企業競争力を高め、ビジネスイノベーションに必要不可欠となっているのが、デジタル技術の活用だ。発注や物流、在庫、生産などの管理の効率化に向け、多くの企業においてIoTやAIを活用する動きが進みつつあり、モノやヒトの調達を最適化するための需要予測についても、ビッグデータやAIを活用による高度化・自動化を推進し、販売機会・廃棄ロス削減や人手不足を解消する機運が高まっている。富士通は3月7日に行われた「データマネジメント2018 ~データが拓く無限の可能性~」のセッションで、AI/機械学習を活用した需要予測高度化のための手法について解説した。
需要予測には、万能的に使用できる
唯一のモデルは存在せず
ソーシャルネットワークやクラウド、ビッグデータ、IoT等によってヒトやモノに関連する様々な情報が繋がり、日々、膨大なデータが生み出されている。また、そうしたデータを有効活用し、価値創出の源泉とするため、AIや機械学習といった新しいデジタルテクノロジーを取り入れる企業も増えている。そうした新しいテクノロジーを用いたデータ活用の一例として、多くの企業によって取り組まれているのが需要予測の領域だ。
「データマネジメント2018」に登壇した富士通 デジタルソリューション事業本部 デジタルアプリケーション事業部 エンタープライズアプリケーション部 マネージャーの佐藤祐介氏は、「AI/機械学習を活用した需要予測の高度化アプローチ」について解説した。
昨今、商品の多品種化・少量生産化をはじめ、ライフサイクルの短期化、さらには顧客のサービス要求の高度化など、市場が激変する中では需要予測がより困難なものとなりつつある。また、現場の運用負担も増加しており、多くの企業においては、データを起点とした需要予測により業務を効率化し、ひいてはイノベーションを創出していくことが喫緊の課題となっている。だが、精度が高く、安定し、効率的な運用ができる需要予測を行っていくのは至難の業だ。
佐藤氏は、「需要予測のポイントは、最適な予測モデルを適応すること、予測に効果的な学習データを見つけ出すこと」と訴える。
佐藤氏によれば、需要予測モデルには万能的に使用できるただ1つのモデルは存在せず、商品の特性に応じて最適なモデルを使い分けることが必要となるという。一般的には、複数の予測手法から最適な手法を評価指標から判断・選択する「モデル選定型」のアプローチがあるが、時間経過による商品特性の変動に合わせてチューニングが必要となる。
「対して、複数の予測手法を組み合わせることで合成値を生成し、予測数を算出する『モデル統合型』のアプローチがある。1つのモデルを選択するよりも、いろんなモデルを統合して、需要予測をより高精度なものとする手法である」(佐藤氏)。
より高精度な需要予測を可能とする
「動的アンサンブル予測」
そうしたモデル統合型による、高精度な需要予測を実現するために、富士通が推進しているアプローチが「動的アンサンブル予測」だ。
これは、特徴の異なる複数のモデルを用いて予測を行い、機械学習により各モデルの合成比率をダイナミックかつデータオリエンティッドに自動最適化するという手法である。具体的には、多種多様な複数の需要予測モデルを利用して機械学習させた後、さらに商品特性に合わせて最適な予測モデルを合成していく2段階の機械学習で予測の精度を高めるというもの。「複数の予測モデルの予測結果に基づき、それらのモデル合成比率を調整し、より安定的な精度を有した需要予測結果を出すことを可能としている。予測単位毎に、予測する度に動的に合成比率を変化させるため、高い精度を維持することができる」と佐藤氏は説明する。
実際、富士通が行った検証から、他の単一予測モデルの結果と比較して、予測誤差率が低く、高精度な予測が行えたという結果が提示された。また、このアプローチでは、多様な商品の動的な特性に応じた自動チューニングにより、運用効率化も図れるという。
