2006年頃からエンタープライズサーチへの注目が急速に高まりつつある。ウェブ2.0の旗手であるGoogleがエンタープライズサーチに参入したことに加え、迎え撃つIBM、Oracle、Microsoftといったエンタープライズの巨人も次々とエンタープライズサーチソリューションを展開しつつある。これら大手ITベンダーの参入により2007年は企業が本格的にエンタープライズサーチ導入に向けて動き出すと考えられる。本稿ではエンタープライズサーチの動向を紹介していきたい。
なぜ今、エンタープライズサーチか
爆発する企業内のデータ
IT環境の進化によって、企業内に蓄積されるデータ量は爆発的な増大を続けている。たとえば、製造業A社の例を見てみよう。A社では、情報共有とコラボレーションのためにLotus Notes/Domino(以下Notes)を全社的に導入している。新製品の開発や障害発生時の記録、各種営業情報などさまざまな活動情報がデータベースに蓄積されている。蓄積の結果、データベース数はおよそ7000にも及び文書数は2000万文書以上という状況になっている。また、これ以外にも各部門単位で使用しているファイルサーバーが存在し、総ファイル数は膨大なものとなっている。情報洪水はあなたの会社でも起こっているのではないだろうか? せっかくの貴重な情報資産であるが、このような情報洪水の中から必要な情報を探し出すことは「干し草の中から針を見つける」ようなものである。
実際に今日のホワイトカラーは、1日の業務時間の多くを溢れかえる情報の処理に費やしている。リアルコムの調査では、平均的なホワイトカラーは1日の業務時間の約50%をPCの前で過ごし、そのうち「情報の検索」や「資料作成」などに業務時間の約40%を費やしている(図1)。そして、これらの時間はデータ量の爆発により、日を追うごとに増加していると考えられている。企業では、蓄積された情報資産を効果的に活用するための方策を検討する必要がある。そこで注目を集めているのがエンタープライズサーチなのである。
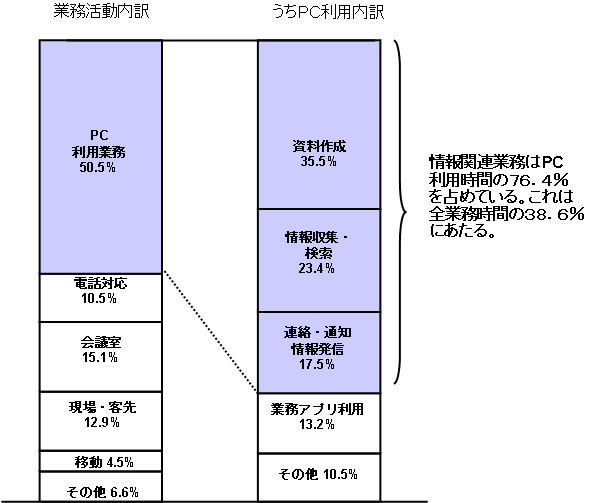
図1 情報収集・活用に要する時間
エンドユーザーの反乱:企業内にもGoogleを
もうひとつ、エンタープライズサーチに注目が集まっている理由の発端はエンドユーザーにある。昨今のホワイトカラーにとってはGoogleの検索エンジンを駆使してインターネット上の膨大な情報から必要な情報を効果的に収集し、活用することはもはや必須スキルといっても過言ではないだろう。あまたの書籍やインターネット上の記事でGoogle検索エンジンの活用方法が溢れかえっているのが現実だ。ひるがえって、企業の中はどうだろう? 前述のようにデータ量は爆発的な増大を続けている。しかし、インターネットのGoogleと比べて、企業内の検索エンジンはなんと使いにくいのだろうと思ったことはないだろうか。「欲しい情報をすぐに探すことができない」「Lotus Notesやファイルサーバー、文書管理システムそれぞれに別の検索エンジンが存在するため、必要な情報を探すために何回も検索をしなければならない」といったストレスを感じているエンドユーザーは非常に多い。「企業内にもGoogle(のような検索エンジン)を導入して欲しい」といった声がエンドユーザーからあがってくるのはある意味必然である。
インターネットサーチとエンタープライズサーチの違い
以上のようにエンタープライズサーチが求められている背景がご理解いただけたかと思う。しかしながら、単純にインターネットの検索エンジンを企業内に導入すれば、エンタープライズサーチが実現できるわけではない。エンタープライズならではの特性を考慮しないと、ツール先行となってしまい、導入は失敗に終わってしまうだろう。そこで、「コンテンツ」「活用シーン」「探すもの」の3つの軸でインターネットサーチとエンタープライズサーチの違いを説明してみたい。
コンテンツにおける違い
