約130億件という膨大な診療記録の利活用を促進する試みとして「新たなエビデンス創出のための次世代NDBデータ研究基盤構築に関する研究」という注目プロジェクトがある。その背景や、現在までに乗り越えてきた壁、さらに採用されたテクノロジーなど、概要を紹介する。
約130億件という膨大な診療記録を“みんなが使える”データ基盤へと乗せることはできるのか──。世界に類を見ない規模の巨大な医療データを巡り、誰もが使えるビッグデータ基盤の構築、さらにはAIによるデータの利活用までを視野に入れて進められてきた研究プロジェクトがある。京都大学 医学部附属病院 医療情報企画部 教授 黒田知宏氏が率いる「新たなエビデンス創出のための次世代NDBデータ研究基盤構築に関する研究」がそれだ。国立研究開発法人 日本医療研究開発機構(以下、AMED)が2016年度の研究事業として公募/採択したプロジェクトの一つでもある。
本稿ではこの次世代NDBデータ研究基盤構築の概要を紹介する。なお、内容については、2017年10月に開催された「NTTデータ テクノロジーカンファレンス 2017」における黒田氏の講演──「みんなが使いやすいNDBを目指して - AMED臨床研究等ICT基盤構築研究事業『新たなエビデンス創出のための次世代NDBデータ研究基盤構築に関する研究』のご報告」──に基づいている。
国家レベルの医療データベース「NDB」
NDBとは「レセプト情報/特定検診等情報データベース(National Database of Health Insuarance Claims and Specific Health Checkups of Japan)」の略で、2008年に施行された「高齢者の医療の確保に関する法律」に基づいて収集された診療情報データを格納したデータベースである。研究期間として定められた2016年度末までに収集された約130億件の実データには「レセプト(医療報酬明細書)情報」と「特定健診等情報」が含まれ、当然ながらすべてのデータに匿名化処理が施されている。
 講演で壇上に立った京都大学 医学部附属病院 医療情報企画部 教授の黒田知宏氏
講演で壇上に立った京都大学 医学部附属病院 医療情報企画部 教授の黒田知宏氏2010年6月の閣議決定に基づき、NDBデータの第三者提供が開始。2016年10月からはオープンデータとしても提供されている。第三者提供を開始したのは、NDB構築のきっかけとなった高齢者医療確保法に基づく利用や政策決定だけではなく、「大学や民間の研究活動に幅広くこの膨大な医療データを活用してもらいたい」(黒田氏)という理由からだった。NDBは国民のほぼすべてのレセプト情報と特定健診情報が格納された、国家レベルのデータベースであり、より多くの研究機関や企業での利活用が進めば、日本の医療の質や臨床開発/研究が大幅に向上する可能性も高まる。
しかし、いざ第三者がNDBデータを利用しようとすると、そこにはさまざなまハードルが立ちふさがっていた。データは厚生労働省から提供されるのだが、利用者が第三者提供の申請を開始してから実際にデータが提供されるまでに要する期間は最短でも6カ月以上、さらに利用者は一定のセキュリティ要件を満たした施設と膨大なデータを取り込む機器を準備する必要があり、加えてデータベースを構築するための専門知識が求められる。たとえば施設のセキュリティ要件には、NDBデータを分析するための「医療情報解析室」を設ける必要があり、分析用のマシンや帳票出力のためのプリンタ、合議テーブルやホワイトボードまで含めたNDBデータ分析に関する一切がこの解析室内で完了していることが定められている。NDBデータを民間に幅広く活用してもらうにも、時間、場所、機器、人材など、あらゆる面で難易度が高すぎる状況にあった。
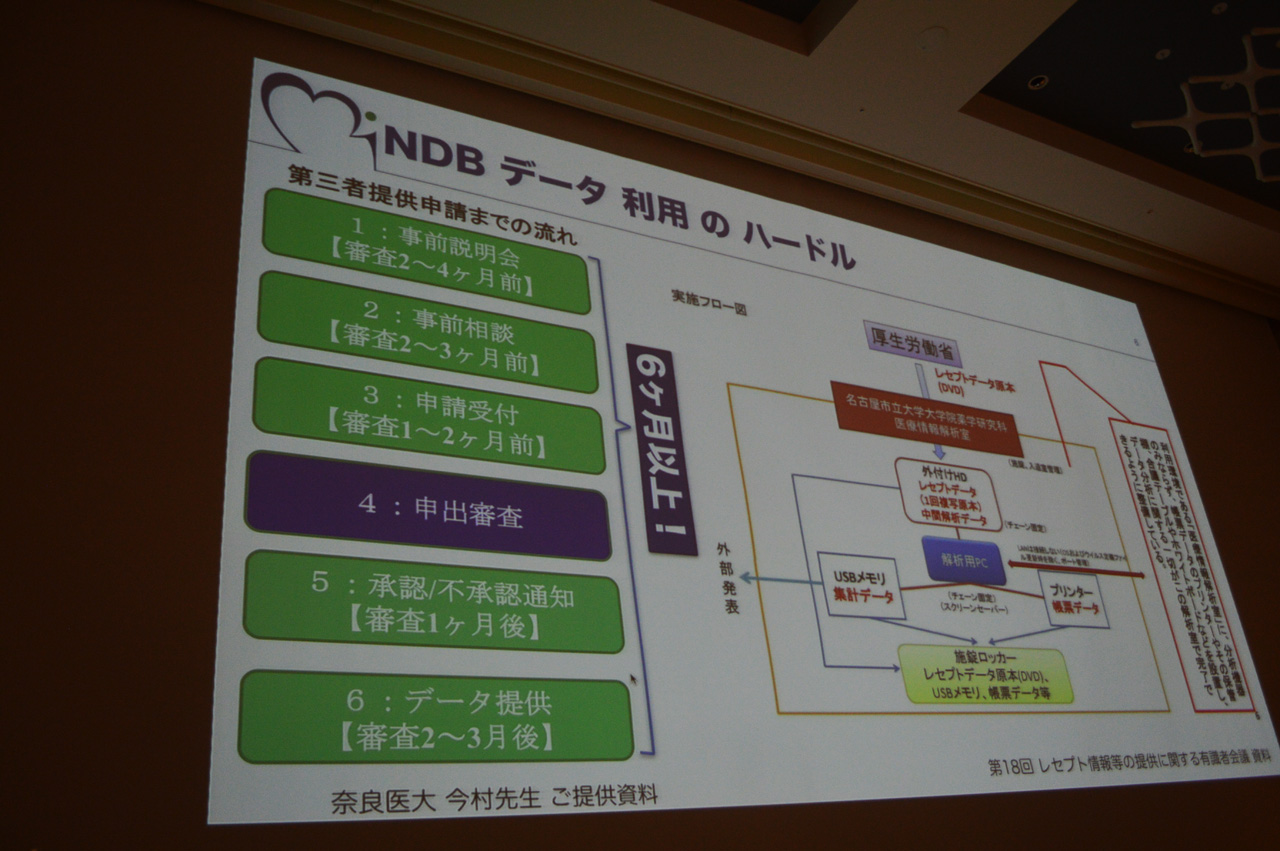 NDBデータを第三者が利用しようにも、利用申請から最低でも半年以上は必要で、さらに提供データを利用するには専用のデータ解析室が必要など、利用までに多くのハードルが存在していた
NDBデータを第三者が利用しようにも、利用申請から最低でも半年以上は必要で、さらに提供データを利用するには専用のデータ解析室が必要など、利用までに多くのハードルが存在していた拡大画像表示
