NTTは2024年1月17日、大規模言語モデル(LLM)「tsuzumi」の拡張技術として、少量データから“本人らしい会話”を生成する「個人性再現対話技術」と、数秒~数分の音声から本人の音声を合成する「Zero/Few-shot音声合成技術」を開発したと発表した。これらにより、利用者の“デジタル分身”を低コストで実現できるという。
NTTは、大規模言語モデル(LLM)「tsuzumi」の拡張技術として、少量データから“利用者本人らしい会話”を生成する「個人性再現対話技術」と、数秒~数分の音声から本人の音声を合成する「Zero/Few-shot音声合成技術」を開発した。これらにより、利用者の“デジタル分身”を低コストで実現できるという(関連記事:NTT、1GPUで推論動作可能な軽量LLM「tsuzumi」を発表、2024年3月に商用化)。
利用者個人の特徴を再現するには大量のデータ学習が必要だが、これを少量のデータで再現することで、だれでも簡単に、低コストでデジタル空間内に自身の分身を持てるようになることを目指す。NTTは今後、研究成果の実用化に向けて、自身に代わって対面のコミュニケーションやコミュニティ活動などを行うデジタル分身の公開実証などを進めていく。
2023年度中に、利用者のデジタル分身を通じた人間関係の創出効果に関してフィールド実験を開始する予定。tsuzumiによる個人性再現機能の実用化に向けて、2024年度中に技術の精度向上を図る。特定領域に関する専門的な言語能力を有しながら親しみやすい個性を表現し、他者との関係性を築けるデジタルヒューマン/チャットボットの実現につなげるとしている。
LLMにペルソナ対話機能を付加して“本人の個性”を反映
NTTが開発した個人性再現対話技術では、比較的少量のデータでLLMに追加学習を行うtsuzumiの「アダプタ技術」に「ペルソナ対話技術」を組み合わせている。LLMにペルソナ対話機能が備わることで、生成AI/LLMからの応答が、再現したい利用者本人の大まかな個人性を反映するようになる仕組みである(図1)。
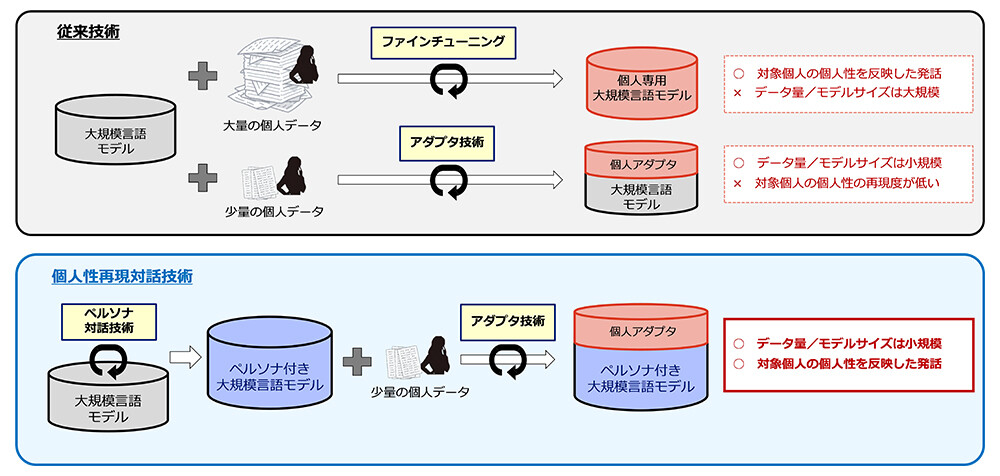 図1:従来技術と個人性再現対話技術の比較(出典:NTT)
図1:従来技術と個人性再現対話技術の比較(出典:NTT)拡大画像表示
ペルソナ対話技術では、LLMに対話データと共にプロフィールを学習させることでその機能を付加する。居住地や趣味など利用者本人のプロフィール情報をパラメータで指定することで、そのようなプロフィールを持ったペルソナ(人格)にふさわしい会話を再現する。
NTTによれば、学習初期状態でより本人に近づけて、少ないデータでも効率的に学習できるという。「アダプタの学習データに含まれるものとはまったく異なるような対話においても、ペルソナを反映した妥当な応答を返すことで、個人の再現性が高まる」(同社)。
アダプタ技術を個人性の再現に適用したのが「個人アダプタ」で、エピソードを交えた会話や口癖など、対象の個人に特化した話し方を生成できるという。個人アダプタで追加するモデルのサイズは非常に小さく、動的に切り替えることができるため、多人数の対話を効率的に再現可能だとしている。
「人格や個人性を再現するのに、個人に関する大量のデータでLLMをファインチューニングする手法があるが、実現するためのコストが高い。元になるLLMが多種多様な大量のデータで学習されているため、少量のデータでは十分に学習が進まず、個人の再現度が低下するという課題がある」。アダプタ技術とペルソナ対話技術はこの課題を解決し、低コストで精度の高い個人性を実現するという。
●Next:Zero/Few-shot音声合成技術の仕組み
会員登録(無料)が必要です


- 1
- 2
- 次へ >



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-