まずは検索対象となるコンテンツの違いである。エンタープライズで検索対象となるコンテンツは、インターネットとはまったく違ったものである。インターネットにおけるコンテンツは、基本的にすべてHTMLであり、HTML同士が階層構造を持ったり、リンクを張ったりときわめて構造化された(Structured)形で蓄積されている。インターネットサーチにおいてGoogleが圧倒的な勝利を得た最大の要因は「Page Rank」という検索アルゴリズムにあると言われている。「Page Rank」は重要なページであるほど、たくさんのページからリンクされているという考えに基づいている。また、その中でも重要なページからリンクを張られている場合には、価値が高いと考えられる。このアルゴリズムによりGoogleは他の検索エンジンを圧倒する検索精度を実現し、Alta VistaやYahoo!などに代わってインターネットサーチの王者となった。
これに対して、エンタープライズサーチで検索対象となるコンテンツは、たとえば電子メール、PC上のファイル、ファイルサーバーに格納されたファイル、Lotus Notesなどのグループウェア、イントラウェブ、業務システム、OracleなどRDBMSなど多岐にわたっている。ファイルひとつとっても、PowerPoint、Excel、WordなどのMicrosoft Officeファイル、PDF、テキストファイルなどさまざまである。エンタープライズで扱うコンテンツのうち約80%が非構造化(Unstructured)データであると言われている。
これらの非構造化データでは、コンテンツ同士の関連性や重要度などはまったく分からない。当然の結果として、インターネットで有効であった「Page Rank」のような仕組みは利用することができない。ファイルサーバーなどは自由にファイルの格納が可能であるため、同一ファイルをなんらかの目的でコピーしたものや作成途中で放置されたファイル、まったく利用価値のない古いファイルなどが混然一体となっている。結果として、(表現は悪いが)「ゴミ箱の中を検索してもゴミばかりが見つかる」といったことになってしまう。エンタープライズサーチではこれらのコンテンツの特性を踏まえたうえで、どうすればゴミ箱から宝を見つけることができるかをよく考えなければならない。
活用シーンにおける違い
次に活用シーンにおける違い考えてみたい。インターネットサーチの活用シーンは、インターネットという無限の情報の海の中から未知の情報を探すというものが多いのではないだろうか。このとき、インターネットサーチではキーワードによる検索を行うことになる。単一のキーワードだけでは検索結果として膨大な情報がひっかかってしまうため、複数のキーワードを組み合わせることで、情報を絞り込んでいくことになる。一方、エンタープライズサーチでは企業内の情報は膨大であるとはいえ有限である。また、一説にはサーチの目的の約80%は過去に見たことのある情報のありかを探すことであるという。たとえば、現在取り組んでいるプロジェクトの参考になりそうな資料を過去のプロジェクト成果物の中で見た記憶がある。「その資料は今どこにあるのだろう?」といったように目的のコンテンツの存在はある程度認識しており、そのコンテンツに迅速にたどり着きたいというケースが多いと考えられる。この違いが、インターネットサーチとエンタープライズサーチの大きな違いである。
このようなケースにおいても、キーワードサーチは依然有効ではあるが、それに加えてカテゴリや分類体系による絞り込みを組み合わせることで、検索精度を向上させることができる。たとえば、プロジェクトの名前やテーマをキーワードとして検索するだけでなく、「海外市場向け製品開発」や「経済性分析」といったように、検索対象となるプロジェクトのカテゴリやその中での特定の資料分類などを指定して絞り込むことで、より迅速に欲しい情報を探し出すことができる。キーワードサーチだけでなく、カテゴリや分類によるナビゲーションの併用を求められるのが、エンタープライズサーチの特徴である。
探すものにおける違い
