「ビッグデータ」「データサイエンティスト」といったキーワードとともに、データ分析が注目されています。しかし実際には「何をやれば良いのかよく分からない」「どんな人材を育てれば良いのか」という声を多々耳にします。筆者らのデータ分析チームは、「KDD Cup 2015」というデータ分析の国際大会で2位に入賞しました。本連載では、同大会でのデータ分析の中で分析者が何を思い、何を考え、何をしたのかを題材に解説します。私たちの思考の足あとを通して、読者の皆様にデータ分析とは何かを少しでも伝えられれば幸いです。第1回は、本連載の題材であるKDD Cupに代表されるデータ分析競技の世界を紹介します。
2015年7月13日月曜日の午前9時、データ分析の国際大会「KDD Cup 2015」の競技が終了し、その結果が発表されました。筆者ら新日鉄住金ソリューションズ(NSSOL)と金融エンジニアリング・グループ(FEG)の混成チームである「FEG&NSSOL@DataVeraci」の結果は世界第2位でした。
その瞬間、第2位を喜ぶメンバーは1人もいませんでした。「なんとかたどり着いた2位」ではなく、「長らく守ってきた暫定1位の座から最終日に転落しての2位」という悔しさと、この2カ月強にわたる競技の緊張からの解放感と、「やれるだけのことはやった」という達成感と、やりきれなかった分析についての後悔と、とにかくみな、それぞれに疲れた顔をしていました。
 写真:KDD Cup 2015の授賞式では笑顔を見せたチームのメンバー
写真:KDD Cup 2015の授賞式では笑顔を見せたチームのメンバーデータ分析競技は2〜3カ月をかけて開催される
筆者らが第2位に入賞したKDD Cupは、データ分析競技の元祖といえる大会です。コンピュータ科学分野の国際学会であるACM(Association for Computing Machinery)のデータ分析の分科会「SIGKDD(Special Interest Group on Knowledge Discovery and Data Mining)」が毎年主催する国際会議「KDDカンファレンス」とともに開催されます。毎回、世界的な企業がスポンサーになりデータと課題と賞金を提供し、大学や企業の研究者など幅広い層の参加者を集めています(表1)。2015年は821チームが参加しました。
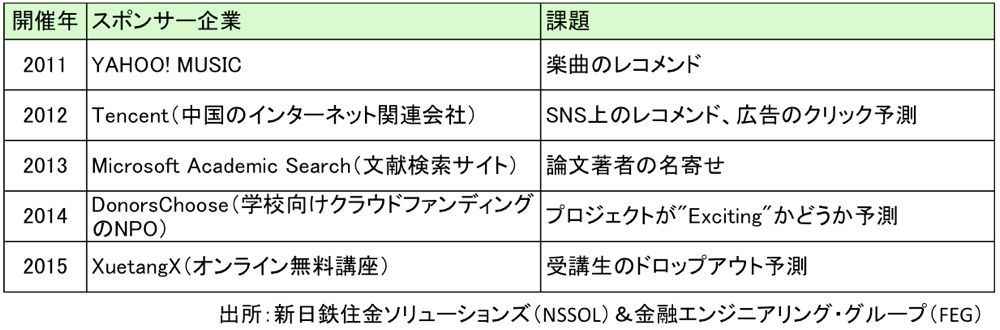 表1:KDDCupの過去5年間のスポンサー企業と課題
表1:KDDCupの過去5年間のスポンサー企業と課題拡大画像表示
データ分析のコンペとして今、最も規模が大きく有名なのは「Kaggle(カグル)」というプラットフォームです。このWebサイトでは複数のコンペが日常的に開催されています。2015年10月時点で、世界中で約40万人が参加者としてアカウントを登録しています。最近では1つのコンペに1000人以上が参加することも珍しくありません。KDDCupも2012年から2014年は、このKaggleの上で開催されました。
多くのコンペは2〜3カ月程度の期間にわたって開催されます。まず主催者はデータ分析の目標となる課題を設定し、課題を解決するためのデータをWebサイトに公開します。よくある問題設定としては、「ある時点までのデータを元に将来を予測する」「一部の人のデータを元に残りの人の行動を予測する」などがあります。
参加者はWebサイトからデータをダウンロードし、機械学習などの手法を駆使して予測結果を出力してWebサイトに提出することで、その精度を競います。競技期間中は毎日、分析結果を数回投稿して更新できます。これを積み重ね、競技終了時点で最も精度が高いモデルを提出した参加者が優勝となります。
KDD Cup 2015の課題は、「中国のオンライン無料講座(MOOC:Massive Open Online Courses)サイト『XuetangX』における受講者の脱落を予測する」というものでした。匿名化されたアクセスログが公開され、コンペの参加者は、誰がどの講座から脱落しそうかを確率として予測しました。
データから、データの後ろにあるビジネスを見ている
もう少し詳細に、実際の競技の流れを順を追って説明しましょう(図1)。
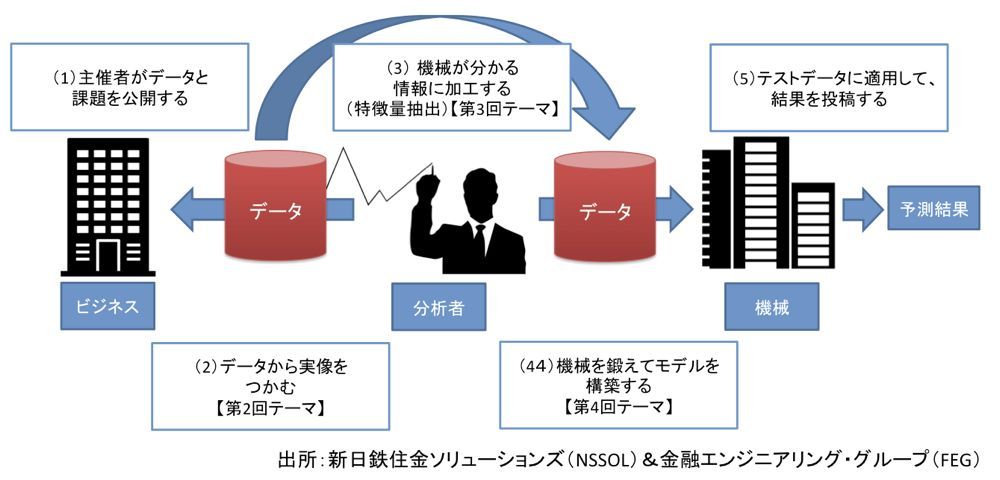 図1:データ分析競技は大きく5つステップで進行する
図1:データ分析競技は大きく5つステップで進行する拡大画像表示
ステップ1:データと課題の公開
