データ駆動(データドリブン)型組織の構築は、あらゆる企業にとって喫緊の課題となっている。ただ、企業内に散在しているデータを単に一カ所に収集する仕組みを用意するだけでは、本当の意味でのデータ駆動型企業や組織は実現できない。「データマネジメント2020」のセッションで、Talendのシニアソリューションエンジニア、菅野貴志氏が、組織内の誰もがデータを簡単かつ迅速に活用できるようにするための継続可能なデータパイプラインのフレームワークについて解説した。
あるべきデータパイプラインを実現する4つの段階
 Talend株式会社 シニアソリューションエンジニア 菅野貴志氏
Talend株式会社 シニアソリューションエンジニア 菅野貴志氏データ活用の課題の多くは、システム間の連携の複雑さに起因する。連携が必要なシステムの組み合わせの数と、その間を流れるデータの量は増加する一方だ。では、この課題をどうやって解決できるか。Talendのシニアソリューションエンジニアである菅野貴志氏は、「データが流れ、パイプラインの基盤となる専用のプラットフォームが必要です」と説いた。
ここでいうパイプラインとは、石油の精製プロセスにおけるパイプラインをイメージすると理解しやすい。原油が採掘されるとさまざまな工程を経て、重油、軽油、ガソリン、ベンゼン、ナウサ、LPガスといったニーズの異なる製品に分化していく。同じようにデータも収集した元データを成型し、変換し、組み合わせていくことで、ビジネスニーズに適した形態に変わっていく。
 データパイプライン基盤
データパイプライン基盤Talendでは、このデータパイプラインが持つべき性質を、次の4つの段階に分割して捉えているという。
第1段階はデータを収集し、そこに必要な成型と変換をほどこすプロセスだ。この段階では、収集できるデータの種類が豊富であること。そしてデータを成型し、変換するための仕組みがたくさん用意されていることが決定的に重要となる。
第2段階では、データに対してガバナンスを効かせる。とりわけ重要なのは、プライバシーを保護する仕組みを提供すること。加えてメタデータを管理することだ。「データを識別するためには、まずそれを見つけないことには話が始まりません。したがってデータが存在する場所というメタデータが必要です。さらに見つかったデータに関して、その形式やオーナー、更新日時、プライバシー保護レベルといった情報を得られることが、データの内容自体と同じくらい重要です」(菅野氏)。
3段階目は、データをより付加価値の高いものとする。たとえば複数のデータを結合して新しいデータセットを作ることがこれにあたる。さらに高度な例として、データに対して機械学習による分析を施すことも一般化してきた。
そして第4段階は、データの受け渡しである。次にデータを必要とするシステムや人に向けてそれを出力するのが一般的だが、そのほかAPI経由でアクセスさせるといったケースも考えられる。「APIによるシステム連携は年々その重要性を増しており、TalendはAPIを設計・実装・テスト・運用するための一連の製品を提供しています」(菅野氏)。
持続可能な基盤であるための3つの切り口
データパイプラインを統一的に扱うための考え方として、これまでEAI、SOA、ESB、ETLといったさまざまな概念が提唱されてきた。現在、これらの言葉を耳にする機会は少なくなり、単にデータ統合と呼ばれることが多くなった。
Talendもまたそうした変化を通じて、ソリューションの守備範囲を拡大してきた。菅野氏は、「我々の製品はハブ型でもバス型でもアーキテクチャーを問わずに対応することが可能です。さらに、Webサービスでもマイクロサービスでも対応できるデータ統合基盤です。さらに、データパイプラインを考える上で重視していただきたいのは、それが持続可能な基盤であるかという点です」と強調する。
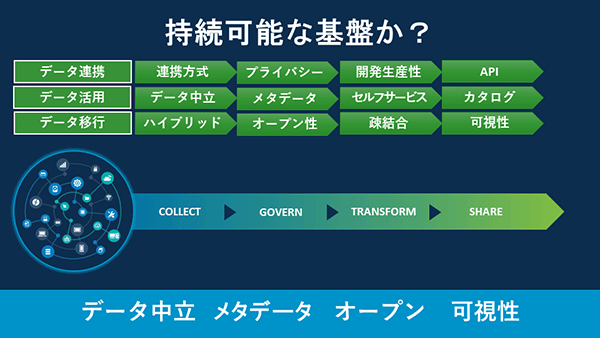 データパイプラインを考える上で重要なのは「持続可能な基盤であるか」
データパイプラインを考える上で重要なのは「持続可能な基盤であるか」 持続可能な基盤には次の3つの切り口がある。
まずは「データ連携」だ。連携可能なリソースの種類だけでなく連携方式も重要である。たとえばデータをリアルタイムで処理するのか、バッチで処理するのか。さらに同じリアルタイムで処理する場合でも、オンラインでトランザクションを処理するのか、ストリーミングデータを処理するのかによっても連携方式は異なる。「Talendはいずれの連携方式にも対応するとともに、開発生産性に関してはデータ処理の8~9割を占める基本パターンについて、コードを書くことなく、あるいは少ないコードで実装できます。これは非常に大きなメリットとなります」(菅野氏)。