最後に、ユーザーが探すもの、本当にやりたいことについて考えてみる。前述のように過去のプロジェクト資産を探し出し、現在の業務に活かそうというのも一例である。しかし、エンタープライズサーチではこれ以外にも特徴的な例がある。たとえば、「職務管理規定」というキーワードで検索を行ったときのことを考えてみる。この検索を実行したユーザーは「職務管理規定」の「PDFファイルを見つけ出したかったのだろうか?」多分そうではないだろう。「自分の権限で、ある金額の決済を行ってもよいかどうか確認したい」というのがユーザーのニーズであると考えられる。その場合、職務管理規定を作成した人事部の担当者に電話なりメールなりで問い合わせれば確認できるかもしれないし、また場合によっては上司や同僚に確認すれば済む話であるかもしれない。つまりエンタープライズサーチでは単にコンテンツを探し出す以外にも、人や組織を探し出すこともニーズに対する解決策となる場合が多い。そのため、探し出したいコンテンツに紐づく作成者あるいは作成部門といった情報が重要になってくる。コンテンツだけではなく、作成者や作成部門といった情報を同列に扱うこともエンタープライズサーチの特徴である。
エンタープライズサーチのメカニズム
それでは、エンタープライズサーチとは具体的にどのような仕組みで動いているのであろうか。エンタープライズサーチは図2のとおり、大きく3つの構成要素に分けられる。これから各構成要素についてそのメカニズムを明らかにしてみよう。

インデックスの作成:クローラー/コネクタとインデクサ
まず、インターネットサーチと同様に「クローラー」が各検索対象を巡回し、コンテンツを取得する。取得されたコンテンツはインデクサによって解析され、インデックスが作成される。インデックスは書籍における索引にあたり、取得されたコンテンツとキーワードとの紐付けが行われている。
前述のとおり、エンタープライズサーチにおける検索対象は多様である。エンタープライズサーチにおけるクローラーはこれらの多様な検索対象に対応する必要がある。標準機能ではクロールできない検索対象のシステムに対しては、コネクタ(あるいはゲートウェイ)と呼ばれる拡張機能を提供し、これと連携することでクロールを実現することが可能となる。クローラーによって取得されたコンテンツはインデクサによって解析され、インデックスが作成される。
インデクサではコンテンツ毎に索引となるキーワードが抽出され、重要度を判断し重み付けが行われる。キーワードは言語学上の意味を持った「語句」であり、この語句を使って実際の検索が行われる。インデクサによる適切なキーワードの抽出が最終的な検索結果の良し悪しにつながる。キーワード抽出の代表的なアルゴリズムとしては、「形態素解析」と「N-Gram」の2種類がある。形態素解析は、文字列の中から形態素(言語上、意味を持つ最小単位の文字列)、あるいは語句の境界を発見することでキーワードを抽出する方式である。日本語などのアジア圏言語のように、語と語の間に区切り文字のない言語を検索対象とする場合は、キーワードの抽出が困難であるため、この形態素解析によるインデックス作成を売りにしている検索エンジンも多い。
一方、英語などは語句が空白で区切られるという特性を利用し、活用変換・不要語リストとの照らし合わせを行うだけで、比較的単純に語句が抽出できる。形態素解析を使用する場合には、どのように形態素を判別するかがポイントとなるため、検索エンジンが使用する辞書の充実度が抽出精度に影響を与える。N-Gramはそもそも限界のある日本語の形態素解析から離れ、語句ではなく、文字列を任意のN文字で区切ってキーワードを抽出する方式である。形態素解析と比べると機械的に文字列を分割するため、意味のないキーワードも抽出してしまうものの、さまざまな組み合わせでキーワードを作成するため、キーワード抽出漏れが少なくなる。
形態素解析とN-Gramはそれぞれ優れた特長を持っており、どちらが優位にあるとは言えない。そのため、このどちらのアルゴリズムを採用するかが検索エンジンの特色のひとつとなっている。また、検索エンジンによってはどちらかを選択できたり、どちらの要素も併せ持った抽出アルゴリズムを採用した検索エンジンなども存在している。
検索結果の絞り込み:クエリサーバー
