ビッグデータを扱うための基盤環境として真っ先に名前が挙がるのが、ご存じ「Apache Hadoop/MapReduce」。一方で、数年前から先進企業/エンジニアの間で“ポストHadoop”と呼ばれている技術があります。UCバークレー・AMPLab発の「Apache Spark」です。先月、IBMが「今後10年間で最も重要なオープンソースプロジェクト」と位置づけてSparkへの注力を宣言するなど、ここにきて普及の兆しもあります。そこで、まずは「Sparkって一体何?」というレベルから動向を確認してみます。
「インメモリ環境でHadoopの100倍高速」
Apache Sparkを用語解説的に説明するなら、「RDD(Resilient Distributed Dataset)という抽象化データセットを技術基盤として、Scala言語で実装されたオープンソースの分散処理プラットフォーム」といったところでしょうか。ビッグデータやデータサイエンスがブームになる直前の2009年、カリフォルニア大学バークレー校のAMPLab(Algorithms, Machines, and People Lab)で開発が始まり、2013年にApacheソフトウェアファウンデーション(ASF)に寄贈、翌2014年5月にバージョン1.0となってASFのトップレベルプロジェクトに昇格しています。開発主体はUCバークレー出身のベンチャー企業、データブリックス(Databricks)で、現行のバージョンは2015年6月にリリースされた1.4です。
 画面1:Apache Sparkプロジェクトサイト(出典:The Apache Software Foundation)
画面1:Apache Sparkプロジェクトサイト(出典:The Apache Software Foundation) 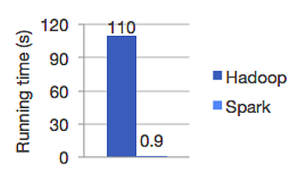 図1:SparkとHadoopのロジスティック回帰処理速度比較(出典:The Apache Software Foundation)
図1:SparkとHadoopのロジスティック回帰処理速度比較(出典:The Apache Software Foundation)Apache Sparkプロジェクトサイト(画面1)には、「Sparkは、高速で多目的に対応する大規模データプロセッシングのためのエンジンである」とあり、「Hadoop/MapReduceと比較して、インメモリ環境で100倍、ディスク環境で10倍高速に処理できる」と謳われています。高速分散処理で知られるHadoopの10~100倍という、画期的な処理スピードがSparkの大きな売りになっています(図1)。
この顕著な高速化をはたしたカギは、上述のRDDと、「DAG(Directed Acyclic Graph:有向非巡回グラフまたは有向非循環グラフ)」という実行エンジンにあるようです。有向非巡回グラフ……実に耳慣れない言葉です。以下、専門家の解説を引用・要約してみます。
●Sparkで採用されたDAGは分散システムに特化したプログラミングモデルであり、MapReduceの代替としてみなすことができる。
●DAGによる実行は、Apache Tezと同様、MapReduceのように中間結果をディスクに書き込まない仕組みをとる。そのためインメモリの高速性を最大限に享受できる。
●MapReduceは、MapとReduceの2つの処理ステップしか持たないが、DAGでは、ツリー構造を形成可能な複数レベルの処理ステップを持つことができる。例えば、SQLクエリを実行する際、DAGではMap、Filter、Unionといった多くのファンクションを実行できる。
出典:実名制Q&AサイトQuoraでのAbishek Baskaran氏の投稿を引用要約)
会員登録(無料)が必要です


- 1
- 2
- 3
- 次へ >
- セールスフォースがSlackを買収、目指すは“次のクラウド革命”:第57回(2020/12/02)
- モダナイズ型の事業創出に注目、コニカミノルタの「Workplace Hub」:第56回(2018/12/13)
- デジタルトランスフォーメーションでアジアに後れを取る日本企業、課題はどこに:第55回(2018/02/28)
- 施行まであと1年半、EUの新データ保護法「GDPR」への備え:第54回(2017/01/31)
- 基盤、機器、管理ソフトが丸ごと揃う「IIJ IoTサービス」はどのぐらい魅力的?:第53回(2016/07/20)
Hadoop / OSS / IBM / データサイエンティスト / Databricks / Apache Spark



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
