ビッグデータを用いたアナリティクスや機械学習への取り組みが進むとともに、大量のデータを検索して管理可能とする「データカタログ」を構築する企業が増えている。だが、多大なコストと時間をかけて作り上げたにもかかわらず「データカタログがユーザーに使われていない」という声も多々、聞こえてくるようになった。データカタログの構築がうまくいかない原因はどこにあるのか。「データマネジメント2020」のセッションでは、リアライズの田畑氏が登壇、データカタログの構築で陥りやすいアンチパターンと、それを回避するためのプロジェクト推進の方策が解説された。
効果的なメタデータの作成、運用こそが、データカタログ構築成功のカギ
2010年頃に「データレイク」という概念が登場し、企業は膨大な量の多種多様なデータを格納することが可能になった。だが、無目的にデータを集め続けていった結果、どんなデータが格納されているのか把握できなくなり、データレイクは“湖”どころか、データスワンプ、つまり“濁った沼”になってしまっているケースも少なくない。「そうしたデータレイクの惨状を救うために誕生したのが、データカタログであると推察される」と、リアライズ データマネジメント事業部 シニアスペシャリストの田畑賢一氏は説明する。
 株式会社リアライズ データマネジメント事業部 シニアスペシャリスト 田畑賢一氏
株式会社リアライズ データマネジメント事業部 シニアスペシャリスト 田畑賢一氏データカタログは、組織が大量のデータを検索して管理できるように設計されたメタデータマネジメントの仕組みだ。「メタデータ」はデータ自体の利用や調査、管理、統合等に必要となるデータであり、「メタデータ管理」とは、メタデータをデータの利用目的に応じて収集、管理、公開、維持する取り組みをいう。
一般にデータカタログは、先に述べた機能を提供する“ツール”として定義されることが多い。だが、田畑氏は、「ツールと定義してしまうと、“カタログ”という言葉から想起されるイメージとは異なったもののように思えてしまう。また、SIベンダーも単にツールとして提案しており、肝心なメタデータ自体の話をしていないようにも感じられる」と疑問を投げかける。
データカタログは、機能としてのデータカタログと、そこに格納されるメタデータの両方が揃って初めて成り立つものだ。だが、ツールとしてデータカタログを導入しても、合わせてメタデータは導入されない。データカタログツールの中にはメタデータを自動的に収集してくれるものもあるが、それは既に社内に存在しているものに限られる。つまり、現存しないメタデータは収集できないのだ。「そうしたことから、データカタログ構築の成功のカギは、メタデータをいかに効果的に作成、運用するかにある」と、田畑氏は強調する。
データカタログ構築に失敗をもたらす4つのアンチパターン
田畑氏は、これまでリアライズが参画したプロジェクトを通じて得られた経験に基づき、データカタログ構築がうまくいかない主な理由を4つの「アンチパターン」に分類して紹介した。
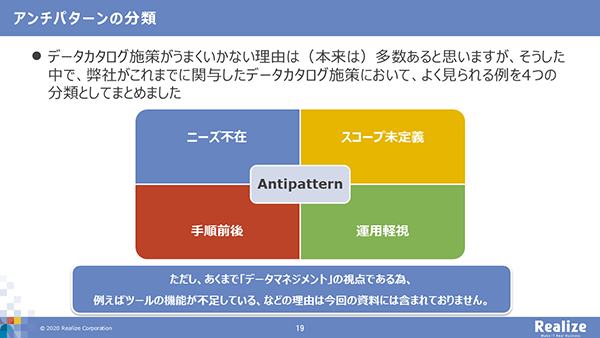 データカタログ施策がうまくいかない4つのアンチパターン
データカタログ施策がうまくいかない4つのアンチパターン① ニーズ不在
データカタログの構築に際して、ユーザーがどういうニーズを持ち、どういう事を実現したいのかを把握せずにプロジェクトをスタートさせることは失敗の始まりとなる。特定のユーザーの具体的な課題を解決する、という明確な目標が定義されなければならない。
② スコープの未定義
データカタログ構築では、収集されるメタデータがその成否を分ける。事前にニーズを把握してスコープを定めておくことなく、すべてのメタデータを集めようとしたならば、失敗してしまうケースが多い。
例えば、メタデータの分量が多すぎればデータカタログが利用できるようになるまでに多大な時間を要し、その有効性が発揮できなくなる。また、不要なデータを収集しても、その分類整理は困難なものとなり、データカタログの複雑化を招く。結果、ユーザーにとって使い勝手の悪いシステムとなってしまうだけでなく、運用コストの負担も大きくなる。さらに対象となるメタデータに明確なニーズが設定されなければ、得られるメリットも提示できず、ステークホルダーからの協力を得ることも困難となる。
③ 手順前後
先にデータカタログツールを導入し、後でその利用方を検討するというやり方も、よくある失敗のパターンだ。「とりあえずツールを導入すれば、問題が片付くだろう」と考える企業は多く、明確な目的と得られる効果が確認されていない段階でツール導入を行うべきではない。
④ 運用の軽視
メタデータは陳腐化してしまうものであり、データカタログも最新化され続けるメタデータの登録簿でなければならない。構築・本番稼働はあくまでも助走に過ぎず、メタデータの内容に関する追加・改訂・削除といった運用プロセスこそが、データカタログの価値向上をもたらす。そのためにも、メタデータの継続的な整理、アップデートが不可欠となる。
アンチパターンを回避するためのプロジェクト推進の在り方とは?
