Oracle DatabaseはDBエンジンとしての性能向上と並行して、DBシステムとしての技術も充実させてきた。中でも大きく進化したのが「RAC」だ。Part3ではテクノロジーの側面からRACを解剖すると共に、ストレージを仮想化する「ASM」などを用いてDBシステムの拡張性や可用性を高める仕組みを分かりやすく解説する。
安価なハードウェア(サーバー、ストレージ)を利用可能にしながら、性能や可用性、運用の容易性といった相反する要件を満足させる。Part1で示した通り、これがOracle Database 11g R2の最大の特徴である。それを支えるのが、複数のサーバーやストレージをあたかも1つのコンピュータ資源であるかのように使えるようにする「Oracle Real Application Clusters(RAC)」というソフト基盤だ。
11g R2を理解し、活用するためには、RACの構成・仕組み・動作を知ることが早道である。RACはOracle Grid Infrastructureと組み合わせて使用する。Grid Infrastructureは、Oracle ASM( Automatic Storage Management)というストレージ管理機構と、Oracle Clusterwareと呼ばれるクラスタ構成要素の監視機構を統合したものである。そこで本パートではアーキテクチャを図示しながら、RAC、ASM、Clusterwareの3つを中心に解説する。
Oracle RAC
可用性からグリッドへ進化を続けるRAC
まずRACについて、発展経緯から見ていこう。DBシステムは10年ほど前まで、1つのDBを1つのサーバーで動かす「シングルインスタンス」が一般的だった。しかしこの方法では、例えば性能を高めるのに高性能のサーバーを使うスケールアップしかなく、サーバー(ノード)に障害が発生すると処理が停止してしまう。
そこで2001年、オラクルはOracle9iと同時にRACをリリースした。当時は、「1つのデータベースサービスの拡張性や可用性を高める」という意味合いが強かった。具体的には、1つのアプリケーションのトランザクション(更新処理など)を、クラスタを構成する複数のノードに分散させる形態を採っていた(図3-1左)。
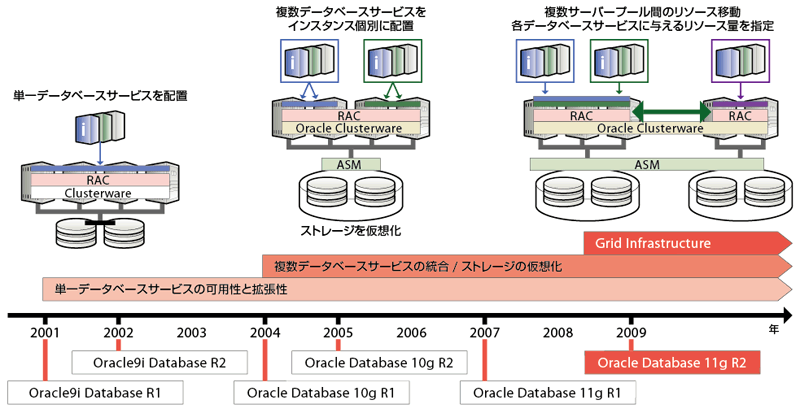
主に単一DBシステムの拡張性を高める機能として登場した後、2度の大きな技術改良によって 同一クラスタ上に複数のDBシステムを実装したり、RAC間でリソース共有したりできるようになった
Oracle 10gからは、1つのクラスタ上で複数のデータベースサービスのリソース使用状況を区別することができるようになり、CPU資源の仮想化を可能にした(同中央)。それと同時にストレージ仮想化レイヤーとしてOracle ASMを実装(ASMの詳細は後述)。CPUやストレージの仮想化により、すでに存在するクラスタ上にDBアプリケーションを迅速に配置できるグリッドの基盤を整えた。
一方、Oracle RAC 11g R2では、(1)クラスタへのノード割り当ての自動化、(2)クラスタ間でのサーバー(ノード)リソースの共有、(3)ASMの機能拡張によりデータベース以外のファイルも管理、といった機能を提供するよう進化した(同右)。その結果、簡単に言えば安価なサーバーやストレージを多数接続した“スケールアウト型”のデータベースの基盤として、高い完成度を持つようになった。グリッド、流行り言葉で言えばクラウドにおけるDBMSの基盤だと言える。
データの取得を効率化するRACのキャッシュ技術
しかし、ここで次のような疑問が出てくるかも知れない。「利点が多くても、RACへの移行はアプリケーションの変更が必要になるのでは?」、「複数のノードをまたがってデータの一貫性を維持する以上、性能低下は免れないのではないか?」。
RACは、こうした疑問に応えるアーキテクチャを備える。1つがデータベースの表や索引を格納した「表領域」の持ち方だ。一般にシングルインスタンスのデーターベースシステムは、データの更新処理などを実行するインスタンスが、表領域に直接アクセスする構造になっている。シェアードディスク方式をとるOracle RACは、実はこの基本構造が全く同じであり、OracleクライアントはどのOracleインスタンスに接続しても、同一のデータアクセス性を得られる(図3-2)。したがってアプリケーションを変更する必要はない。
