[インタビュー]
次に来るデータ統合基盤「データファブリック」の本質を理解する
2024年6月13日(木)田口 潤(IT Leaders編集部)
データを駆使した業務効率や売上げの向上、変化に柔軟に対応するデータドリブン経営の実践、あるいは生成AIを含めたAI活用の推進──。これらの実現に向け、データの収集から活用をサポートするデータ統合基盤はきわめて重要だ。しかし、その有力な候補とされるデータファブリックやデータメッシュへの理解はあまり進んでいない。そこで米ガートナーのアナリストに、それらが登場した経緯や解決できる課題など、本質の部分を聞いた。
 写真1:米ガートナーのバイスプレジデント アナリスト、エティシャム・ザイディ氏
写真1:米ガートナーのバイスプレジデント アナリスト、エティシャム・ザイディ氏2023年4月に、「データファブリック」「データメッシュ」とは何か? データ統合の最前線を専門家に聞くという記事を掲載した。
欧米のIT関連サイトだけでなく、外資系のデータ関連ベンダーを中心に、日本でもこれらの用語を目にする機会が増えていたからだ。できるだけかみ砕いて書いたつもりだったが、改めて読み直すとそうではなかった。
記事に間違いがあったわけではないが、技術面、あるいは仕組みに関する説明が多く、データファブリックやデータメッシュが必要な理由が少なかった。そこで、米ガートナー(Gartner)のバイスプレジデント アナリスト、エティシャム・ザイディ(Ehtisham Zaidi)氏(写真1)に取材し、改めてデータファブリックやデータメッシュについて、本質を確かめてみた。
結論の一部を先に書くことになるが、ザイディ氏からは以下のような発言があった。できれば、上の記事と併せてじっくりお読みいただきたい。
①データファブリックはデータ統合基盤の現実解である
②データファブリックにおいてはメタデータマネジメント(作成、管理、共有など)がきわめて重要である
③データメッシュはともかく、その一端を成すデータプロダクトは理解・実践するべき概念である。
データレイクハウスは万能か
──データ統合は多くの企業にとって大事な取り組みで、実際、日本でも大手を中心にデータレイクを構築する企業が増えています。また、論理的にデータ統合するデータ仮想化に着手する動きもあります。その次にデータファブリックやデータメッシュが来ると言われますが、この分野のハイプサイクル(図1)を見ると様子が違います。
ザイディ氏:どんなところでしょう。
──データファブリックはピークを越えて下り坂、データメッシュはこれからピークを迎えるとなっています。今のそれらの位置づけや必然性について教えてください。データファブリック、データメッシュはどういうシーンで必要になるのか、データレイクやデータ仮想化との関係はどうか、といったことです。
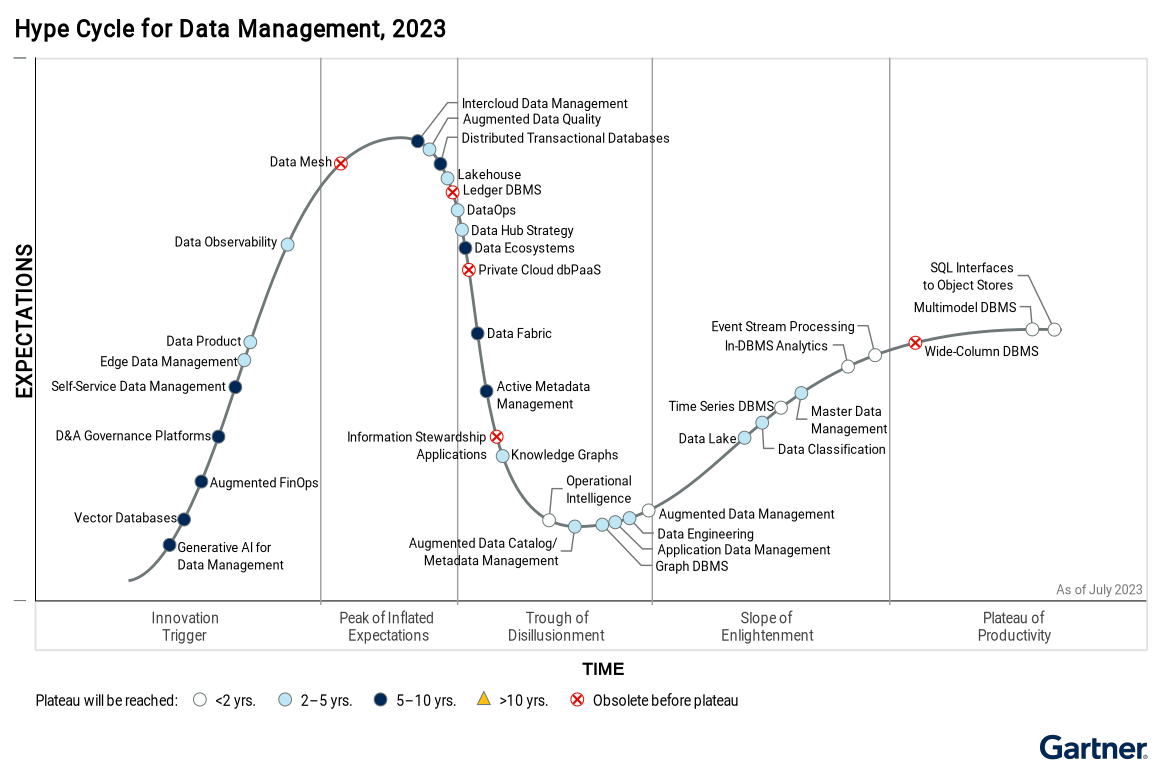 図1:データマネジメント分野の技術ハイプサイクル(出典:米ガートナー「Hype Cycle for Data Management 2023」)
図1:データマネジメント分野の技術ハイプサイクル(出典:米ガートナー「Hype Cycle for Data Management 2023」)拡大画像表示
確かに、データファブリック、データメッシュがどうして生まれたのか、どんな必然があるのかを理解することは重要です。できるだけわかりやすく説明しましょう。まず、ご指摘のとおり、企業や組織は少し前まではデータウェアハウス(DWH)、ここ数年はデータレイク、そして最近ではそれらを一緒にしたデータレイクハウスを構築するようになっています。今日、データアナリティクスやデータサイエンス、AIなどのインフラとして最も多く選ばれているデータ統合基盤がレイクハウスです。
しかし、レイクハウスのようなアプローチにはいくつかの懸念事項があります。ありとあらゆるデータを1カ所に、物理的に集中することがその1つです。データレイク/レイクハウスのベンダーが推奨していますし、分かりやすいので多くの企業や組織がそうしようとしますが、現実問題としてレイクハウスに入れられないデータもあります。