作成されたインデックスに対して、ユーザーは検索キーワードを入力し、検索クエリが発行される。発行された検索クエリはクエリサーバーによって処理され、該当する検索結果が表示される。検索キーワードとしては、複数のキーワードを組み合わせて使用するのが一般的になっている。これ以外に、あたかも人に対して質問を投げかけているかのように自然文を検索キーワードの代わりとして利用できる検索エンジンも存在する。しかし、現在の主流はやはりキーワードによる検索である。これはGoogleに代表されるインターネットサーチにおいて、キーワードによる検索が普及していることが一因として考えられる。Googleではキーワード同士をANDやORなどの条件や構文を組み合わせることによって、複雑な検索を行うことができる。これは検索に慣れたユーザーにとっては自然文より直接的で、求めた結果に近い文書を検索できるというメリットがある。検索を行う際に、たとえばコンテンツ作成者/作成部門やコンテンツのタイトル、種別などといったメタデータも検索キーワードとして使用することが可能である。メタデータは検索精度向上の鍵である。
検索結果は、キーワードの集合から表現されるコンテンツとユーザーの検索キーワードとのマッチングによって表示される。これは個々の検索エンジンを特徴付けるうえでも要の技術となっている。この絞り込みの仕組みには、これまでもいくつかの手法が発表されてきた。たとえば、検索キーワードとインデックス内のキーワードとの組み合わせで検索する最も単純な「ブーリアンモデル」がある。これ以外にもキーワードの頻度と単語の重要度(たとえば固有名詞はその文書を特徴付けるうえで一般名詞よりも重要度が高いと考えられる)などで数値的な重みを付け、キーワードをベクトル空間に配置し、類似度も考慮して検索する「ベクトル空間モデル」、「ファジー集合モデル」があり、さらに確率論を組み込んだ「確率モデル」も存在する。
エンタープライズサーチではこれら以外にも、自社独自用語の考慮や同義語・類義語辞書の利用、表記揺れの考慮(たとえば、「マネージャー」と「マネージャ」など)といった拡張機能を使った検索を行うことが可能である。また、インターネットサーチにおけるGoogleのアドワーズのように、検索キーワードに関連した推奨コンテンツを設定しておき、検索結果画面の最上部に表示したり、複数の検索対象システムの中で、どの検索対象システムに存在するコンテンツが重要であるかを設定できる検索エンジンも存在する。さらに、近年では絞り込まれた検索結果に対して動的なクラスタリングを行い、検索結果の分類軸を自動的に提示する検索エンジンも存在する。適切な絞り込みや分類を行い、より良い検索結果を得るために、エンタープライズサーチベンダー各社がしのぎを削っている状況である。
アクセス管理
エンタープライズサーチの構成要素として最も重要な要素のひとつがアクセス管理である。基本的にすべてオープンなインターネット上のコンテンツと異なり、企業内のコンテンツには通常アクセス権が設定されている。このため、検索を行う場合にもそのユーザーがアクセス権を持つコンテンツのみが検索結果として表示されなければならない。ユーザーがアクセスすることを許されていないコンテンツが表示されてしまうことは、企業内においてはあってはならないことである。アクセス権判定の手段は検索エンジンによってその処理方法がまちまちで、たとえばWindows上のコンテンツであればファイルシステムのディレクトリセキュリティに従って検索を行ったユーザーが閲覧可能なものだけを検索結果として表示するといった処理が行われている。また、アクセス権の判定を行う機構としては、検索エンジン側にキャッシュを作成し、そこで判定を行う方式(図2の①)と、検索対象システムに対して1件1件問い合わせを行う方式(図2の②)などがある。(次回に続く)
エンタープライズ検索 / 文書管理 / Google / IBM / Microsoft / Oracle / エンタープライズ2.0 / Web 2.0 / Notes/Domino / グループウェア


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
