ディスクに書き込むデータ群から同一の部分を見つけてはじき出し、容量を節約する──。 これが「重複排除技術」のコンセプトである。 一連の処理はどのような方法で進められているのか。 基本的な仕組みと、最新の工夫について解説する。折川 忠弘(編集部)
業務で日々発生し保存するデータの中には、「重複」しているものが少なくない。単純な例では、議事録を記した文書ファイルをメールに添付して10人に送信すれば、それだけでメールサーバー上には同じものが10個存在することになる。プレゼン資料の一部に変更を加えて別名で保存する場合も、実質的には多くの部分がダブっている。データベースにおいて、一部のフィールドだけが異なるレコードが大量に存在するようなケースも珍しくない。
チリも積もれば山となる、との格言を持ち出すまでもなく、この重複がストレージ容量の浪費につながっている。そこで書き込もうとするデータの中から共通する部分を見つけ出し、実際に保存するのは1つだけという仕組みを徹底させるのが重複排除の基本的な考えだ。
重複排除技術は、特にバックアップ用途で注目を集めている。企業システムにとって、データ保全の観点でバックアップは欠かせない要件だ。とはいえ、すでに大量のデータを抱え、しかもますます増え続けている状況下では、バックアップ用のストレージ領域を可能な限り効率的に使いたいという要請が強いからだ。重複排除によってデータ量を減らせれば、遠隔のDR(ディザスタリカバリ)システムにも転送しやすくなるという期待もある。
キメ細かい判定は処理速度に影響を及ぼす
技術的に、どのように重複を判別しているのか。一般的にはデータを小さい単位のブロックに分割し、それぞれにフィンガープリント(FP)と呼ぶ識別情報を割り当てる。詳しくは、ハッシュ関数を使って当該ブロックを代表する値を算出したものをFPとする。FPが合致すれば、ブロックは同一のものと見なす。処理しようとするブロックが「既存」、つまり1度保存したものと合致すれば書き込まず、既存ブロックの参照情報(ポインタ)のみを記録することでムダをなくすのが基本的な仕組みとなる(図6-1)。
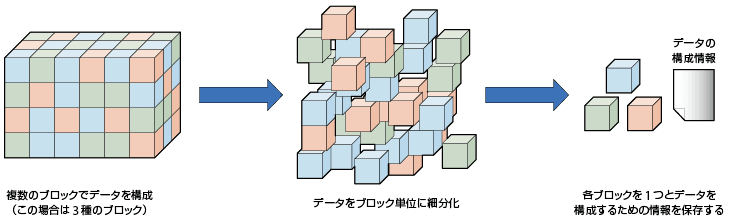
ブロックが小さいほどキメ細かい重複排除が可能となるが、大量のFPを用いた判定処理は速度低下をもたらしかねない。各ベンダーは、性能に影響が出ない範囲でブロック単位を極小化しており、目下のところは数KB〜数百KBという水準に落ち着いている。
一方でベンダー各社は重複判定を高速化するために様々な機能を盛り込み始めた。FPは通常、ブロック群とともにディスクに保存されるため、判定時にはディスクアクセスが伴う。このため、バックアップ時のデータ規模が大きいと負荷がかかり、スループットの低下を引き起こす。この解決策として、FPをメモリー上に配置し処理を高速化するといった工夫である。IBMの「IBM System Storage TS7650 ProtecTIER」はこのような機能を備えている。
なお、「数兆分の1」と言われる確率で、異なるブロックに同一のFPが割り当てられる可能性がある。こうしたケースに備え、重複と判断したブロックをさらに細分化してチェックを加える製品も出始めた。ネットアップの「FASシリーズ」が代表例である。
大きく2つに分かれる重複排除のタイミング
バックアップ用途を想定したストレージにおいて、重複排除はどのタイミングで実施されるのか。大きく2通りあり、使い分けが必要となる(図6-2)。
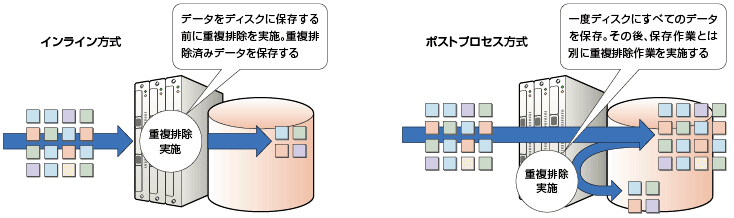
1つは「インライン方式」で、データを保存するタイミングで重複排除も同時並行で実行する。もう1つの「ポストプロセス方式」は、保存対象となる全データを一旦ディスクに格納し、その後に重複排除を実行するものだ。
インラインは最低限のディスク容量で済むメリットがあるが、同時処理ゆえ一般的には書き込み速度がある程度犠牲になってしまう。これとは逆にポストプロセスは重複排除を後回しにするので、書き込み処理の速度に影響を与えないものの比較的大きな容量を用意しておかなければならない。重複排除機能を搭載したストレージのほとんどは、どちらか一方の方式を採用している。実装容量抑制とスピードのどちらを優先するかの判断が必要だ。もっとも、富士通の「ETERNUS CS800 S2 デデュープアプライアンス」のように、用途に応じて両方式を選択的に利用できる製品も出始めている。
会員登録(無料)が必要です


- 1
- 2
- 次へ >




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
