米Googleがロボット関連技術を持つ企業を次々と買収している。その背後にはどのような狙いがあるのか。視線の先にあるのが、ビッグデータを活かしたスマートマシンだ。
荒涼とした山岳地帯を自在に駆け回るロボット、2足歩行どころか飛び跳ねたり、前転したりできるロボット──。そんなロボットがすでに誕生している。状況認識や推論、自己学習といった知的な能力が、そこに加わるとどうなるだろうか?ある面では人間を超える、あるいは置き換える存在になることは間違いない。いわゆるスマートマシン(知性を持った機械)である(関連記事)。
その生みの親になろうとしているかに見えるのが米Googleだ。軍事ロボットの有力企業であるBoston Dymamicsを買収したことが、12月初旬に明らかになった。Boston社の技術がどれほど高度な動作であるかは、動画の「BigDog」や「Cheetah」を見れば、一目瞭然。日本のあるロボット専門家は「外から物理的な力が加わっても転倒しないBigDogの制御は、我々から見てもすごい」と言い切る。
Googleは過去半年間に、日本のロボットベンチャーであるSHAFT社(図1)を含む7社を買収済み。例えばSCHAFT社は東京大学のロボット研究者などが2011年に設立した企業。人間に近い2足歩行ロボットを得意とする。DARPA(米国防高等研究計画局)が主催した「DARPA Robotics Challenge TRIALS 2013」において、完全優勝した。
これら以外に買収したのは、Schaft、Industrial Perception(ロボットアーム)、Redwood Robotics(ロボットアーム)、Meka Robotics(ヒト型ロボット)、Holomni(アクチュエータ)、Bot & Dolly(ロボットカメラ)、Autofuss(画像処理)の6社。各社のWebサイトはトップページを除き停止されているが、世界的に見ても先進的かつ高度なロボット技術を自社に集積しつつある。

「Deep Learnig」で次世代の人工知能を実用化へ
メカニカルな機構だけではない。外部の状況を認識するセンサー関連の情報処理技術や高度な自己学習を行う技術の開発も進めている。大規模ニューラル・ネットワーク「Google Brain」がその中核の1つだ。その原理は、ニューロンとシナプスという人間の脳を模して機能するソフトウェアにある。
人間の赤ん坊が外界の刺激を受けて言語や物体を認識するのと同様に、新たな刺激を得ながらニューロンの値とシナプスの結びつきを自己組織的に変化させていく。画像認識や、音声認識など必要な機能を個別に開発する必要はなく、ニューロンとシナプスという単純な組み合わせをトレーニングすれば済むという”ワンプログラム”仮説がバックボーンとされる(図2)。
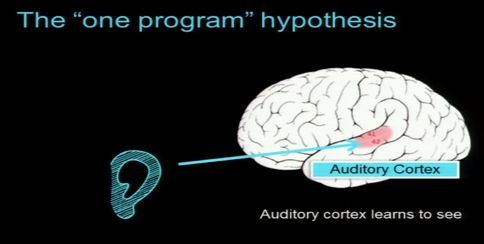
図2:ワンプログラム仮説
20年以上前に日本でも研究開発が盛んだった、いわゆる「ニューラル・ネット」そのものだが、当時のコンピュータ技術ではニューロン数が10数個、シナプスはその数倍~数十倍が限界だった。Google Brainは1万6000のCPUコアを用い、10億以上のシナプスを備える。桁違いの能力を備えるようになったニューラル・ネットは、最近では「Deep Learning」と呼ばれ、世界的に研究開発が進みつつある(後述)。
Deep Learning技術はその特性上、「なぜAをBと認識(判断)したのか?」という理由付けが難しい。それゆえ高度な論理処理=理由付けが不要な音声認識や画像認識の分野への適用が進む。例えば、YouTubeに納められた大量の画像から、猫を認識できるレベルになったことは大きな関心を集めた。その先には自然言語理解、それも主張や意味(ニュアンス)を含めた理解のためのシステムがあるという。
その技術開発を担保するのが大量のデータを集め、それを有益な情報に変えることに長けたGoogleのパワーだ。前者に関しては、検索エンジンだけで12億人近いユニークユーザーを擁し、月間のサーチ件数は125億件に達する。それに応えるべく、Googleは世界のWebサイト(ドメイン数は2013年に10億を超えた)をクロールし、情報を集めて処理している。ほかにGmailやYouTubeもある。圧倒的な情報量であり、文字通りの”ビッグデータ”である。
後者の好例は「reCAPTCHA」だ。Webサイトの利用者がコンピュータ(Bot)でないことを確認するために使われる、読みにくく加工された文字列を入力させるテストの1種がCAPTCHA(Completely Automated Public Turing Test to tell Computers and Humans Apart)。その際に正規のCAPTCHAだけではなく、OCRなどで認識できない文字画像を出力する。その文字を人間が入力するとデジタル化したことになる--この巧みな仕掛けが、reCAPTCHAだ。元々、カーネギーメロン大学が開発した手法であり、Googleが2009年に買い取っている。



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
