「生成AIが急速に普及するにつれ、データの利用は、応用ごとに個別の機械学習モデルを作るやり方から、汎用の基盤モデルを共通部品として使うやり方に変化しつつある」──。2026年3月11日開催の「データマネジメント2026」(主催:日本データマネジメント・コンソーシアム〈JDMC〉、インプレス)の基調講演に、東京大学 人工物工学研究センター 上席研究員/Preferred Networks(PFN)取締役の丸山宏氏が登壇。「生成AI時代のデータマネジメント」と題した講演で同氏は、大規模言語モデル(LLM)を部品として活用するシステム設計の方法論を解説すると共に、PFNと花王の共同研究開発プロジェクト「仮想人体生成モデル」を通じて、データ収集の目的設計・品質管理・ガバナンス体制の構築が生成AI時代のデータマネジメントの核心であることを示した。
「生成AIが急速に普及するにつれ、データの利用は、応用ごとに個別の機械学習モデルを作るやり方から、汎用の基盤モデルを共通部品として使うやり方に変化しつつある」──。
「AI Ready Dataに舵を切れ」をテーマに掲げたデータマネジメント2026の基調講演に、東京大学 人工物工学研究センター 上席研究員/Preferred Networks(PFN)取締役の丸山宏氏(写真1)が登壇。「生成AI時代のデータマネジメント」と題した講演は、大規模言語モデル(LLM)を部品として活用するシステム設計の方法論の解説から始まった。
 写真1:東京大学 人工物工学研究センター 上席研究員/Preferred Networks取締役の丸山宏氏
写真1:東京大学 人工物工学研究センター 上席研究員/Preferred Networks取締役の丸山宏氏拡大画像表示
「LLMは本質的に統計モデル」─3つの構造的限界
生成AI時代のデータマネジメントを考察する前提として、丸山氏は、「機械学習、深層学習、LLMは本質的に統計モデリングである」ことを指摘した。統計モデリングは、変数間に現れるパターンをデータから学習し、パラメータで表現する手法である。「LLMも同じ原理であり、大量の言語データから、『ある文脈が与えられた時に次に来る単語の確率モデル』を学習している」(同氏、図1)。
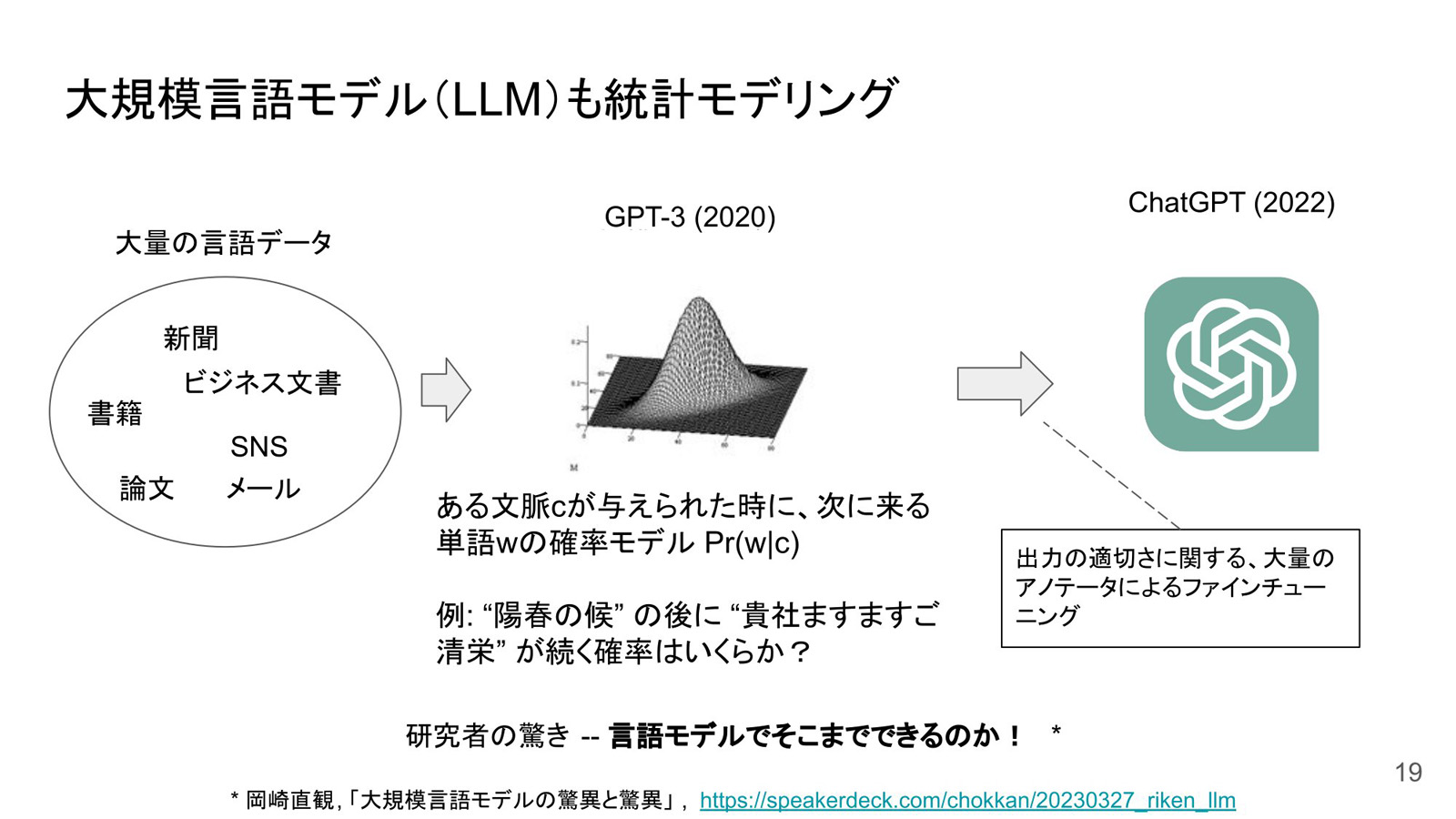 図1:LLMは統計モデリングであり、大量の言語データから「ある文脈が与えられた時に、次に来る単語の確率モデル」を学習している(出典:Preferred Networks)
図1:LLMは統計モデリングであり、大量の言語データから「ある文脈が与えられた時に、次に来る単語の確率モデル」を学習している(出典:Preferred Networks)拡大画像表示
