筆者らのデータ分析チームは、「KDD Cup 2015」というデータ分析の国際大会で2位に入賞しました。これまで、「オンライン無料講座からの離脱者を予測する」という同大会の課題に対し、講座のアクセスログから受講者がどんな行動を取っているかを想像し、コンピューターが離脱を予測しやすいようデータを加工して特徴量を作るところまで、筆者らの取り組みと思考について説明してきました。今回は、その特徴量からコンピューターに離脱する人の法則性を学習させる過程で、筆者らが考えた中身を紹介します。
第3回で紹介したように、データ分析では特徴量を抽出しなければなりません。人間が苦労して作った、その特徴量を入力として、例えば「XGBoost」といったソフトウェアが学習し、法則を発見します。この法則を、筆者らは単に「モデル」と呼びます。業界用語ですので、業界外の方と話すときは「予測モデル」とか「予測プログラム」などと補足したり言い換えたりしています。
モデルは、未知の特徴量を入力として法則を適用し、今回の課題であれば、離脱する/しないといった予測結果を出力します。競技では、この予測精度を競っているのです。モデルの精度、すなわち性能は、プログラムの処理手順であるアルゴリズムによって異なりますし、入力される特徴量や処理の実行条件(ハイパーパラメーター)によっても大きく変わります。
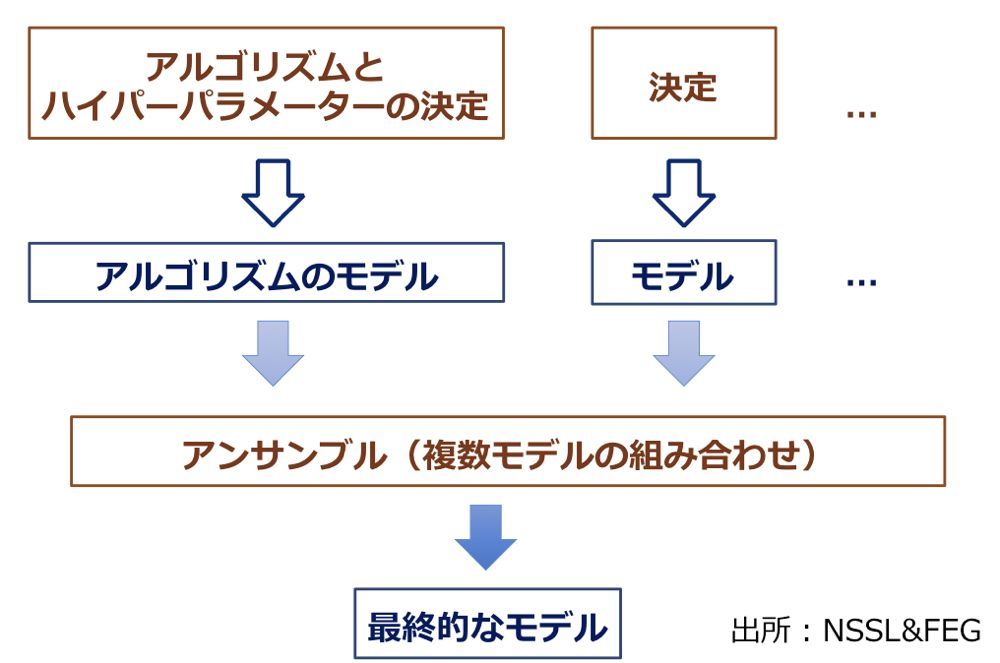 図1:モデル構築の全体像
図1:モデル構築の全体像拡大画像表示
ですので、コンピューターを鍛えて性能を高めるためには、考えなければならないことが沢山あります。どのアルゴリズムを選ぶのか、あるいは自作するのか、ハイパーパラメーターをどの値にするのか、複数のアルゴリズムをどう組み合わせるのかなどです(図1)。
学習に使うプログラムは、XGBoostのように公開され定番になっているものが大半ですが、それでも「データを入れればOK」とはなりません。コンピューターを鍛え上げるには、上記のように、色々と悩みどころがあるのです。以下では、まずは何を鍛えるのかを説明し、その後に、どのように鍛え上げるのかについて、KDD Cup 2015で実施した内容を中心に紹介していきます。
会員登録(無料)が必要です


- 1
- 2
- 3
- 4
- 5
- 次へ >
- データ分析の新潮流と、未来を支える人材像:最終回(2016/05/12)
- データを“武器”にするためのビジネス思考とは【第6回】(2016/04/21)
- データサイエンティストのチーム力学【第5回】(2016/03/17)
- コンピュータが理解できる情報とは何か:第3回(2016/01/21)
- データから、そのデータを生み出した実像をつかむ【第2回】(2015/12/17)


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
