普段は意識しないが、データや情報のデジタル化、そして利活用に少なからぬ影響があるのが、語彙の定義や文字コードの問題だ。これらは今も、氏名を扱う情報システム、例えば電子政府や電子自治体などにおいて問題であり続けている。その解消に向けた大きな前進が、2015年9月末にあった。
業界や社会、国を超えてデータや情報を流通させ共有したい。そのためには何が必要か?──。この設問に対して、読者は何と回答するだろうか?「インターネットによって、すでに情報流通や共有は実現した。設問の意図が分からない」「情報を隠さずに公開することだろう」といったものかも知れない。しかし、実は非常に基本的なことが実現できておらず、データの流通や共有に悪影響を及ぼしている。
1つは、語彙が共通化されていないこと。例えば人を表すデータは、「氏名や性別、年齢、住所、勤務先」などで構成される。それを「名前、男女、歳、現住所、所属」とする場合もある。こうした共通性のなさが、データの連携や流通を阻害しているのは、システム責任者や担当者なら周知の通りだ。人間なら簡単に分かることでも、コンピュータは理解できないからである。
もう1つの問題は、文字情報表現の共通化だ。というのも日本語で使われる文字数は基本的なJIS第1水準漢字が2965字、馴染みが薄いJIS第2水準漢字が3390字と、約6300字もある。 戸籍名などに使われる文字などを総計すると約6万字にも上る。加えて、いわゆる外字が100万字以上も作られている。これらの文字すべてをユニークな形でコード化し、あるいは標準化・共通化しないと、データの交換や共有に不整合が起きてしまう。
こうした中、情報共有基盤推進委員会(須藤修委員長)が2つの問題解決に向けて取り組んできた。政府IT総合戦略本部の要請を受けて、経済産業省とIPA(情報処理推進機構)が設置した委員会で、共通語彙基盤ワーキンググループ(武田英明 国立情報学研究所教授)と文字情報基盤ワーキンググループ(林史典 聖徳大学教授)の2つを設置した。
語彙の共通化に向けた取り組みに関しては、関連記事:データ連携・流通に向けた「共通語彙基盤(IMI)」が誕生でレポートしたとおり、共通語彙基盤WG(Working Group)が基礎的な作業を終えた。基本的なコア語彙を定義し、それに則る形で観光や施設案内など複数の分野において、自治体と企業が組んで共通語彙の定義を進めている。
それに遅れること半年、この9月末になって文字情報基盤WGも作業にメドをつけた。約6万字を約1万字に対応付ける「縮退マップ」を完成したのがそれだ(WGでの配付資料)。戸籍名などで使用するマイナーな文字を、JIS X 0213で規定される 1万1233字にマッピングできるようになる。氏名を正確に表記する必要がある自治体などの業務において国際標準に基づく6万字を使い続けつつ、並行して日常的に氏名を表記する場合には市販の情報機器で使える文字にするイメージだ(図1)。
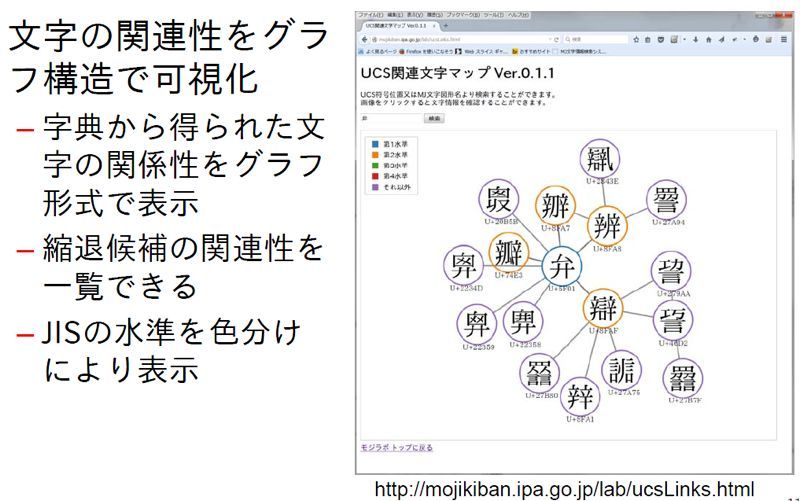 図1:文字の関連性を可視化する「文字関連マップ」
図1:文字の関連性を可視化する「文字関連マップ」拡大画像表示
●Next:日本語特有の文字への取り組み
会員登録(無料)が必要です


- 1
- 2
- 次へ >




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