統計モデリングには3つの限界がある、と丸山氏は説く。1つは、過去のデータで訓練しているため、過去と未来の連続性を前提としており、この仮定が崩れた瞬間に予測が無力となること。2つ目は、訓練データセットは有限であるため、学習した分布の外側の領域では精度が落ちること。3つ目は、サンプリングにはバイアスがかかるため、100%の正しさを保証できず、ハルシネーション(事実と異なる出力)が生じることである。
「特に、ハルシネーションはモデルの欠陥ではなく、統計モデリングの構造的な宿命である。これを踏まえ、どのようなユースケースにAIを適用し、どのような品質検証プロセスを設計するかが、生成AI時代のデータガバナンスの核心になる」(丸山氏)
LLMは部品として使う─アルゴリズムとの組み合わせが成功の条件
上述を踏まえ、LLMの活用方法について丸山氏は、「LLMは部品として使うべきだ」と提案した。
同氏は米アップルが2025年6月に発表した論文「The Illusion of Thinking(思考の錯覚)」を引き、推論型LLMでさえ、パズルゲーム「ハノイの塔(Tower of Hanoi)」をディスク10枚程度で解けなくなることを示した。「一方、『ハノイの塔を解くプログラムを書いて』と指示すれば、すぐにコーディングしてくれる。つまり、アルゴリズムが得意な問題にLLMを単体で使うべきではない」と結論づけた。
「LLMの成功事例に共通しているのは、LLMを部品として使い、従来のアルゴリズムや体系化された知識と組み合わせていること。生成AIはそのままでは万能ではない。LLMを部品として捉え、従来のシステムと組み合わせることではじめて実用的な価値を生む」(丸山氏)
その例として、「AlphaGo(アルファ碁)」はゲーム木探索が骨格であり、深層学習は盤面評価関数の一部品として機能していることを挙げた。また、Google DeepMindの「FunSearch」は、探索プログラムの骨格を人間が定義し、ヒューリスティクス関数の提案のみをLLMに担わせることで数学の未解決問題に新たな解を発見した。米スタンフォード大学の「Biomni」は、150以上の専門ツールと59のデータベースをAPI経由で統合した環境において、LLMが研究計画の立案からコード生成・実行までを自律的に遂行するという。
●Next:データの所有やデータ量の大きさが競争力を決める時代は終わり
会員登録(無料)が必要です


- 1
- 2
- 次へ >
大規模言語モデル / 生成AI / 製造 / R&D / データサイエンティスト / 花王 / Preferred Networks / 東京大学 / アナリティクス / 医療 / マーケティング / ヘルスケア / ヘルステック / 健康管理 / 健康経営 / Matlantis




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
