2010年代に入ってから、ビッグデータが多くの企業から注目されている。その理由は、ビッグデータを活用することで、同業他社との差別化を図り、売上拡大や業務効率化により企業価値を向上させることができるからである。ビッグデータを蓄積/処理する基盤としてDWH向けRDBMSやHadoopがあり、成り立ちやアーキテクチャは異なるが、データを格納して、SQLをインタフェースとしてデータにアクセスすることができる点など、利用者から見ると違いが分かり難くなってきている。そこで日本ユニシスでは、DWH向けRDBMSとHadoopを用いて、データロード、データ検索について性能面での比較検証を行い、SQL on Hadoop(Hadoop内のデータをSQLで処理する機能)の適用範囲について考察を行った。本稿では検証結果と考察を報告する。
※本稿は日本ユニシス発行の「技報通巻127号」(2016年3月発行)の記事に加筆・編集して掲載しています。
データ検索(同時実行)
データ検索を複数同時に実行した場合のHive、Drill、Verticaの処理時間の増加傾向とリソース状況を確認する。検証概要は,表8の通りである。
 (表8)
(表8)拡大画像表示
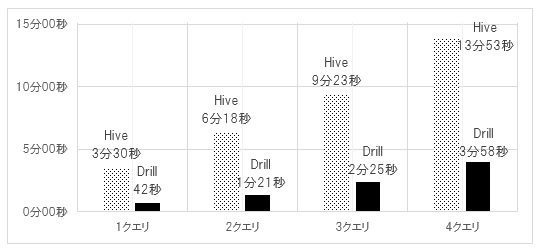
まず、Hive、Drillは、MapReduceより汎用的なフレームワークであるYARNのCore数を4と設定したため、4クエリまでの検証を行った。検証結果は、図9の通りである。
 (図9)
(図9)拡大画像表示
Hiveはクエリ数に比例して処理時間が長くなっており、各クエリの開始、終了時刻は同じであるため、すべての処理が同時に実行されている。MapReduceではデフォルトのジョブスケジューラであるFair Schedulerによって、同時に実行される処理に対して均等にリソースが割り当てられることから、並列度が増えれば1処理に割り当てるリソースは相対的に少なくなるため、処理時間も増加する。クエリ数を2倍にすると各クエリの処理時間も2倍になっていることから、同時実行性が高いとは言えない。
Drillもクエリ数に比例して処理時間が長くなっており,各クエリの開始,終了時刻は同じであるため,すべての処理が同時に実行されているが,3クエリと4クエリでの同時実行では,実行中にCPU使用率が100%に達して,CPU待ちが発生したことにより,1クエリをシリアルに実行した場合に比べて処理時間が長くなった.core数を増加することで,処理時間の増加は抑えられると考えるが,Hive同様,同時実行性が高いとは言えない.
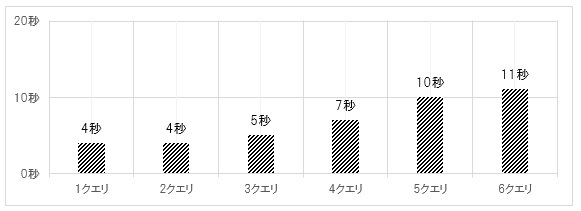
次に、Verticaは1サーバーのcore数が6であるため、6クエリまで検証を行った。検証結果は、図10の通りである。
 (図10)
(図10)拡大画像表示
1クエリを基準に見ると、クエリ数の増加に比例して処理時間は増加していないため、Hive、Drillに比べて同時実行性の高さが確認できる。実行したクエリの開始、終了時刻は同じであるため、すべての処理が同時に実行されている。これにより(仮設5)が立証されたことになる。
3クエリ以上で処理時間が長くなっているが、これはCPU使用率が100%に達しているためで、今回のケースでは一つのクエリで2core程度のCPUリソースを使って処理を行っているため、1サーバーに割り当てるcore数を倍の12coreに増やすことで6クエリでも1クエリと同じ処理時間で終わらせることが期待できる。
データロード+データ検索
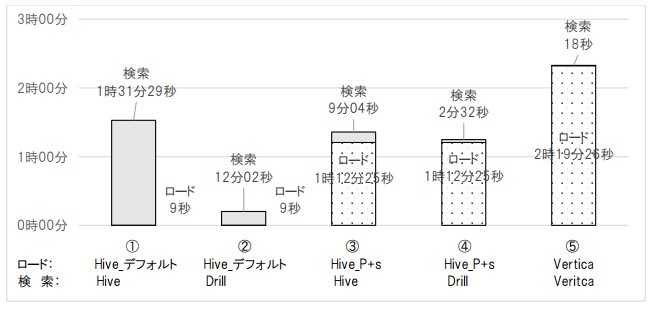
データロード+データ検索として、データロードの時間とデータ検索(グループ集計)の検索時間の合計処理時間を確認する。
 (図11)
(図11)拡大画像表示
Hive(①、③)に比べてDrill(②、④)の合計処理時間の方が短いため、検索はDrillを使うべきである。また、Verticaの合計処理時間(⑤)とHive_デフォルト、Drillの組み合わせ(②)との合計処理時間の差は2時間7分33秒となっている。処理時間の差のほとんどは、ロード時間であるため、検索頻度によって最適な方式を選択する。繰り返し検索しないデータはHiveのデフォルト形式にロード、繰り返し検索するデータはP+s圧縮形式にロード、頻繁に検索するデータはVerticaにロードすべきである。これにより、(仮設2)と(仮設3)が立証されたことになる。
SQL on Hadoopの適用範囲についての考察
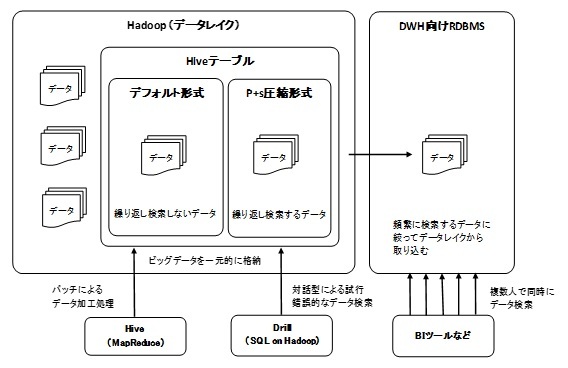
