AWS障害対策~予防から運用上の注意まで
2017年7月31日(月)石田 知也(アイレット cloudpack事業部ソリューションアーキテクト)
オンプレミスからAWSクラウドへ移行するまでのシミュレートは前回まででほぼひと通り完了した。最終回となる今回は、移行後のフェーズ、すなわちクラウドの運用フェーズにおける検討事項、とくに『障害対策で留意すべきポイント』を挙げておきたい。どんなシステムもそうだが、AWSクラウドはある意味、運用に入ってからが本当の勝負どころでもある。本連載でクラウドならではの運用ポイントを理解/把握し、読者の皆様がオンプレミスでは得られなかったメリットを存分に体感するきっかけになれば幸いである。
対象はリージョン単位の障害のみ - AWSのSLAとその例外
AWSでは以下の6つの主要サービスにおいて、個別にSLA(Service Level Agreement:サービスレベル合意)を定義している。
- Amazon EC2
- Amazon EBS
- Amazon RDS
- Amazon S3
- Amazon Cloud Front
- Amazon Route53

SLAで定義されているのは、サービスコミットの目標値と、AWSがそれを万が一守れなかった場合のサービスクレジット(返金)の割合だ。例えばEC2では、月間使用時間割合が99.0%以上~99.95%未満であれば10%のサービスクレジット、99.0%未満の場合は30%と定義されている。1カ月=30日で換算すると、1カ月で約21分以上サービスを使えなかった場合は月額利用料金の10%が、約7時間20分以上停止した場合は30%が返金されることになる。
ただしSLAには例外事由、すなわちサービスコミットメントが適用されないケースについても同時に定められている。以下、EC2の例外事由をそのまま引用する。
(i)AWS契約第6.1項に定めるサービス停止の結果である場合
(ii)不可抗力、Amazon EC2またはAmazon EBSの責任分界点の範囲外のインターネットアクセスまたは関連する問題を含む、アマゾンの合理的な支配の及ばない要因により生じたものである場合
(iii)回復ボリュームを認識することを怠った場合を含む、サービス利用者または第三者の作為もしくは不作為の結果である場合
(iv)サービス利用者の機器、ソフトウェアもしくはその他の技術、および/または第三者の機器、ソフトウェアもしくはその他の技術(アマゾンの直接支配の範囲にある第三者の機器を除く)により生じたものである場合
(v)地域(Region)使用不能に帰因するものでない、個別のインスタンスまたはボリュームの障害の結果生じたものである場合
(vi)AWS契約に従って規定されるメンテナンスの結果生じたものである場合
(vii)AWS契約に従ってAmazon EC2またはAmazon EBSを利用するサービス利用者の権利をアマゾンが停止もしくは終了させた結果である場合
ざっくり言うと「AWSに直接起因する、リージョン単位の障害」以外は返金対象とならないことになる。もちろん東京リージョンが丸一日落ちた(サービスを停止する)となればさすがに返金対象になるが、たとえば(v)にあるように、インスタンスやアベイラビリティゾーン(AZ)の障害が一部に留まる場合は使用不能時間に含まれない(例外事由に該当する)。AWS以外の回線事業者などが起こした障害、ユーザーがAWSとは別に用意したハードウェア/ソフトウェアに起因する障害に関しても同様であり、返金の対象とはならない。
また、AWSに起因する障害であっても自動的に返金されるわけではないことに注意が必要だ。サービス停止がAWSに起因する場合、ユーザーはその証拠をエラーログとして提出しなくてはならない。したがってAWSクラウドの運用にあたっては「障害がどういう事由に起因するのか」を常に把握/監視できるモニタリング環境を用意すること、さらには、高いSLAが必要なシステムの構築時は、AZをまたいだ冗長構成を採ることが必須となる。これを実現するには、AWSが提供するクラウドモニタリングサービス「AWS CloudWatch」を利用したり、オープンソースのZabbixなどを使って監視システムを構築する方法がある。クラウドインテグレーションを得意とするパートナー企業であれば、独自の監視サービスを提供している場合もあるだろう。いずれにせよ、AWSクラウドを運用していく際、インスタンスの監視は、ユーザー側の必要な運用管理項目となる。
ハードウェアは故障するもの - 障害を“折り込み済み”にする理由
こうしてみるとAWSのSLAは、既存のデータセンター事業者やホスティング事業者などと比較して厳しく見えるかもしれない。SLAが定義されているサービスが6つだけというのも「少なすぎる」と感じる人もいるだろう。だが、ここであらためて覚えておいてほしいのは、AWSクラウドにおけるSLAの“A”はユーザーとAWSの間で結ばれるAgreement(合意)であるという点だ。決してAWSがユーザーに対して行うAssurance(保証)ではない。
前回でも言及したが、AWSクラウドは、基本的に「サーバーなどのハードウェアはいつか必ず壊れる」ことを前提にアーキテクチャが設計されている。インスタンスやアベイラビリティゾーン、データセンターに至っても同様だ。そういうものだと認識した上で、ユーザー側にも冗長構成や死活監視を求めているのである。これはオンプレミスしか運用したことがないインフラ担当者にはなかなか受け入れがたい概念かもしれない。
