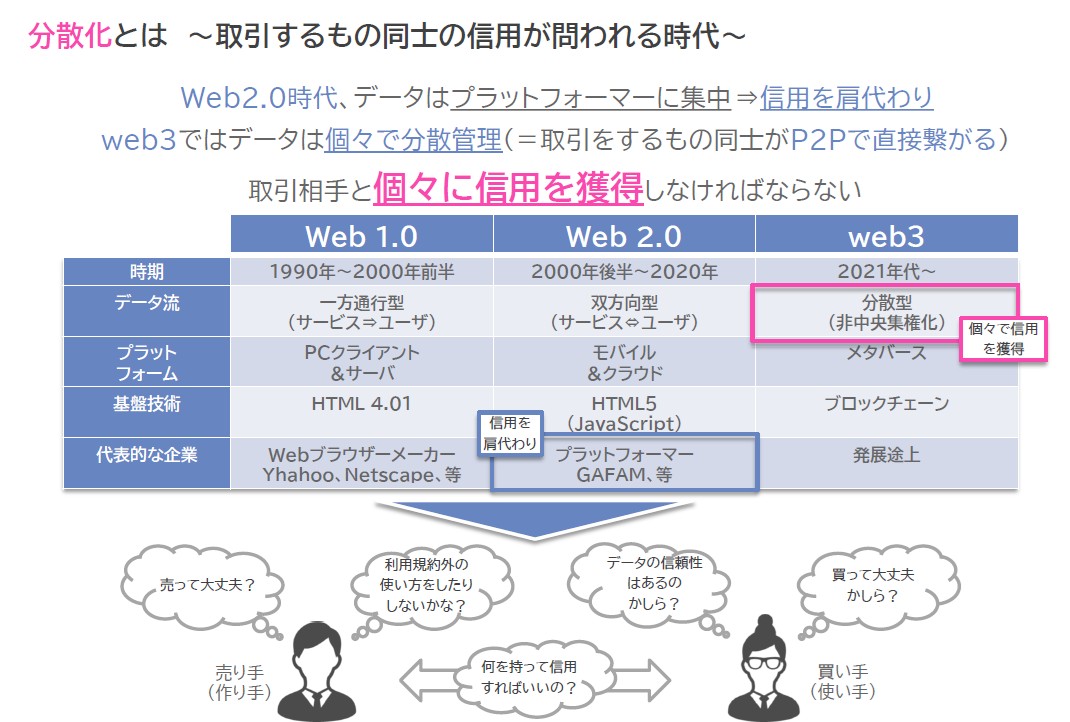 図3 Web 3.0時代では取引相手と個々に信用を獲得しなければならない
図3 Web 3.0時代では取引相手と個々に信用を獲得しなければならない拡大画像表示
では、何をもって取引相手を信用すればよいのか。相手からの信用を得るためには、「お互いがデータを正しく運用している」ことを証明しなければならない。作る側は「なぜ」「いつ」「どこで」「だれが」「どのような」データを「どうやって」作ったのか、しっかり証明する必要がある、一方、データを利用する側も同様の視点に基づき、利用の正当性を証明しなければならない。「そうしたお互いのデータの生成・運用の正当性を証明するものが、データマネジメントである。そうしたことから、データマネジメントとはWeb 3.0の時代に生き残るためのチケットと言えよう」と内田氏は訴える。
「データマネジメントによって担保されるデータの価値と信用関係こそが、Web 3.0時代の信用基準となるのだ」(内田氏)。
信頼性をどう確保する? 求められるデータの品質
データの信頼性を担保するためには、データ自体の品質、および生成されるプロセスに関する品質の2つを保証することが重要となる。内田氏は、「そこで、我々はデータとプロセスの品質を保証し、信頼性を保つために必要な16の観点で整理した」と語る。
これらの観点は、具体的にデータマネジメントでは、どのように関与していくのか。役所での書類申請フローを例に見ていこう(図4)。
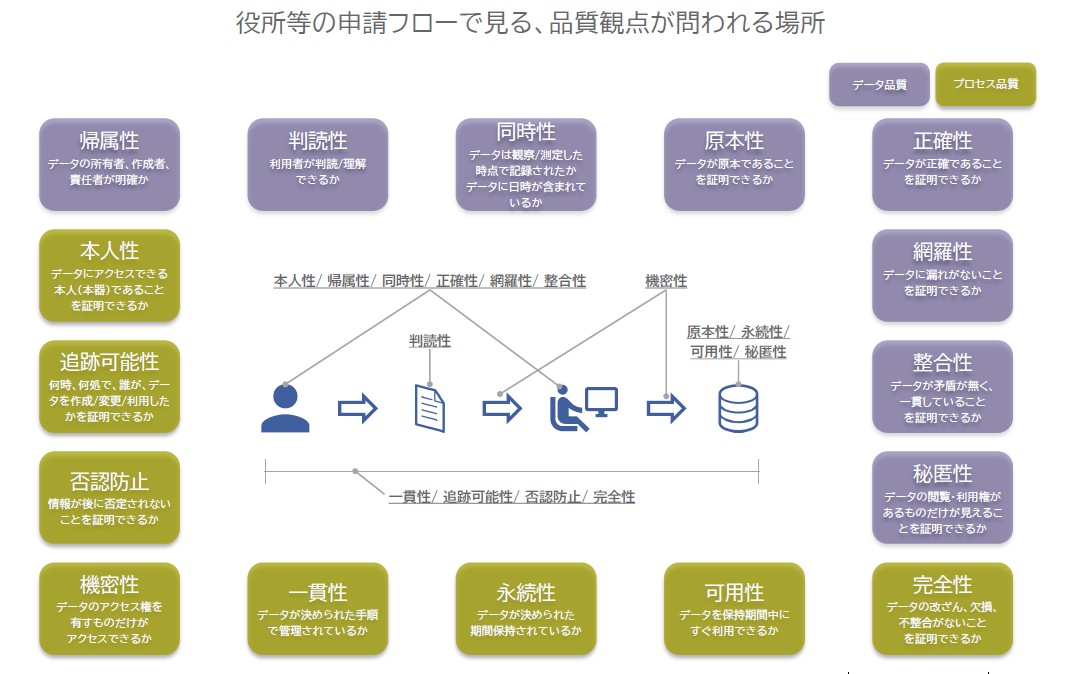 図4 Web 3.0時代で留意すべき品質観点
図4 Web 3.0時代で留意すべき品質観点拡大画像表示