──データ権限や、データボリュームなどの問題からでしょうか?
はい。加えて数十年運用してきたオンプレミスのデータを入れるとなると、データモデルを作り直す必要が生じる可能性もあります。Oracle DatabaseやIBM Db2などのRDBMS、TeradataのようなDWHは規模も大きいですよね。技術的な意味も含めて、すべてのデータを本当に集中化できるか、1つに集められるかという話です。
2つ目は、レイクハウスの運用コストが上がり、アナリティクスの計算リソースも増加することです。物理的に集中させることにとらわれると、ずっとその問題と直面する状況に陥ります。結局のところ、あらゆるデータをレイクハウスに集めるのは単純で分かりやすいのですが、データに関するさまざまな要求には応えきれないことを理解する必要があります。
というのも、企業や組織が今抱えているデータに関する課題は、データ分析やデータサイエンスだけではありません。企業同士、例えば自社とパートナー企業、サプライヤーや顧客とデータをやり取り/共有するようなケースもあります。このようなオペレーション上のデータ連携、さらにマスターデータ管理(MDM)のシナリオも視野に入れると、レイクハウスにすべてを集中させれば事足りるわけではないのです。
データを1カ所に物理統合するアプローチはいずれ限界に
──DWHやレイクハウスは、データ統合の最終的なソリューションではないと?
そうです。ベンダー各社は概ね5年や10年ごとに新しいデータプラットフォームを提案し、「あれはもう時代遅れ」「これがベストインクラス」などと喧伝します。10年前のApache Hadoop、5年前のデータレイクを経て今のブームはレイクハウスです。数年すればまた別のものが出てくるでしょうが、ユーザーの立場に立てば「そのたびにすべてを物理的に移行するの?」という話になります。
この問題を解決するのが仮想化です。ロジカルなDWHの構築をサポートするもので、データ統合手法の1つです。分散して存在するデータソースから物理的にデータを1カ所に集めるのではなく論理的につなぐことで、データ分析など必要なときにアクセスできます。コレクト(Collect)ではなくて、コネクト(Connect)というわけです。
ロジカルDWHは、DWHとデータレイクとデータ仮想化を組み合わせたものと言えます。物理的なデータ統合に比べて 試行錯誤的な分析と相性がよく、例えば何らかの仮説を思いついたら、ローコストで迅速にデータを扱えるようにできます。
──なるほど。でも、仮想化にも問題や限界がありますよね?
もちろん。安価にできるとはいえ、データ量が多かったりデータ変換が複雑だったりする場合、仮想化を多用するとパフォーマンスに影響が出てしまいます。ですから、仮想化はETLやレプリケーション、ストリーミングなどと組み合わせて使う。つまり仮想化でそれらを置き換えるのではなくて互いを補い合う形で活用するのがよいです。
加えて、仮想化やロジカルDWHにはこんな問題があります。1つは手作業で作ったり保守したりする必要があることです。コレクトやコネクトの結果として生じるデータの増大に対し、人員を増やして備えることはできませんから、もっと自動化できるようにしなければなりません。さらに、オペレーショナルなデータの連携、つまり企業間データ共有やアプリケーション連携にも課題が残ります。こうしたことが次の進化であるデータファブリックの登場を促しました。
●Next:データファブリックへの移行方法、「アクティブなメタデータ」とは?
会員登録(無料)が必要です


- 1
- 2
- 3
- 次へ >
データファブリック / データ統合 / データレイク / データレイクハウス / DWH / ETL / データメッシュ / Gartner / ハイプサイクル / データ活用基盤 / データカタログ / アナリティクス / データプロダクト / メタデータ管理 / データリネージ



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