今回の検証では,データ量・ハードウェア・割り当てリソースが同じ条件で性能検証を行った。ロードが早く、メモリを有効活用することによりHiveに比べて検索時間が短く、対話型による試行錯誤的なデータ検索にも適用できるという仮説を証明できた。各技術の適用は、図12の通りとなる。
 (図12)
(図12)拡大画像表示
しかし、ソリューションの選定には、性能だけではなく、ユーザの利用特性やコストなども勘案することが一般的である。DWH向けRDBMSは検索の性能は明らかに高いが、分析対象データを全て取り込むとライセンス費用がHadoopと比較して高価になることが多い。また、ロード時間もかかることから、分析目的が明確なデータしか取り込めない。
一方Hadoopは、DWH向けRDBMSに比べてライセンス費用が安価でロードが速いため、分析目的が明確ではないデータも取り込み、大容量データを扱えるファイルシステム(データレイク)として活用することができる。
検索性能、同時実行性能に関しても、コストを評価軸に加えた場合には、HadoopはDWH向けRDBMSよりもノード数を増やすことができるため、今回の検証結果よりも処理時間の差を縮めることができる。
また、データを利用するユーザ数が限定され、データベースの維持管理を行う専任要員を配置するのが難しい場合には、DWH向けRDBMSよりも、SQL on Hadoopで構築、運用する方が適している。
したがって、コスト・ユーザー利用特性・専任要員の有無の観点などを考慮した場合には、必ずしもDWH向けRDBMSが最善とは言えず、SQL on Hadoopの選択が最適なケースもある。
おわりに
本稿では、SQL on Hadoopの適用範囲について考察した。性能面での検証を行った結果、データレイクにおける対話型の検索ツールとしてSQL on Hadoopは有用であることが確認できた。今後、SQL on Hadoopのさらなる進化や新しいHadoopエコシステムが登場し、DWH向けRDBMSの性能により近づくことを期待する。
日本ユニシスで提供している「データ統合・分析共通PaaS」は、今回検証を行ったMapRとVerticaで構成している。今後、Apache Sparkなどの検証を行い、機能拡充による商品力向上に取り組んでいきたい。
日本ユニシスでは、基幹系システムだけでなく情報系システムの構築実績も多数あり、多岐にわたる顧客要望にビッグデータ技術を駆使して対応している。今後も顧客の期待に応え続けるために、最適なビッグデータソリューションを提供していく所存である。
参考文献
[1] James Manyika、Michael Chui、Brad Brown、Jacques Bughin、Richard Dobbs、Charles Roxburgh、Angela Hung Byers、「Big data: The next frontier for innovation, competition, and productivity」、McKinsey Global Institute 、2011年5月
[2] Sanjay Ghemawat、 Howard Gobioff、 Shun-Tak Leung、「The Google File System」、2003年
[3] Jeffrey Dean and Sanjay Ghemawat、「MapReduce: Simplified Data Processing on Large Clusters」、2004年
[4] Michael Manoochehri、小林啓倫、「ビッグデータテクノロジー完全ガイド」、2014年11月
[5] 山崎慎一、「企業情報システムとデータの活用範囲の拡大」、ユニシス技報、日本ユニシス、Vol.31 No.4 通巻111号、2012年3月
[6] 羽生貴史、「データベース技術の動向」、ユニシス技報、日本ユニシス、Vol.29 No.2、通巻101号、2009年3月
[7] 総務省、「平成24年版情報通信白書」、2012年6月
[8] 総務省、「平成25年版情報通信白書」、2013年7月
[9] 鈴木良介、「ビッグデータビジネスの時代」、株式会社翔泳社、2012年3月
[10] Edward Capriolo、Dean Wampler、Jason Rutherglen、玉川竜司訳、「プログラミングHive」、オライリー・ジャパン(発行元)、2013年6月
[11] W.H.Inmon、藤本康秀、小畑喜一、「初めてのデータウェアハウス構築」、1995年12月
[12] 日本ユニシス、「データ統合・分析共通PaaS」
http://www.unisys.co.jp/solution/biz/bigdata/solution/paas.html
清酒文人、小原未生
日本ユニシス


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