この現状を緩和するため、特にセキュリティ環境を用意することが困難な研究機関などを対象に、プロジェクトでは2014年10月に東京大学などに「NDBオンサイトリサーチセンター」を設置、2015年4月から運用を開始している。NDBデータの申請を許可された利用者が直接オンサイトリサーチセンターに出向き、決められたデータにアクセス、分析ログは厚生労働省がすべて記録し、利用者には集計情報データのみを渡す、という運用で開始したものの、「(2017年10月時点で)いまだに第三者利用にたどり着いていない」(黒田氏)という残念な結果に終わっている。
 NDBデータの第三者による利用を促進するために設置された「NDBデータオンサイトリサーチセンター」だがデータが扱いにくい、センターのマシンが非力、手戻りが多いなどの理由から、ほとんど利用されない状態が続いていた
NDBデータの第三者による利用を促進するために設置された「NDBデータオンサイトリサーチセンター」だがデータが扱いにくい、センターのマシンが非力、手戻りが多いなどの理由から、ほとんど利用されない状態が続いていた拡大画像表示
浮かび上がったNDBの問題点
第三者の使いやすさを考慮して設置したはずのオンサイトリサーチセンターが、第三者に使ってもらえない──。NDBオンサイトリサーチセンターは何が問題だったのか。黒田氏は「運用上の問題」と「技術的な問題」をそれぞれ挙げているが、技術的な問題、つまり現行NDBの“使いにくさ”に関して以下のように深掘りしている。
現行NDB自身の課題
- ID問題 …ライフイベント(結婚や退職など)や氏名の誤記のため、 同一患者のIDが途中で切れてしまう
- 整理問題 … 同一入院のデータがバラバラのレコードに分散されてしまう
- 知識問題 … テーブルがばらついていて、どこに何があるかわからない
現行NDBシステムの構成上の課題
- 可用性問題 … データをダウンロードして非力な端末で分析するという前提
これらの問題に共通するのは、データを利用したい研究者はデータサイエンスの専門家ではないという点だ。加えてレセプト情報のデータ構造は非常に特殊であるのだが、利用者(研究者)はその特徴や構造を学ぶ機会はオンサイトリサーチセンターに出向くまで得られず、データの抽出や提供、操作の確認までに多大な時間を要することになる。また、レセプト情報においては「保険者番号(ID)以上に、研究目的に則した“エピソード“(患者単位、疾患単位など)が重要」となる。研究者の意図するエピソード単位でレセプト情報を集計し、二次元のテーブルとして提供するにはデータハンドリングの専門家の力が必要だが、そうした人材を用意できる研究機関は限られており、仮に協力を得られたとしても「分析者とデータハンドリング者の協議に少なくとも1週間程度、3%サンプリング500万人分(2億3000万件)のSQLデータ5.3GB分を取り出すのに18時間、さらにデータ分析(回帰分析)に2週間」(黒田氏)もの時間、つまり最低でも1カ月の期間が必要となる。
可用性に関しても問題は山積していた。NDBデータはオンプレミスのOracle Databaseに格納されていたが、オンサイトリサーチセンターに出向いた利用者は、手元のマシン(ローカル)に決められたデータをダウンロードして分析しなければならない。しかも現行データベースに格納されている6年分の全数データから利用者の目的に応じたデータを抽出し、巨大なテーブルを作成する必要がある。加えてセンターに設置されているローカルの端末はメモリーの上限が16GBと非常に非力で、すぐに実行不可に達してしまう。プロプライエタリなデータベースにありがちな問題として、データの増加にスケーラブルに対応しにくいという課題もあった。また、サーバー側で利用できる分析用のインタフェースはOracle Rのみで、重回帰分析ができない、散布図作成に時間がかかるなど機能不足が否めず、さらに複数人が同時利用すると大幅にパフォーマンスが低下する状況に悩まされていた。
NDB / 医療 / Hadoop / PostgreSQL / NTTデータ / Apache Spark / ヘルステック



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