もちろんAWSも障害が起きないための最大限の努力を続けている。だが、AWSのビジネス規模や膨大なITリソースを考えれば、世界中の全リージョンが24時間365日に渡って1分1秒たりとも障害が起きることがないとする方が非現実的であろう。「サーバーは故障するもの、クラウドも障害が起きるもの」であり、だからこそ前回も触れた通り「障害が起きてもすぐに復旧できる」レジリエンスこそがAWSをAWSたらしめているのである。障害が発生したとしても、AWSだけでなくユーザー側も可用性を高めるための努力を継続していれば復旧までの時間を限りなく短縮できる。高いサービスレベルをAWSに求めるなら、ユーザー側もまた、それに見合った運用体制、つまり障害が発生することを折り込んだ運用体制を採ることを課せられていると考えるべきである。
cloudpackでは、マネージドサービスにおけるSLAとSLO(Service Level Objective:サービスレベル目標)を明確化した『cloudpackサポートデスクホワイトペーパー(https://cloudpack.jp/pdf/cloudpack_SupportDeskWhitePaper.pdf)』を公開し、運用体制の全体像とプロセスを開示している。
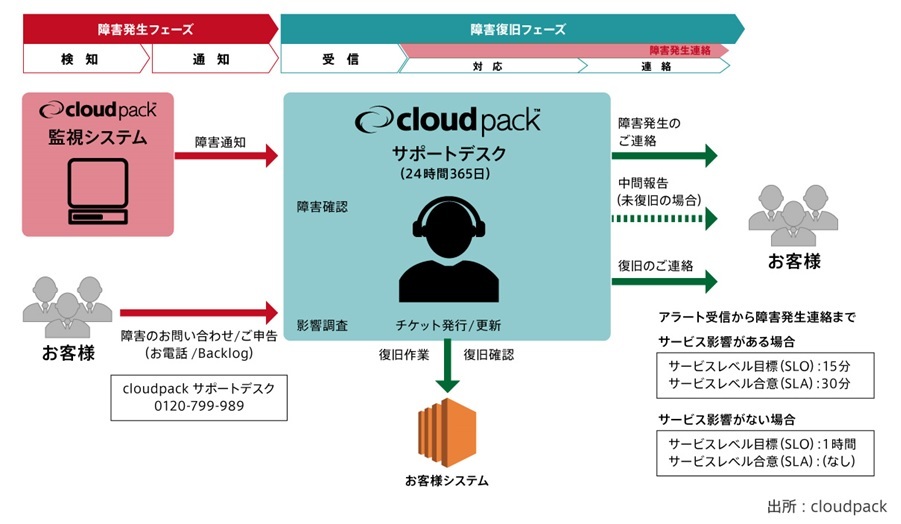 cloudpackサポートデスクの利用方法:障害発生時 ~ お客様のシステムで障害が発生した際のフローを公開しスムーズな復旧作業を行うことのできる体制を整えている
cloudpackサポートデスクの利用方法:障害発生時 ~ お客様のシステムで障害が発生した際のフローを公開しスムーズな復旧作業を行うことのできる体制を整えている拡大画像表示
冗長化をAZだけでなくリージョンをまたいで展開すれば、可用性はさらに高まり、サービスが利用できない時間をゼロに近づけることはできる。ただし、オンプレミスで構築するほど高額ではないにせよ、当然ながら追加のコストがかかる。それよりも要件ごとにどこまでの可用性を担保すべきかを定め、あとは運用でカバーすることに徹した方がクラウドらしいアプローチだといえよう。オンプレミスを含め、100%ダウンしないITインフラなどはこの世に存在しない。だがAWSクラウドが登場するまで、それをはっきりと謳ったデータセンター事業者は存在しなかった。この割り切った思想を理解することが、AWSクラウドの運用において非常に重要であることを覚えておこう。
クラウド時代の“運用”のあり方
最後に、AWSクラウドの障害対策で覚えておきたいもう一つのポイントを紹介しておく。クラウドの運用に慣れてくると、障害が起こる“前兆”を感じ取ることができるようになる。運用しているインフラに紐付く、固有の“ブレ”があらわれてくるのだ。それはレイテンシーにあらわれたり、リソースの状況にあらわれたりする。この予兆を捉えたら、まずは本番環境から当該インスタンスを切り離し、原因を探るフェーズに入ることを推奨する。クラウドのメリットの一つはリソースの切り離しが非常に容易に可能なことである。本番環境を止めることなく、障害のチェックが可能な点は大いに利用したい。こうした予兆を捉える経験を重ねることで、障害発生率そのものを低く抑えることが可能になる。
また、一見、関係ないようだがビジネス部門とIT部門が密に連携する体制を採ることも重要な障害対策の一つである。連載の初回で触れたが、なぜクラウドを導入するのか、その原点をあらためて振り返ってみてほしい。「ビジネスに資するITインフラ」の構築こそがクラウド導入の最大の理由であり、そのためのITリソースを効率よく提供することがIT部門の仕事である。落ちないインフラを構築することではない。ビジネス部門との連携を図らなければ、障害時の復旧対策や計画停止などもスムーズにはいかないのだ。AWSクラウドの運用方針は、ビジネス部門の意見も必ず取り入れるべきである。
AWSクラウドが世に出て10年以上が過ぎた。クラウドの普及はITの世界を変え、ビジネスの世界を変え、数多くのイノベーションを生み出した。それに伴い、運用の世界にもアジャイルやDevOps、自動化、責任共有モデルといった新たなトレンドが生まれ、オンプレミス時代のアプローチとは大きく異なりはじめている。運用担当者が人力でハードウェア/ソフトウェアを管理するあり方から、別の場所にあるリソースを付かず離れず見守っていくスタイルへ──。クラウド時代の運用の軸足はそうした方向にシフトしていると言えるだろう。(了)
- 見るべきポイントはレイテンシー!? クラウドのPoCを考える(2017/07/24)
- メモリーやCPUだけじゃない!? AWSインスタンスを選ぶ際に気をつけたいこと(2017/07/18)
- 移行前のアセスメント ~ 既存データセンターとAWSのセキュリティレベルを比較する(2017/07/10)
- 「AWSに移行する」が意味することの“本質”(2017/07/03)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