申請者が申請書を記入し、職員がその情報を電子化、さらにシステムに格納する、という一連のフローがある。このフローにおいて、申請者と職員が確保しなければならない信頼性の要件には、「帰属性」「同時性」「正確性」「網羅性」「整合性」「本人性」がある。また、申請書類については「判読性」が求められる。さらに申請書が職員からシステムへと亘っていく過程には「機密性」が求められ、格納されるシステムには「原本性」「永続性」「可用性」「秘匿性」といった要件が必要となる。そして、これらの一連のフローにおいても、「一貫性」「追跡可能性」「否認防止」「完全性」を確保しなければならない。
このように信頼性を保つための要件は多岐に亘るが、これらの多くは、ブロックチェーン等のWeb 3.0のテクノロジーを適用することで解決可能と考えられる。一方、判読性、同時性、正確性、網羅性、整合性、秘匿性の6つの観点はデータの品質を保つうえで「要」となるが、Web 3.0のテクノロジーだけでは解決が困難なケースも少なくないと思われる。
では、いかにしてデータの品質を守っていけばよいのか。データの実態の品質を確保することは重要である。一方、その実態を説明する「メタ情報」の品質を確保することも、データの信頼性を向上し、かつ、データを適切に価値化するのに不可欠となる。つまり、Web3.0時代のデータマネジメントでは、データの実態とメタデータの2つが整備することが肝要となる。
Web 3.0時代のデータマネジメントを支援する多彩なソリューションを提供
NTTデータ バリュー・エンジニアはデータマネジメントの専門会社として、長年、データ品質の確立からそれを持続させるための活動を支援し続けてきた。その実現に向けて、多彩なソリューションを提供している(図5)。
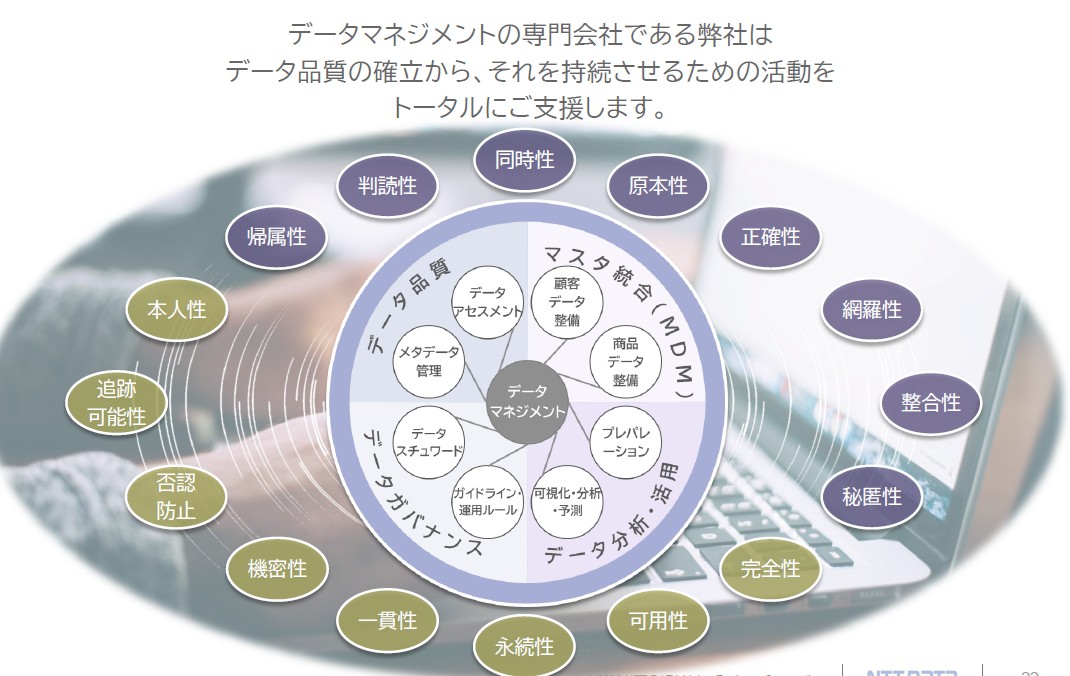 図5 NTTデータ バリュー・エンジニアがサポートするデータマネジメントの領域
図5 NTTデータ バリュー・エンジニアがサポートするデータマネジメントの領域拡大画像表示
その1つが、「データアセスメントソリューション」で、データについて「定量的分析」「定性的分析」の2つのアプローチで評価するもの。定量的分析はいわゆるデータプロファイリングであり、どのような項目にどのような値が格納されているのか、統計を取得、分析する。