これらのアンチパターンは相互に関連を持っているため、個別のパターンのみを回避する方法はない。そこで、田畑氏はデータカタログの構築フローに沿いながら、どのタイミングで何に気をつけるべきかについて解説した。
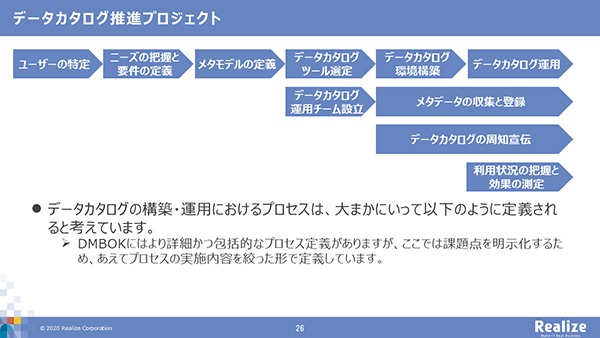 データカタログ構築フロー
データカタログ構築フロー- ユーザーの特定:一番初めにデータカタログの要件を把握するため、ユーザーを特定することから開始する
- ニーズの把握と要件の定義:ユーザーが見つかったならば、ニーズを把握し、要件に落とし込む
- メタモデルの定義:メタデータの関係性を示すデータモデルである「メタモデル」を定義する
- データカタログツールの選定、環境構築、運用:定義したメタモデルが適用であるのか、その他の機能・非機能要件に準じてデータカタログツール選定した後、構築、運用を開始する
また、4と並行して実施すべき事項として田畑氏は「データカタログチームの設立」「メタデータの収集と登録」、そして「データカタログの周知宣伝」を挙げる。
データカタログの運用で最も重要なのは、社内においてメタデータを保有しているのはIT部門ではなく、実際にデータを生み出しているビジネスユーザーであり、そこからデータを収集可能な体制を整備していかなければならないことだ。また、データカタログを利用してもらうための宣伝周知を徹底することも必要となる。導入効果や成功事例等を通じてユーザーにその価値を理解してもらえなければ、データカタログを構築しても使ってももらえないと田畑氏は訴える。
「データカタログは社内のユーザーに使ってもらう製品という側面が非常に強く、ユーザーに対してどのようなサービスを提供することがそのメリットになるのか、綿密に検討するプロセスが不可欠となる。それこそが、データカタログ構築の成否を決定する分水嶺となるのだ」(田畑氏)。
最後に田畑氏は、「データドリブンを実現するためには、前提としてデータカタログか、同等の情報が整備されていることが必須条件となる。本セッションがデータカタログ構築の失敗回避の一助になれば幸甚である」と述べ、講演を締めくくった。
●お問い合わせ先

株式会社リアライズ
URL:https://www.realize-corp.jp/
TEL:03-6734-9888
E-mail:sales@realize-corp.jp
- サイロ化された業務体系が阻害要因に~DX時代の競争優位を導くMDMの成功要因とは?(2021/01/25)
- データの価値を最大化する戦略アプローチと、データドリブン文化の醸成に向けて(2020/05/27)
- 社内データの意味を見える化し全方位から把握! ビッグデータ活用は“メタデータマネジメント”が鍵に(2020/04/21)
- アジャイルなデータ統合・活用を実現するデータ仮想化技術の最前線(2020/04/17)
- 真のデータ駆動型の組織を実現する持続可能なデータ統合のフレームワークとは(2020/04/15)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
