見るべきポイントはレイテンシー!? クラウドのPoCを考える
2017年7月24日(月)石田 知也(アイレット cloudpack事業部ソリューションアーキテクト)
採用するAmazon EC2(以下、EC2)インスタンスが決定したら、実際の移行に入る前に事前検証、いわゆるPoC(Proof of Concept)の実践となる。PoCを行うことで、机上での比較や議論では見えてこなかったAWSクラウドの特徴を文字通り“体感”できるはずだ。
PoCの実践時に把握すべき事項
前回でも触れたが、EC2のインスタンスを選ぶ際、多くの人々はCPUやメモリー、そしてその価格に注目しがちで、ネットワーク帯域やストレージIOPSのチェックがおろそかになる。そのせいか、PoCの段階ではじめてレイテンシー(通信遅延)問題に気づかされるというケースが後を絶たない。クラウドの最大のメリットの一つは「手元にITリソースを置く必要がない」ということだが、これは「ITリソースが存在する場所にリーチするまでのレイテンシーは必ず発生する」ということも意味している。数ミリ秒の処理タイミングがビジネスの命運を分けるような場合、例えば金融取引などで使われるリアルタイムアプリケーションをクラウド上で稼働させる時は、レイテンシーは最小限に抑える必要がある。こうしたケースではやはりできるだけ近い場所にあるリージョンを選択すべきで、そのうえでさらにクラウドに適したパフォーマンスチューニングを実施したいところだ。
物理法則上、通信速度は光速を超えることはありえない。したがってネットワーク帯域がいくら拡大しても、どんなに強力なCPUと大容量のメモリーを選ぼうとも、レイテンシーは必ず発生するし、リージョンが遠ければ遠いほどその差は開く。もしマルチリージョンでのクラウド運用を検討しているのなら、各リージョンにおけるレスポンスの検証を必ず行い、ボトルネックの場所とレイテンシーを体感的に把握しておくことを強く推奨する。
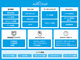
例えば、専用線で自社の内部ネットワークをAWSクラウドに直接接続できる「AWS Direct Connect」であれば、インターネットを介することなく閉域網でAWSのリソースを利用できるため、レイテンシーの数値が改善するだけでなく、体感的なレスポンスも大きく異なってくる。Direct Connectはセキュリティ面でのメリットが強調されやすいのだが、最近はパフォーマンスを重視する企業がDirect Connectを選ぶケースも少なくない。AWSはDirect Connectを体験できる専用ラボを国内にも用意しており、自社の環境を含めた動作検証も可能なので、こちらも利用してみるとよいだろう。
 AWS Direct Connectの構成要素
AWS Direct Connectの構成要素拡大画像表示
cloudpackでは『AWS Direct Connect』を活用してお客様のデータセンターやオフィスとAWSの東京リージョンを直結するメリットと主な検討事項から設計および構築・運用のノウハウを明記した『cloudpack専用線接続ホワイトペーパー(https://cloudpack.jp/pdf/cloudpack_DirectConnectWhitePaper.pdf)』を公開しているので参考にしてほしい。
また、EC2のデータはAmazon Elastic Block Storage(Amazon EBS)に保存される。EC2とEBSはネットワーク経由で読み込み/書き込みを行うため、I/Oの多いシステムの場合は、EC2とEBSの間でボトルネックが生じないかチェックしておこう。ボトルネックが生じる可能性がある場合は、EC2のインスタンスタイプの変更やEBS最適化機能を有効化できるインスタンスタイプを選択しよう。EBS最適化機能を有効化すると、EC2とEBS間のネットワークは専有化され、パフォーマンスが向上する。(参考サイト:http://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/EBSOptimized.html)
EBSのI/O性能自体にボトルネックが生じる場合は、ボリューム種別(マグネティック・汎用SSD・プロビジョンド IOPS SSD)の選択を見直そう。EBSに標準である『汎用SSD』を選択している場合は、確保しているディスク容量の増減に比例してI/O性能が決まってしまう。エラスティックボリューム機能を用いれば、システムを稼働させたままEBSの容量を増減させ、I/O性能を調整することも可能である。
「サーバーはいつでも破棄できる」というクラウドらしい概念
レイテンシーのチェックのほかに、PoCにおいて確認しておくべき作業として「障害時の切り戻し」「バックアップとリストア」などが挙げられる。
AWSクラウドは、オンプレミス環境と同じで、「サーバーやハードウェアはいつか必ず壊れる」という思想のもとで構築されており、“壊れないインフラ”ではなく“壊れてもすぐに蘇るレジリエントなインフラ”を目指している。したがって、クラウド環境で運用中のサーバーに障害が発生した場合、例えそれがどんな障害(一時的、断続的…)であっても、原因究明よりも復旧を優先すべきである。そしてその復旧手順は可能な限り自動化しておきたい。ひところ、IT業界では“Immutable Infrastructure(不変のインフラ)”という言葉を聞くことがあったが、この意味するところは「いったん環境を構築したら、それには手を入れず、変更が必要になった場合は新しい環境に入れ替える」という考えである。極論すれば、機能しなくなったサーバーにいつまでも執着せず、さっさと破棄して新しいサーバーに乗り換え、復旧に努める、という意味であり、非常にクラウドらしい概念だと言える。

オンプレミスの運用に慣れきっていると、最初はこの「サーバーはいつでも破棄できる」という考え方にとまどうかもしれない。しかし、この概念に沿った手順を決めておくことで、障害時に人手を介すことなく、自律的な復旧が実に容易に実現する。PoCの段階でクラウド特有の“レジリエンス”に馴染んでおけば、本番環境でもスムースな復旧が実現するはずだ。
もちろん障害の原因究明は大事なプロセスだが、それよりも重要なのはビジネスの継続である。何のためにクラウドに移行するのかをあらためて思い出していただきたい。壊れないインフラを手にするためでなく、運用にかかる手間を削減し、ビジネスに資するITを手にするためにクラウドを選んだのなら、障害時にまず先にやるべきことはおのずと決まってくるはずだ。
また、バックアップの作成とリストアの手順もオンプレミスとは異なった運用が求められるので注意が必要だ。とくにディザスタリカバリーなどの用途でマルチリージョンを利用する場合、スナップショットをどのくらいの頻度で作成し、どのタイミングで同期を取るのかは、データ転送量がコストに直結することを考えると、非常に重要な検証ポイントとなる。バックアップ作成の頻度とコストはトレードオフの関係となるので、ビジネスの事情を考慮しながら慎重に検証していきたい。
- AWS障害対策~予防から運用上の注意まで(2017/07/31)
- メモリーやCPUだけじゃない!? AWSインスタンスを選ぶ際に気をつけたいこと(2017/07/18)
- 移行前のアセスメント ~ 既存データセンターとAWSのセキュリティレベルを比較する(2017/07/10)
- 「AWSに移行する」が意味することの“本質”(2017/07/03)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
