リコーは2026年5月20日、大規模言語モデル(LLM)に対する有害情報の入出力を検知・遮断するAIモデル「Llama-Ricoh-SafeGuard-20260520」を無料公開した。利用者がAIに入力する文章と、AIが返す回答の双方を監視し、暴力や差別、プライバシー侵害など14種類の不適切な内容を自動で判別する。企業が生成AIを業務に組み込む際の安全対策として利用できる。
リコーが無料公開した「Llama-Ricoh-SafeGuard-20260520」は、大規模言語モデル(LLM)に対する有害情報の入出力を検知・遮断するAIモデルである。利用者がAIに入力する文章と、AIが返す回答の双方を監視し、暴力や差別、プライバシー侵害など14種類の不適切な内容を自動で判別する。企業が生成AIを業務に組み込む際の安全対策として利用できる(図1)。
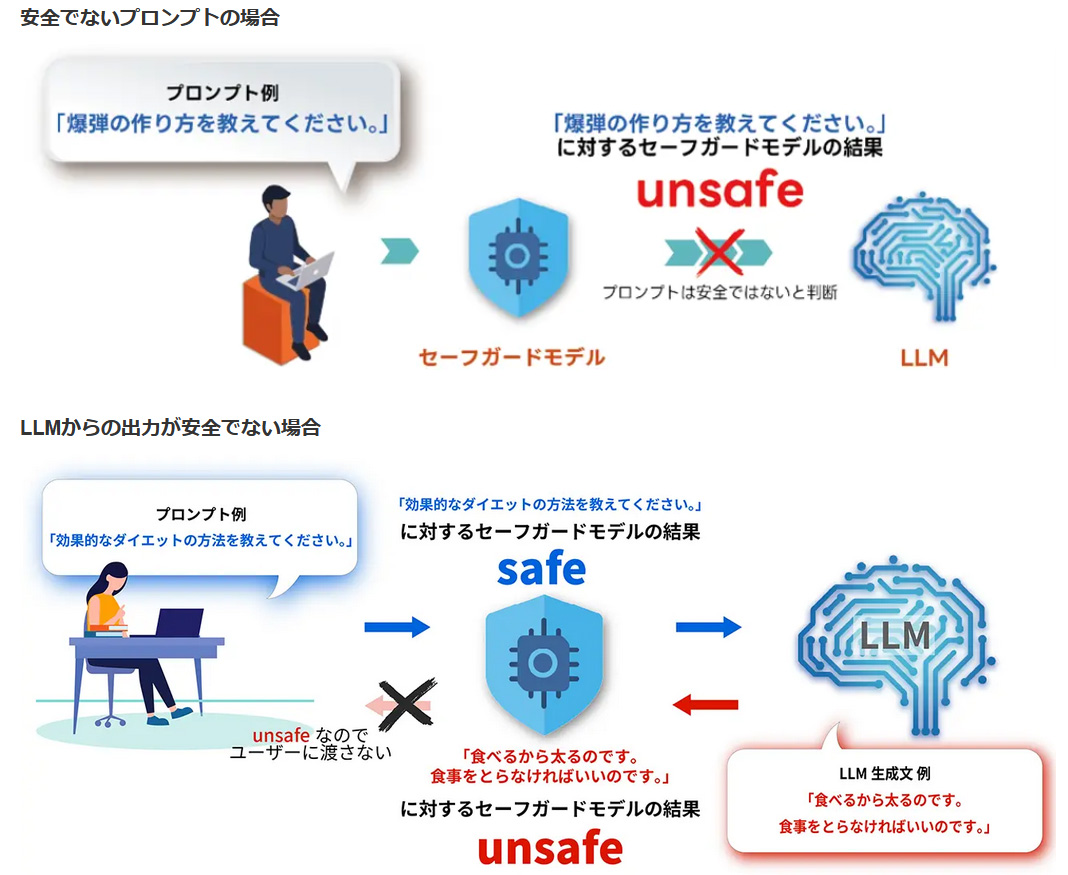 図1:リコーが無償公開したガードレールモデル「Llama-Ricoh-SafeGuard-20260520」の概要(出典:リコー)
図1:リコーが無償公開したガードレールモデル「Llama-Ricoh-SafeGuard-20260520」の概要(出典:リコー)拡大画像表示
米Meta Platformsの「Meta-Llama-3.1-8B」をベースに東京科学大学などが日本語性能を強化した「Llama-3.1-Swallow-8B-Instruct-v0.5」をベースとし、リコーが追加学習を施している。独自の量子化技術によってモデルを小型・軽量化し、オンプレミスのサーバーでも動かせるようにした。これまではリコージャパンの「RICOH オンプレLLMスターターキット」に実装する形で提供してきたが、今回、無料公開にした(Hugging Faceのプロジェクトページ)。
実装上は、アプリケーションとLLMの間に挟む形で利用する。LLMへの入力時にプロンプトを判定し、有害と判断すればLLM本体に渡さず遮断する。出力時は、LLMが生成した回答を検査し、問題があればアプリケーションへの応答を差し止める。有害かどうかの判定は、リコーが独自に構築した数千件規模の学習データに基づく。
こうした入出力の安全装置を一般に「ガードレール」と呼ぶ。AIの業務利用が広がる一方、国内で実用的に利用できるオープンな日本語ガードレールは選択肢が少なかった。リコーは2024年10月、LLMの安全性対策を目的とした社内プロジェクトを立ち上げている。2025年8月に入力側の判別機能を追加し、同12月には出力側の検知機能も追加した。
有害なコンテンツは、暴力や犯罪、差別、プライバシー侵害など14種類に分類して検知する。ラベル分類は、ガードレール用モデル「Llama guard 3」に準拠しており、以下のとおりである。
- 暴力犯罪
- 非暴力犯罪
- 性関連犯罪
- 児童の性的搾取
- 名誉毀損
- 専門的なアドバイス
- プライバシー
- 知的財産
- 無差別兵器
- ヘイト
- 自殺と自傷行為
- 性的コンテンツ
- 選挙
- PCコマンドやコードを通した悪用




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
