NTTコミュニケーションズ(NTT Com)は2024年10月7日、オールフォトニクスネットワーク(全光ネットワーク)のIOWN APNで接続した2つのデータセンターでAIモデルを分散学習させる実験を実施し、単一拠点と同等の学習時間で済んだと発表した。データセンター間を高速・低遅延で接続することで、必要な台数のGPUサーバーを単一拠点内で調達できないケースでも、遠隔拠点のGPUサーバーを使ってGPUクラスタ全体の性能を高められるとしている。
NTTコミュニケーションズ(NTT Com)は、オールフォトニクスネットワーク(APN:全光ネットワーク)の「IOWN APN」で接続した2つのデータセンターでAIモデルを分散学習させる実験を実施した。単一拠点と同等の学習時間(1.006倍)で済んだという。データセンター間を高速・低遅延で接続することで、必要な台数のGPUサーバーを単一拠点内で調達できないケースでも、遠隔拠点のGPUサーバーを使ってGPUクラスタ全体の性能を高められるとしている。
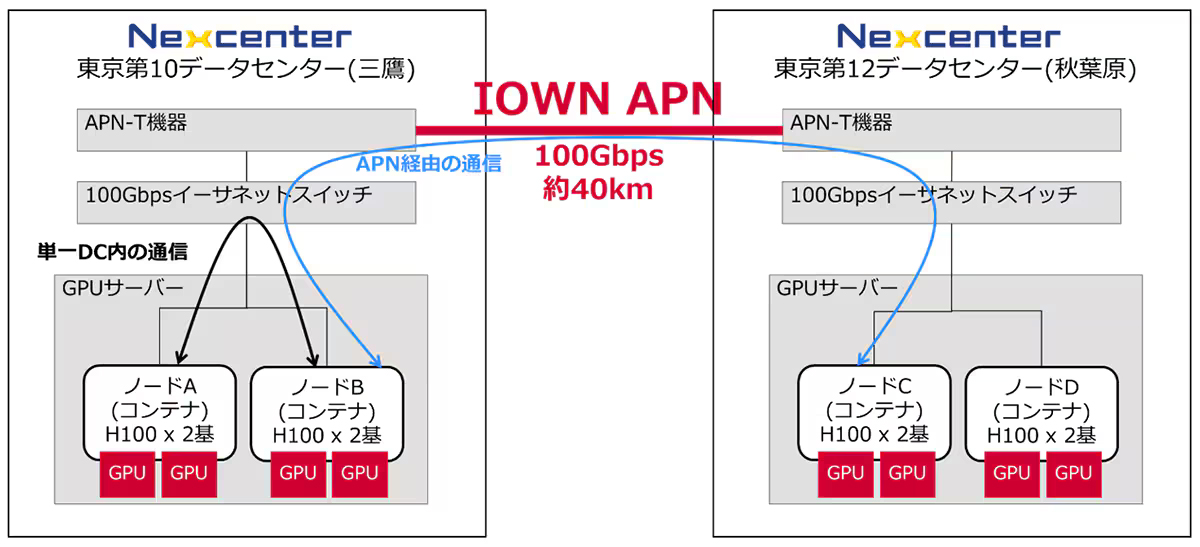 図1:光ネットワークで2つのデータセンターをつないだGPUクラスタ環境でAIモデルを分散学習させた実験の概要(出典:NTTコミュニケーションズ)
図1:光ネットワークで2つのデータセンターをつないだGPUクラスタ環境でAIモデルを分散学習させた実験の概要(出典:NTTコミュニケーションズ)拡大画像表示
実験環境として、NVIDIA GPU(H100)を2基搭載したサーバーを、約40km離れた三鷹と秋葉原のデータセンターに分散配置し、データセンター間を100Gbit/sのAPN(オールフォトニクスネットワーク)で接続した(図1)。こうして、GPUサーバー2台で構成する広域クラスタを組んだ。比較対象として、同一拠点内のGPUクラスタと、インターネットでデータセンター間を接続したGPUクラスタも用意した。
ユースケースの1つとして、AIモデル作成用フレームワーク(ソフトウェア部品群)であるNVIDIA NeMoを用いた分散学習により、大規模言語モデル(Llama 2 7B)の事前学習(Pre-training)を実施した(図2)。DDP(ディストリビューテッドデータパラレル)方式で、学習用データを分割して各GPUに学習させた。各GPUはAIモデルのコピーを持ち、割り当てられたデータを個々に学習する。