定性的分析では、定量的には把握しづらい「趣旨違い」「趣旨混在」「表記ゆれ」「文字欠損」「文字化け」「異常値」といった大きく6つの観点でデータの問題を分析するサービスで、これらの6つの観点に基づきデータの異常性をあぶり出すことが可能だ。
これらのアセスメントの結果に基づいた、データ整備を行うソリューションも提供している。データの「実態」「構造」「運用」の3つの視点からのアプローチにより、データ整備に向けた問題、課題を整理する。このソリューションでは、実際のデータの振舞いや異常性を探り出し、クレンジングや名寄せといった対処も行う。
さらに、データカタログ整備ソリューションでは、要件定義から始まり、ツール構築、運用体制の整理とメタデータ登録、利用促進・効果測定をサポート。その成果物としてエンティティ定義シートを提供、企業・組織のカタログ作成を支援する。してもらうことを支援している。そして、データガバナンスソリューションでは、品質を向上させたデータやメタデータを劣化させないための制度・体制・運用の構築をサポートしている。
「私たちはこれらのソリューションでWeb 3.0時代のデータマネジメントを牽引していく」と内田氏は訴え、セッションの幕を締めた。
●お問い合わせ先

株式会社NTTデータ バリュー・エンジニア
- データマネジメント変革で直面する3つの壁の正しい乗り越え方(2023/05/23)
- “攻め”と“守り”を両立―AIとBI分析の要件を満たすストレージとは(2023/05/10)
- AI活用で目指すべきは“脱DWH”データレイクとDWHのデータを統合管理する真の“データ活用”時代の「レイクハウス」(2023/05/09)
- データ統合基盤の課題を解決する「論理データファブリック」のメリットとは(2023/05/01)
- 変化の激しい時代を乗り越えるためにはトップアプローチが重要、経営層が適切なデータ活用を行うためのコツ(2023/04/25)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