セッションでは、この富士通の需要予測モデルを活用した、製造業における生産計画変更の負荷を軽減した事例や、流通・卸業における発注業務の省力化事例、流通・小売業の店舗発注業務効率化・在庫最適化事例なども紹介された。
現場業務部門も交え有効性のあるデータを共創型で見つけ出し
より高精度な需要予測を実現する
佐藤氏は、AI/機械学習を活用した需要予測の高度化について留意すべきポインについても言及した。
「当然のことながら、学習データが多いほど、需要予測の精度は向上する。したがって、保有しているデータの期間が長いほど精度がよくなる傾向があるが、現在とビジネス環境が異なるデータ、例えば10年前のデータの有効性には適用判断をする必要がある。予測する対象について有効なラインを決めていくことが重要となる」(佐藤氏)。
また、長期間のデータを学習させるには、インフラにも処理能力が求められるため、コストメリットを考えなければならない。また、業種業務向けに用途に特化した予測モデルも市場にはあるが、より高精度な重要予測を行うには、自社の要件やデータ特性に基づいたフィッティングを行っていく必要があるという。
加えて、自社に特有の事象を有したデータも存在しており、情報システム部門だけでなく現場の業務部門も交えながら、予測に有効性のあるデータを共創型で見つけ出し、機械学習させていくことが重要だ。
「そして、単に予測精度が向上した、低下したと一喜一憂するのではなく、在庫がどのくらい減ったのか、生産効率がどのくらい上がったのか、業務KPIを設定することが導入にあたっての留意すべきポイントとなる」(佐藤氏)。
富士通では、「Operational Data Management & Analytics」(ODMA)という、ビッグデータとAIを組み合わせたソリューションを展開しており(図1)、需要予測サービスについても動的アンサンブル予測エンジンを搭載したSaaS型のデータ提供サービスとして提案していくという。
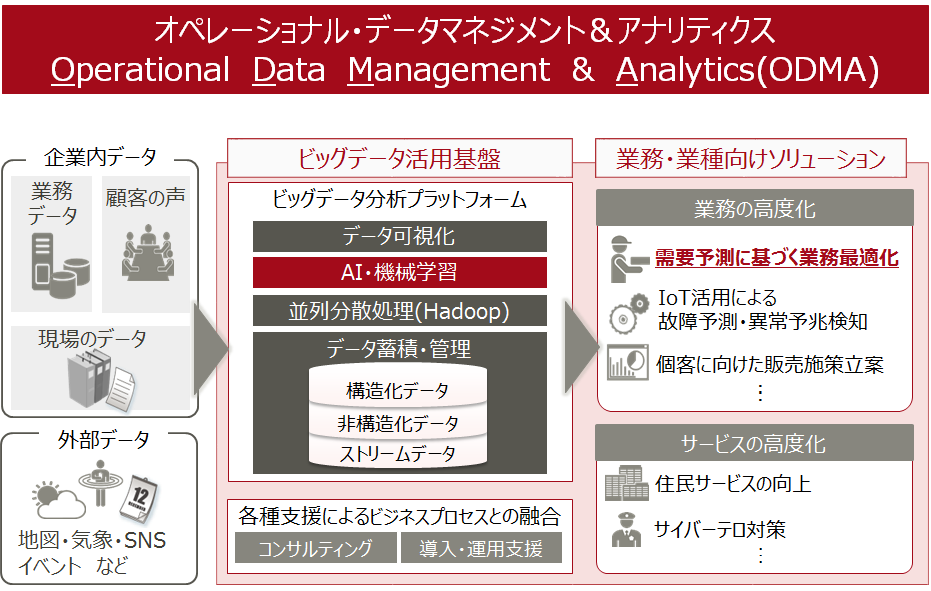 図1:ビッグデータ×AI利活用ソリューション「Operational Data Management & Analytics」
図1:ビッグデータ×AI利活用ソリューション「Operational Data Management & Analytics」拡大画像表示
佐藤氏は、「このサービスを、企業が運営している基幹系システムや情報系システムとシームレスに連携させ、イノベーションを加速させていけるような支援を行っていきたい」と訴え、セッションを締め括った。

●お問い合わせ先
富士通株式会社
お問い合わせは下記URLの製品情報HPに記載の問い合わせフォームよりお願いいたします。
【製品情報】
FUJITSU Business Application Operational Data Management & Analytics
URL:http://www.fujitsu.com /jp/solutions/business-technology/intelligent-data-services/ba/product/operational-data-management-and-analytics/
- デジタルビジネス時代におけるデータマネジメントのあるべき姿(2018/04/25)
- クラウドファーストの実現・実践に向けてデータ基盤はこう構築せよ(2018/04/19)
- デジタル変革の実現に必須となるデータプラットフォームとプロセスの姿(2018/04/11)
- 再び脚光を集める「データHUB」──基盤構築のポイントは仮想データ統合にあり(2018/04/10)
- 基軸となるデータを見ずに何を見る? AIを始めとした過剰なツール信仰が招いたデータ活用の失敗例(2018/04/10)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