 図2:学習用データを分割して各GPUに学習させるユースケースで利用した、AIモデル作成用フレームワーク「NVIDIA NeMo」の概要(出典:NTTコミュニケーションズ)
図2:学習用データを分割して各GPUに学習させるユースケースで利用した、AIモデル作成用フレームワーク「NVIDIA NeMo」の概要(出典:NTTコミュニケーションズ)拡大画像表示
GPUが処理した内容をGPU間で同期するタイミングで、GPUクラスタを構成するサーバー間で通信が発生する。この、GPU処理内容を通信で同期する、というプロセスを繰り返すことで学習していく。GPUが1度に処理するデータ量(バッチサイズ)の設定によって通信の頻度を変えられるので、GPU処理と通信処理の比重を調整可能である。
実験の結果、単一のデータセンターで学習させる場合の所要時間と比較して、インターネット経由の分散データセンターでは29倍の時間がかかるが、APN経由の分散データセンターでは1.006倍と、単一のデータセンターとほぼ同等の性能を発揮できることを確認した(図3)。
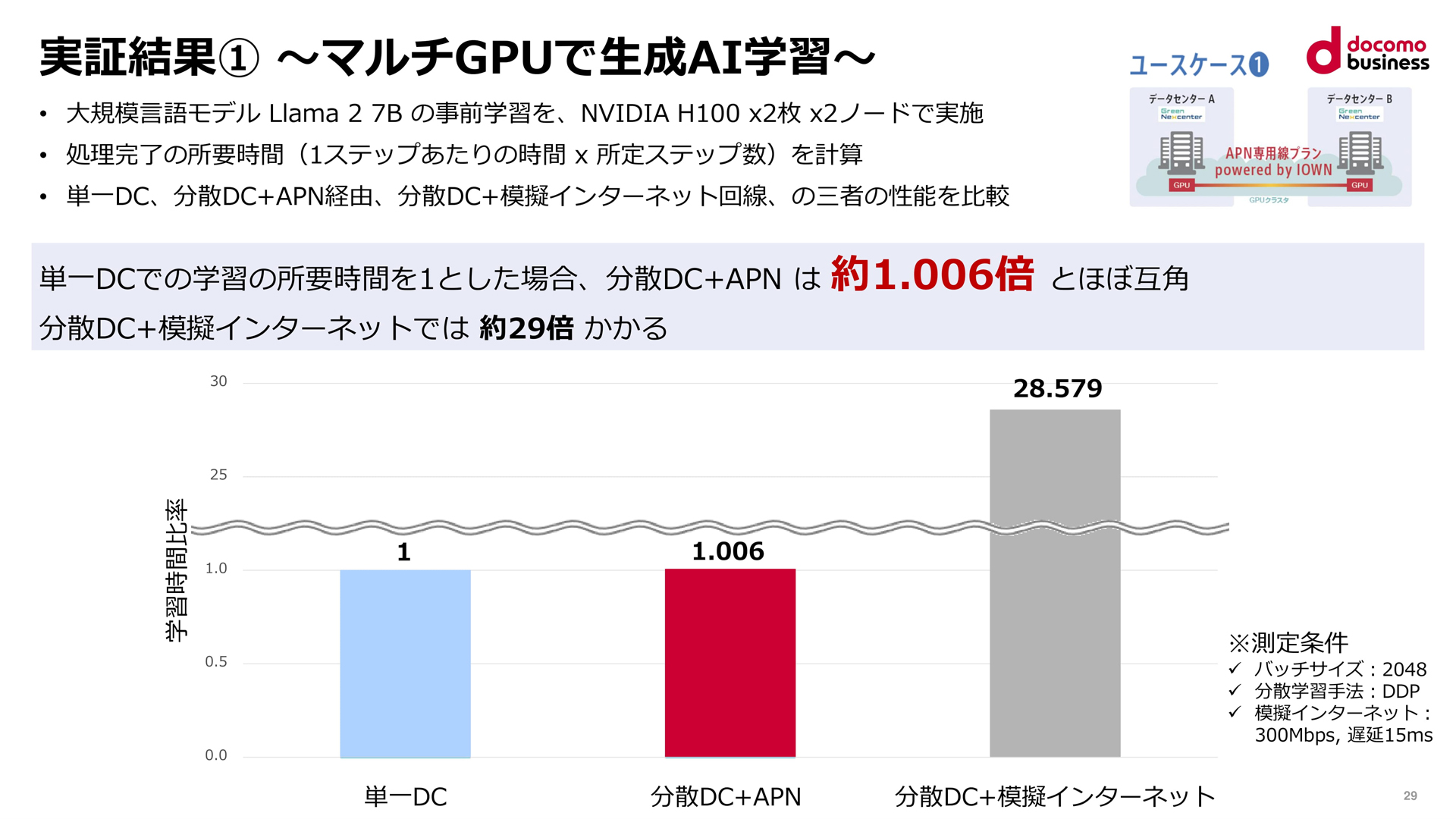 図3:GPUクラスタによる学習時間を3つの環境で比較した結果(出典:NTTコミュニケーションズ)
図3:GPUクラスタによる学習時間を3つの環境で比較した結果(出典:NTTコミュニケーションズ)拡大画像表示
 写真1:NTTコミュニケーションズ イノベーションセンターIOWN推進室担当部長の張暁晶氏
写真1:NTTコミュニケーションズ イノベーションセンターIOWN推進室担当部長の張暁晶氏拡大画像表示
実験の背景について同社イノベーションセンターIOWN推進室担当部長の張暁晶氏(写真1)は「サーバー1台が搭載するGPUは多くて8基。これを超えるリソースが必要な場合、複数台並べてGPUクラスタを構成する。従来は単一のデータセンター内でGPUクラスタを構築していたが、GPUリソースが必要になったタイミングでオンデマンドにサーバーを増やすことが難しかった」と説明した。遠隔拠点のGPUサーバーを使ってGPUクラスタを組む需要は大きいという。



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
