富士通研究所は2019年10月16日、データベースと検索内容を暗号化したまま照合できる秘匿検索技術を強化し、暗号化されたデータベースから元データの類推を防止することで、より安全に照合できる技術を開発したと発表した。クラウド環境など様々な場所で管理されるデータベースを安心して使うことが可能になる。
富士通研究所が開発した技術は、データベースに最小限のダミーデータを追加することによって、データベース上の登録数を攪乱し、元データの類推を防止する技術である(図1)。元データの類推を防止することにより、クラウド上など様々な場所で管理しているパーソナルデータ(個人に関する情報全般)や機密データ(企業が開示を予定していない重要な情報)を安全に活用できるようになる。
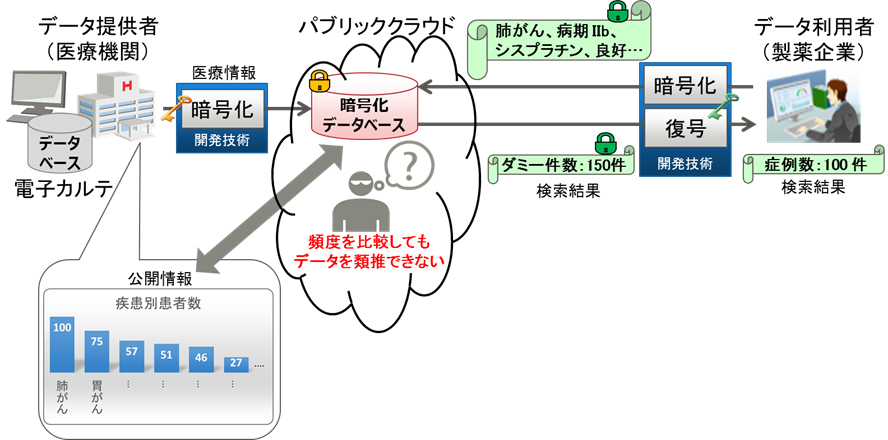 図1:検索結果にダミーデータを混ぜることで、検索結果の件数からデータや検索内容を類推されてしまう問題を解決する(出典:富士通研究所)
図1:検索結果にダミーデータを混ぜることで、検索結果の件数からデータや検索内容を類推されてしまう問題を解決する(出典:富士通研究所)拡大画像表示
背景について同社は、暗号化されたデータベースでも、公開された統計情報などと比較することによって、登録数の一致などから元データを推定されてしまう問題を挙げる。「例えば、医療分野の場合、公的機関や医療機関が公開している病名や医薬品などの統計情報と、データベースに登録されている件数を突き合わせることで、データの内容を類推できてしまう。データベースの内容が類推できてしまうと、検索文字列が暗号化されていても、検索結果から利用者が何を検索したのかも推定できてしまう」(同社)。
「データや検索文字列を類推できる問題への対策としては、これまでも、データベースにダミーデータを追加する技術があった。データベースに登録されているデータの真の件数が把握できなくなるため、元データを類推できなくなるという仕掛けである。しかし、一般的なやり方では、もっとも件数が多い項目にあわせる形でダミーデータを追加していくため、最大件数とデータの種類に応じて、データベースに登録されるデータ量が数百倍以上に増加してしまい、実用的ではなかった」(同社)。
富士通研究所は今回、ダミーデータの追加という手法を採用しつつも、実用的なデータ量の増加で済むようにした。グループ内の要素の数が均一になるように、グループごとに最小限の数のダミーデータを作成する。例えば、病名・医薬品・血液型といったデータの項目ごとにグループを作り、そのグループごとにダミーデータを入れる。各グループ(血液型)の要素(A型、B型、O型、AB型)の数がそれぞれ均一になるようにダミーデータを登録していく。それぞれの要素がデータベース上ではすべて同じ数で出現するため、類推できなくなる。
実際に、富士通研究所は、開発した技術を活用し、2000項目で構成する診察記録10億件をデータベースに登録した。この結果、データ量の増加を元データの9倍以内に抑えながら、統計情報と登録数が一致しないためにデータや検索内容を類推できない状態で照合できることを確認した。
「開発した技術を医療分野に活用すれば、電子カルテなど機密情報をクラウド上で共有し、登録情報や検索内容を秘匿したまま、製薬会社がデータベースの登録数を照合できる。また、医療分野に限らず、公共分野におけるデータを基にした自治体の街づくりや、金融分野の顧客データのマーケティングなどに応用できる」(同社)。
富士通研究所は今後、データの匿名化技術やプライバシーリスクの評価技術など、富士通や富士通研究所のセキュリティ技術と組み合わせて提供していく。まずは、医療分野でデータ活用の実証実験から検証を進め、2020年度までに医療情報のデータ利活用サービスを実用化する。



- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