2つめは「データ活用」だ。たとえばデータベース製品によって処理の容易性や扱うデータの種類が異なることから、統一的な連携処理を行うことは難しい。「Talendはあらゆるデータを扱う基盤を目指しており、いかなるストレージ製品も持っていません。データに対して中立であることは我々の生命線なのです。また、ユーザーのニーズに応えるために、対応システムとそのバージョンは常に最新となる製品を開発しています」(菅野氏)。
3つめは「データ移行」だ。オンプレミスとクラウドが混在したハイブリッド環境、ベンダーロックインを防止するオープン性、連携するシステム同士が互いに影響を受けない疎結合、データ連携処理のGUIによる記述やデータカタログによる可視性などをTalendでは重視している。
「これら3つの切り口のどこかに問題がある場合、最初は順調でも将来的にデータ品質が低下してしまう恐れがあります」と菅野氏は指摘した。
データ処理の中核部分を短時間で直感的に実装
上記のような観点に基づいたデータパイプラインのプラットフォームであるTalendの特長をあらためて見てみよう。
まず現実的な側面として、世の多くのデータ連携基盤のアーキテクチャーは、非常に複雑なコンセプトモデルやソフトウェアスタックから構成されている。一方でTalend製品はそうした前提条件を満たさなくても、既存のインフラからすぐにデータ連携の開発を始めて、あとからスコープを広げていくことができる。
Talendのもう1つの大きな特長となっているのは、GUIによるコードレス開発だ。したがって、Talendの学習コストは低く、ユーザーはプログラミング言語の文法などを気にすることなく、データ処理の中核部分を短時間で直感的に実装することが可能だ。
ここまでデータパイプラインと表現してきたが、その本質を突き詰めれば“データ処理とその開発”に行き着いていく。データ処理を効率的かつスピーディに開発することで、結果としてシステム間のデータがスムーズに流れていくパイプラインが実現される。また、その一連のプロセスも非常にシンプルだ。Talendスタジオという開発ツールを用いることで、すべてのデータ処理をGUI上で実装できるのである。加えてTalendは、ユーザー数ベースのサブスクリプションで利用できることも大きなメリットとなっている。
こうした特長からTalendを導入する企業はグローバルで拡大しており、菅野氏は、一定の予算内で10倍データ量を処理可能にしたフランスの証券会社「EURONEXT」、データ処理のコストを半減して価値を2倍に高めたイギリスの製薬会社「AstraZeneca」などの事例を紹介した。
もちろん日本でも、高速データローダーからデータカタログ(メタデータ管理)、データ連携、データプレパレーション、ワークフロー、APIサービスまでカバーした「Talendデータファブリックプラットフォーム」をフルラインナップで展開し、本当の意味でのデータ駆動型企業や組織の実現を支えていくとする。
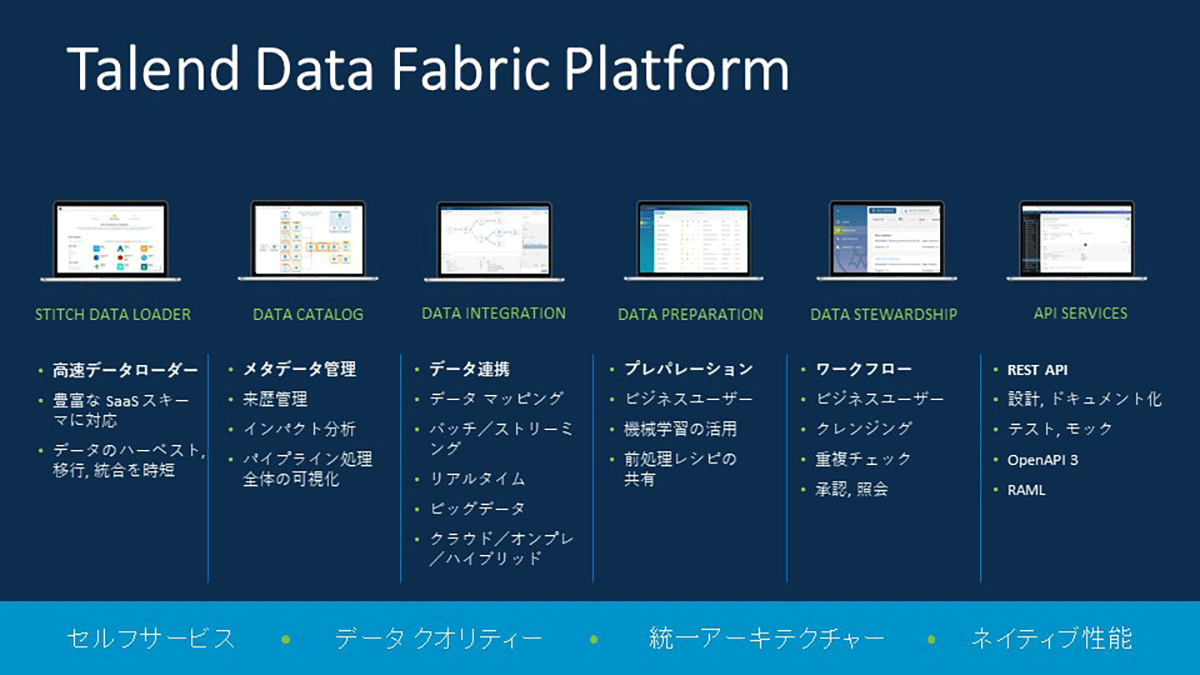 Talendデータファブリックプラットフォーム
Talendデータファブリックプラットフォーム拡大画像表示
●お問い合わせ先

Talend株式会社
E-mail:inquiryJP@talend.com
TEL:03-6427-6370
URL:https://jp.talend.com/contact
- サイロ化された業務体系が阻害要因に~DX時代の競争優位を導くMDMの成功要因とは?(2021/01/25)
- データの価値を最大化する戦略アプローチと、データドリブン文化の醸成に向けて(2020/05/27)
- 社内データの意味を見える化し全方位から把握! ビッグデータ活用は“メタデータマネジメント”が鍵に(2020/04/21)
- アジャイルなデータ統合・活用を実現するデータ仮想化技術の最前線(2020/04/17)
- プラットフォームビジネス事業者が推進する「デジタル革命」─日本企業が考えていなかった、グローバルでは当たり前のデータ活用とは?(2020/04/14)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