多くのデータ分析競技はWebサイト上で開催されます。主催者はWebサイトにデータ分析で解決したい課題を公表し、データを用意します。競技期間は、先に述べたように2〜3カ月程度です。
競技開始と同時にデータが公開され、参加者はデータをダウンロードできるようになります。KDD Cup 2015の例でいえば、課題は受講生の離脱予測で、データはMOOCサイトのアクセスログです。
ステップ2:課題とデータを理解する
競技参加者は、Webサイトに記載されている課題の説明とデータの定義、ダウンロードしたデータを確認します。ただし、課題を考えた人や、データを作った人に直接話を聞くことはできません。データがどのように作られ、課題とデータがどのように関連するかを、データを見ながら考えるのです。
このとき分析者は、データを見ながら、データの後ろにあるビジネスを見ています。この中でふと、点と点が線でつながる瞬間があります。データ分析をしていて最も気持ちがいい瞬間の1つです。分析者の傲慢かもしれませんが、実際にビジネスを担当している人よりも、分析者の方が全体像がよく見えているということさえあります。
ステップ3:データを加工する
優れた分析者はデータを通してビジネス、つまり人間の行動を見ることができます。KDD Cup 2015の例では、ログデータを見ることで、「この人はきっと真面目だ」とか「この人は三日坊主だ」とか、受講者の様子が想像できます。
しかしコンピュータはそうはいきません。コンピュータは人間よりも凄くたくさんの数字や文字を記憶できますし、凄くたくさんの計算をミスなく、しかも人間よりも圧倒的に早くこなせます。ただ少なくとも2015年時点では、人間である分析者ほど人間のことを分かっているわけではありません。ゆえに、生のデータをそのままコンピュータに渡すだけでは、よい分析はできません。分析者はデータを通して自分が見た人間行動を、コンピュータが理解できるように翻訳する必要があります。
具体的には、データを加工して特徴を分かりやすく表現します。この作業を「特徴量抽出」といいます。ここではコンピュータにもよく分かるようにしつつ、データの中に含まれる必要な情報を落とさないようにしなければなりません。KDD Cup 2015で筆者らのチームは第2位でしたが、特徴量抽出では1位だったと自負しています。
ステップ4:モデルを構築する
特徴量抽出したデータを利用して、コンピュータに法則性を学習させます。これがモデルを構築する作業です。主催者が用意するデータには、学習用とテスト用があります。学習用データの答えは、データとして参加者にも与えられます。ですが、テスト用の答えは主催者しか知りません。参加者は学習用データを利用してモデルを構築します。
KDD Cup 2015では、学習用データが約12万件(受講単位)、テスト用が約8万件でした。つまり参加者は約12万件のデータを使って、コンピュータに法則性を学習させています。最もデータサイエンスらしい部分ですが、このステップで働くのはコンピュータで、私たち分析者はむしろコンピュータをどう働かせるかを考えています。方針を与えたり、作業の優先順位を決めたりします。
ステップ5:テストデータに適用して、投稿する
テスト用データにモデルを適用し、答えのみをWeb経由で投稿します。投稿すると主催者側が自動的に答え合わせをし、予測の評価点数を算出します。この点数のみが評価対象で、競技終了時点のベストスコアによって順位が決まります。投稿回数には各参加者1日5回までなどの制限がありますが、競技期間中は何回も投稿できます。
KDD Cup 2015では、約12万件のデータでコンピュータに学習させた法則を使って、テスト用の約8万件の結果を予測します。具体的には、講座受講を脱落する確率を計算し、キーと確率の2列からなるデータ(csvファイル)をサイトに投稿します。
会員登録(無料)が必要です


- 1
- 2
- 次へ >
- データ分析の新潮流と、未来を支える人材像:最終回(2016/05/12)
- データを“武器”にするためのビジネス思考とは【第6回】(2016/04/21)
- データサイエンティストのチーム力学【第5回】(2016/03/17)
- 実像に迫るためにコンピューターを鍛え上げる【第4回】(2016/02/16)
- コンピュータが理解できる情報とは何か:第3回(2016/01/21)
データサイエンティスト / アナリティクス / マシンラーニング / ハッカソン / アワード / 日鉄ソリューションズ / DataRobot




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