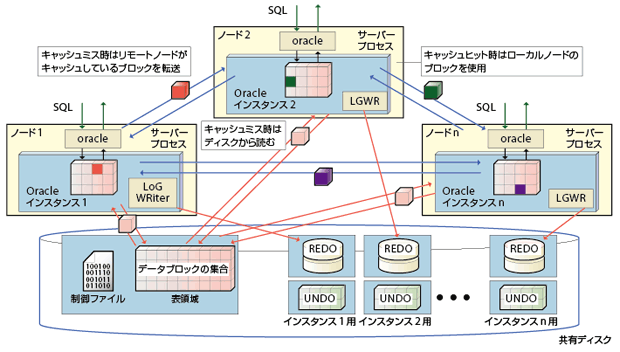
クラスタを構成する複数のノードが、共有ディスク内にある同じ表領域にアクセスする。このため個々のノードから見ると、シングルインスタンス並みのシンプルなデータアクセスが可能になる
もう1つがデータのキャッシュ方法。少しややこしいが、キャッシュミスした場合を例に説明しよう。図3-3を見て欲しい。キャッシュをミスしたOracleインスタンス(図ではインスタンス2)は、まず該当データブロックのキャッシュ状態に責任を持つ別のOracleインスタンス(リソースマスターと呼ぶ。図ではインスタンスn)に対し、ブロックの取得を要求する(なお、リソースマスターの役割はすべてのOracleインスタンスが分担して果たしている)。
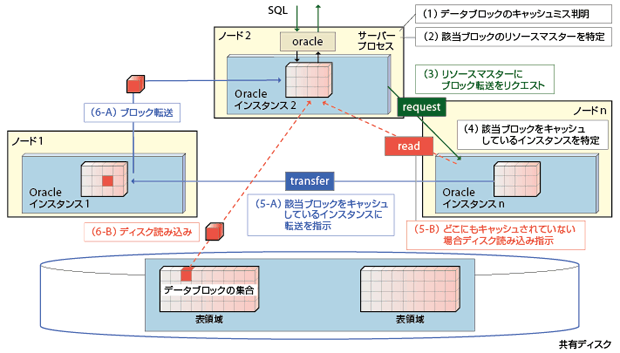
クラスタを構成するノードがそれぞれ特定のデータの所在を管理する。 この仕組みより、ノード数がどれだけ増えても最大3ノードを経由すれば必要なデータを取得できる
リソースマスターは、該当ブロックをキャッシュしているOracleインスタンス(インスタンス1)に対し、ブロックの転送リクエストを送出。インスタンス1は、最初にリクエストしたインスタンス2に転送する。キャッシュしているOracleインスタンスが存在しない場合にのみ、リソースマスターはインスタンス2に対しディスクから取得するよう指示する。
理解いただけただろうか。この仕組みがCache Fusionである。Cache Fusionによるノード間のブロック転送は、ディスクから取得するよりも高速だし、データブロックを取得するリクエストは最大でも3ノードしか経由しないため、ノード数がどれだけ増えてもキャッシュミスの影響は極小に抑えられる。
ASM
仮想化機能を駆使して煩雑な管理を自動制御
一方、クラスタ構成をとる大規模なDBシステムでは、ストレージの問題も考慮する必要がある。例えば既設のストレージシステムで容量が不足しそうになった場合、増設を検討しなければならない。だが単純に増設すると、稼働中のストレージと追加したストレージの内容の割り当て方が均質でなくなる。そのため特定のストレージにアクセスが集中してしまう事態も、起こり得る。
こうした問題を解決するのが、「ASM(Automatic Storage Management)」だ。ASMは複数の物理ディスク(ASMディスク)を仮想的に1つのストレージプール(ASMディスクグループ)として稼働させる機能を持つ。
具体的にASMの機能を説明しよう。ASMではデータベースを構成するファイル(ASMファイルと呼ぶ)を新規に作成する際、ASMディスクグループ内のすべてのASMディスクに、均等にASMファイルを分散格納していく(図3-4の下部)。ASMディスクの使用量とアクセス頻度を均一にする仕組みなので、ディスク容量と性能の管理を簡素化できるわけだ。
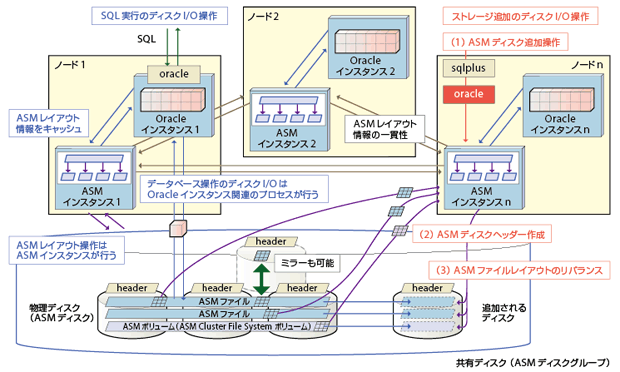
複数の物理ディスクを仮想化し、クラスタのノードに対してあたかも1つディスクのようにみせる。データベースのファイルは自動的に分割され、仮想化したすべての物理ディスクに均等に格納する
ディスクを増設する場合も同様である(同右部)。物理ディスクを追加した上で、あるノードからディスクをASMディスクグループに加える指示をすると、新しいディスクにヘッダーを作成。数秒でASMの管理下で使えるようになる。このとき追加したディスクを含むASMディスクグループ内でデータを自動的に再配置(リバランス)し、ASMディスクの使用率のバランスを保つ。この処理はバックグランドで実行するので、システム停止の必要はない。
複数のディスクに分散したASMファイルの物理レイアウトは、「ASMインスタンス」 が管理している(図3-4中央)。SQL実行に必要なディスクI/OをOracleインスタンス関連のプロセスが直接行うなど、ASMによるオーバーヘッドを極小に抑える仕組みになっている。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
Oracle / Oracle RAC / Oracle Database / RDBMS / データベース仮想化



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
