NECは2022年5月17日、自社の数百人のAI研究者が利用するAI研究用スーパーコンピュータを、数十億円を投じて設計・構築すると発表した。2023年3月に、580PFLOPS(1PFLOPSで浮動小数点演算を1秒間に1000兆回)超のシステムを稼働させる。既に一部のシステム(100PFLOPS)については、同社の数百人のAI研究者が利用を始めている。
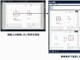
NECは、自社の数百人のAI研究者が利用するAI研究用スーパーコンピュータを、数十億円を投じて設計・構築する(写真1)。2023年3月に、580PFLOPS(1PFLOPSで浮動小数点演算を1秒間に1000兆回)超のシステムを稼働させる。すでに一部のシステム(100PFLOPS)については、同社の数百人のAI研究者が利用を始めている。
 写真1:NECが2023年3月に稼働させる580PFLOPS超のAI研究用スーパーコンピュータのイメージ(出典:NEC)
写真1:NECが2023年3月に稼働させる580PFLOPS超のAI研究用スーパーコンピュータのイメージ(出典:NEC) システムは、GPUサーバーとストレージで構成。GPUサーバーは、1ノードあたり8基のGPU「NVIDIA A100 80GB Tensor コア GPU」を搭載したサーバー(米Super Micro Computer製)116台で構成する。ストレージは、並列ファイルシステム型ストレージソフトウェア「EXAScaler」(米DataDirect Networks製)を搭載したストレージアプライアンスで、容量16PB超を用意する。
理論上の処理性能は、580PFLOPSを超える。数千万枚の画像を数分間で学習可能としている。ネットワークには、Ethernetスイッチ「NVIDIA Spectrum SN3700」を採用。全サーバーを200Gbit/sのEthernetで接続し、RoCE(RDMA over Converged Ethernet) v2によって高速・低遅延で通信する。これにより、複数サーバーにまたがった分散学習を高速化する。
ミドルウェア面では、コンテナ運用基盤のKubernetesを中核とした独自のシステム構築技術を採用。ハードウェアとソフトウェア群を密に結合することで、高性能かつ利便性の高いシステムを実現するとしている。
NEC / スーパーコンピュータ / HPC / Kubernetes / Supermicro


- 業務システム 2027年4月強制適用へ待ったなし、施行迫る「新リース会計基準」対応の勘所【IT Leaders特別編集版】
- 生成AI/AIエージェント 成否のカギは「データ基盤」に─生成AI時代のデータマネジメント【IT Leaders特別編集号】
- フィジカルAI AI/ロボット─Society 5.0に向けた社会実装が広がる【DIGITAL X/IT Leaders特別編集号】
- メールセキュリティ 導入のみならず運用時の“ポリシー上げ”が肝心[DMARC導入&運用の極意]【IT Leaders特別編集号】
- ゼロトラスト戦略 ランサムウェア、AI詐欺…最新脅威に抗するデジタル免疫力を![前提のゼロトラスト、不断のサイバーハイジーン]【IT Leaders特別編集号】
-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

AIの真価は「今この瞬間」の感知にある。「Data Streaming Platform」で実現する「AI Ready Data」を解説
-

-

-

VDIの導入コストを抑制! コストコンシャスなエンタープライズクラスの仮想デスクトップ「Parallels RAS」とは
-

AI時代の“基幹インフラ”へ──NEC・NOT A HOTEL・DeNAが語るZoomを核にしたコミュニケーション変革とAI活用法
-

加速するZoomの進化、エージェント型AIでコミュニケーションの全領域を変革─「Zoom主催リアルイベント Zoomtopia On the Road Japan」レポート
-

14年ぶりに到来したチャンスをどう活かす?企業価値向上とセキュリティ強化・運用効率化をもたらす自社だけの“ドメイン”とは
-

-

-

-

生成AIからAgentic AIへ―HCLSoftware CRO Rajiv Shesh氏に聞く、企業価値創造の課題に応える「X-D-Oフレームワーク」
-

-

-

「プラグアンドゲイン・アプローチ」がプロセス変革のゲームチェンジャー。業務プロセスの持続的な改善を後押しする「SAP Signavio」
-

BPMとプロセスマイニングで継続的なプロセス改善を行う仕組みを構築、NTTデータ イントラマートがすすめる変革のアプローチ
-
