FastLabelは2024年9月12日、大規模視覚言語モデル(VLM)を開発・活用するためのSIサービス「VLM開発用データ 支援サービス」を提供開始した。学習データの収集、データセットの販売、アノテーション、RAG(検索拡張生成)データ作成などの提供を通じて、顧客企業のVLM開発・活用を支援する。
FastLabelの「VLM開発用データ 支援サービス」は、大規模な視覚言語モデル(Vision Language Model:VLM)の開発・活用を支援するSIサービスである。
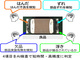
VLMは、テキストと画像の両方を理解して処理を行うAIモデルである。画像の内容を理解したうえで質問に答えたり、画像に基づいたテキストを生成したりすることができる(画面1)。
 画面1:視覚言語モデル(VLM)の活用例(出典:FastLabel)
画面1:視覚言語モデル(VLM)の活用例(出典:FastLabel)拡大画像表示
「GPT-4oやGeminiなどの登場により、VLMの活用が期待されている一方で、学習データが揃いにくいという問題がある。社内に存在するデータのみで十分な品質と量を確保できない場合、外部から大量のデータを、権利がクリアな状態で調達する必要がある」(同社)
顧客企業に向けて主に以下を提供し、データ収集・作成に携わる人員不足やデータ品質の確保といった課題を解決する。
(1)VLMの学習データ用データセット
VLMの学習データとして利用する画像・動画・文書のデータセットをFastLabel自身が構築して販売する。権利関係のリスク問題をクリアして利用できる。また、同社のパートナーであるストックフォトサービスが所有する100万点超の画像・動画・文書データをVLMの学習データとして利用できる。
データの品質に関しては、正確性や多様性に関する品質管理基準を設定し、データの作成工程や作成後の品質検査工程において、その基準に適合しているという。
(2)データセットに対するVLMアノテーション
上記のデータセットに対し、VLMのためのアノテーション作業を代行する。顧客企業が管理する機密性の高いデータについても、FastLabelのストレージに保存することなくアノテーションが可能。キャプション付け、矩形で指示した画像の特定領域を根拠としたQA、多肢選択式のQA、OCR(光学文字認識)などを行う。
検品プロセスでは、必要に応じて企業側でランダムサンプリングを用いた抜き取りでの受け入れ検査が可能である。
(3)マルチモーダルRAGデータ作成
PowerPoint/PDF/Excelなどの図表を含む文書ファイル、画像・動画ファイルのほか、IR情報などの外部情報を基にマルチモーダルRAGデータを作成する。
FastLabelは今後、複数の顧客へのデータ提供を通じて、データ品質基準の整備や品質定量化手法の開発を進めていくとしている。


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
