SAPジャパンは2017年11月7日、WebログやSNSデータなどの日々発生するビッグデータやDWHに格納されている業務データなど、様々なデータを引っ張ってきて集計・加工して活用できるようにするミドルウェア「SAP Data Hub」を発表した。ビッグデータ処理用のインメモリー型分散処理エンジンとして「SAP Vora」のコンポーネントを組み込んでいる。
SAP Data Hubは、企業内の様々なデータを引っ張ってきて集計・加工して活用できるようにするミドルウェアである。個々の部門の業務ユーザーが必要とするデータを、GUIベースの簡単なデータ設計ツールによって、個々の部門の業務ユーザーに提供できるようになる。
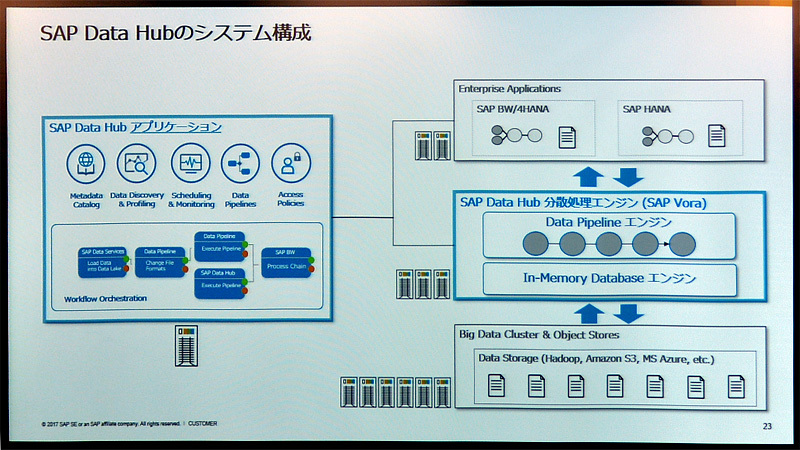 図1●SAP Data Hubのシステム構成。インメモリー型の分散処理エンジン「SAP Vora」を組み込んでいる。ETLソフトと組み合わせることでビッグデータ以外の各種データもSAP Vora上で扱えるようになる(出所:SAPジャパン)
図1●SAP Data Hubのシステム構成。インメモリー型の分散処理エンジン「SAP Vora」を組み込んでいる。ETLソフトと組み合わせることでビッグデータ以外の各種データもSAP Vora上で扱えるようになる(出所:SAPジャパン)拡大画像表示
特徴は、インメモリーで動作する分散データ処理エンジンであるSAP Voraをデータ処理のエンジンとして使っていること。これにより、高速に集計・加工できる。また、機械学習ライブラリをデータ処理のフローに組み込むなど、データ処理のパイプラインを設計できる。データ処理は、トリガー駆動やスケジュール駆動ができる。
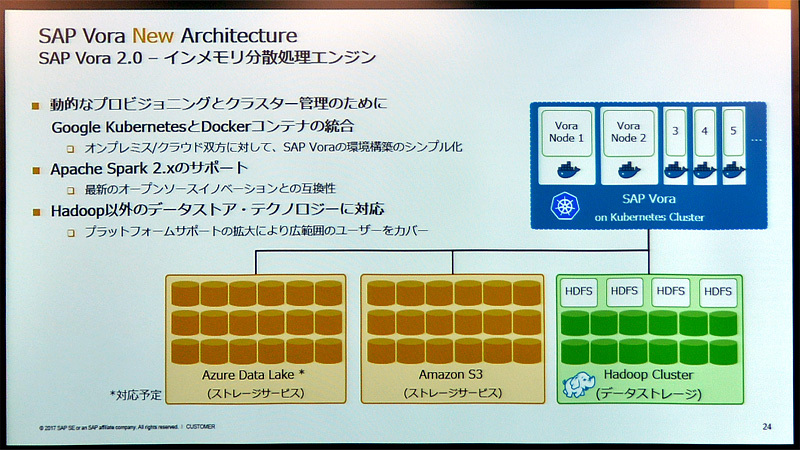 図2●SAP Voraの概要。Hadoop上のデータやAmazon S3上のデータソースに対して、Dokerコンテナを使ってインメモリーで分散処理する(出所:SAPジャパン)
図2●SAP Voraの概要。Hadoop上のデータやAmazon S3上のデータソースに対して、Dokerコンテナを使ってインメモリーで分散処理する(出所:SAPジャパン)拡大画像表示
ビッグデータのデータソースとして、SAP VoraのデータソースであるHadoppとAmazon S3ストレージを利用できる(今後、Azure Data Lakeに対応予定)。別途ETL(抽出/加工/格納)ソフトである「SAP Data Services」と組み合わせることで、RDBMS(リレーショナルデータベース管理システム)など各種のデータを引っ張ってきてSAP Vora上で処理できる。
SAP Data Hubを提供する背景について同社は、マーケティング部門やビッグデータ分析部門を介することなく、これらの部門が扱っているビッグデータにアクセスして活用できるようにしたいという需要を挙げる。「業務部門は、SAP Data Hubを使うことで、これらビッグデータと業務データを組み合わせて分析できるようになる」(同社)。




- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
